主要使用的就是两个存储引擎,分别是InnoDB和MyISAM。
InnoDB
- InnoDB是MySQL的默认存储引擎。
- InnoDB采用MVCC来支持高并发,并且实现了四个标准的隔离级别。默认的隔离级别是可重复读。通过间隙锁策略防止幻读的出现。
- InnoDB表是基于聚簇索引建立的。聚簇索引对主键查询有很高的性能。
- InnoDB内部做了很多优化。包括从磁盘读取数据时采用可预测性预读,能够自动在内存中创建Hash索引以加速读操作的自适应哈希索引,以及能够加速插入操作的插入缓冲区等。
MyISAM
- MyISAM提供了大量的特性,包括全文索引、压缩、空间函数等,但MyISAM不支持事务和行级锁。
- 在MyISAM表,可以基于其前500个字符创建索引。MyISAM也支持全文索引,这是一种基于分词创建但索引,支持复杂但查询。
- MyISAM引擎设计简单,数据以紧密格式存储,在某些场景下,性能很好。
InnoDB和MyISAM区别
是否支持事务
InnoDB支持事务
对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin transaction和commit之间,组成一个事务;
MyISAM不支持,
支持锁的级别不同
InnoDB支持行锁
注意:数据库的主键和索引对锁是有影响的。
在使用for update的时候,在明确使用主键或者索引的时候才会是行锁,否则就是表锁。
MyISAM只支持表锁
是否支持外键
InnoDB支持外键
MyISAM不支持。
4. 存放索引的方式
InnoDB是聚集索引,
数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。
因此,主键不应该过大,因为主键太大,其他索引也都会很大。
MyISAM是非聚集索引,数据文件是分离的,
索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
查询具体行数的差异
InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。
MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
是否支持全文索引
Innodb不支持全文索引(innodb引擎在5.6.4版本提供了对全文索引的支持)
MyISAM支持全文索引,查询效率上MyISAM要高于Innodb;
二、事务的并发问题
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
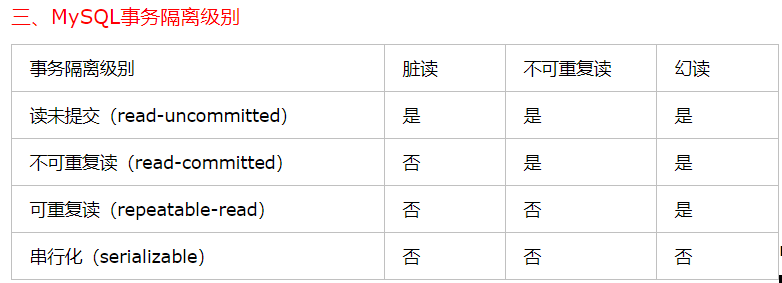
数据库的四种事务级别:
隔离级别
在SQL标准中定义了四种隔离级别,每一种级别都规定了一个事务中所做都修改,哪些事务内都事务内和事务间是可见都,哪些是不可见都。较低级别都隔离通常可以执行更高都并发,系统的开销也更低。
未提交读 (脏读)
在该级别中,事务中的修改,即使没有提交,对其他事务也都是可见的,事务可以读取未提交的数据,这也被成为脏读。这个级别是最低级别,性能上是最好的,但是缺乏其他级别的很多好处,在实际应用中一般很少使用。
提交读(不可重复读)
已提交读是指一个事务开始时,只能看见已经提交的事务所做的修改。换句话说,一个事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的。这个级别有时候也叫不可重复读,因为两次执行同样的查询,可 能会得到不一样的结果。
可重复读
该级别是MySQL的默认事务级别。他解决了脏读的问题。该级别保证了在同一个事务中多次读取同样记录的结果是一致的。但是可重复读还是无法解决幻读问题。
串行化
串行化是最高隔离级别。它通过强制事务串行执行,避免了幻读问题。简单的说,串行化会在读取的每一行数据上都加锁。故而会导致大量的超时和锁争用问题,增大系统开销。
三:多版本并发控制(MVCC)
MVCC是行级锁的一个变种。它在很多情况下避免了加锁操作,所以开销更低。同样的,实现了非阻塞的读操作,但写操作也只锁定必的行。
MVCC的实现是通过保存数据在某个时间点的快照来实现的。不管需要执行多长时间,每个事务看到的数据都是一致的。根据事务开始的时间不同,每个事务对同一张表,同一时刻看到的数据可能是不一样的。
InnoDB的MVCC是通过在每行记录的后面保存两个隐藏列来实现。这两个列,一个是保存行的创建时间,一个是保存行的过期时间。存储都是系统版本号。每开始一个新的事务,系统版本号都会自动递增。事务开始时刻的版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。
MVCC可以解决在可重复读隔离级别下的幻读问题。实现方式就是通过两个隐藏列实现的。通过版本号,使幻读问题不在发生。
但MVCC只在可重复读和提交读两个级别下工作。因为未提交读总是读取最新的数据行,而不是符合当前事务版本的数据行。
四:索引
MySQL中索引主要有B-Tree索引,Hash索引,R-Tree索引,全文索引
B-Tree索引
- 如果没有特别指明类型,那大多数谈索引都是B—Tree索引。它使用B-Tree数据结构来存储索引。其中,主要用的还是InnoDB中,使用的是B+Tree。
先谈二叉树,它是一种树形数据结构,正如它的名字一样,每个分支都是两个。其中有个实现,平衡二叉树,它的特点就是左子树的值永远比根节点小,右子树永远比根节点大。于是它又有了一个变种,B树,它和平衡二叉树的特点一样,但不同但是B树是一颗多叉树又名平衡多路查找树。它的分支不止是两个,使得树的高度变得更低。但它的存储的值全在节点上,导致查找效率不是那么高。所以,它的升级版,B+树来了。
B+树是B树的一个升级版,相对于B树来说B+树更充分的利用了节点的空间,让查询速度更加稳定,其速度完全接近于二分法查找。它存储值的位置和B树不同的是,它的存储的位置全在叶子节点,所以使得B+树的查找效率更高,层级也更矮。
另外再来篇文章 https://www.cnblogs.com/leefreeman/p/8315844.html
问题:InnoDB一棵B+树可以存放多少行数据? 答案上面的链接。
哈希索引
哈希索引是基于哈希表实现的。只有精确匹配索引所有列的查询才有效。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希玛。哈希玛是一个较小的值,并且不同键值的行计算出来的哈希玛也不一样。哈希索引将所有的哈希玛存储在索引中,同时在哈希表中保存指向每个数据行的指针。
比如在存储地址URL的时候,这个时候用哈希索引就比用B-Tree索引效果好,因为URL地址的长度一般都很长,如果使用B—Tree索引存储,会使节点中的值变长,使索引的内存空间更大。但使用哈希索引,将url字符串计算出一个哈希玛,会让索引占用内存空间小。
R-Tree索引
即空间索引,在MySQL中很少使用,可以用作地理数据存储。
全文索引
它查找的是文本中的关键词,而不是直接比较索引中的值。在相同的列上同时创建全文索引和基于值的B-Tree索引不会有冲突。
五:SQL优化
查看我之前做的笔记 explain