给出一棵包含 (n) 个点的树,点带权。
有 (Q) 次询问,每次询问给出两个点 (x) 和 (y),求 (x) 到 (y) 的简单路径上,任意选择若干个点,使得其点权异或和最大。
(1 leq n leq 2 imes 10^4),(1 leq Q leq 2 imes 10^5),(0 leq g_i leq 2^{60})。
前置知识:树上倍增,线性基。
首先我们知道线性基是可以暴力合并的,即把线性基 (b) 的元素一个个地插入线性基 (a) 中。定义 ( ext{merge}) 运算合并两个线性基,显然 ( ext{merge}) 运算的复杂度是 (mathcal{O(log^2 n)}) 的。
考虑树上倍增。设 (f_{i, j}) 表示节点 (i) 向上跳 (2^j) 步所到达的节点编号,设 (g_{i, j}) 表示节点 (i) 向上跳 (2^j) 步所经过的所有节点(不包括节点 (i))的点权所组成的线性基。则有:
通过简单的 BFS 即可预处理出 (f) 与 (g)。
询问也按照倍增求 ( ext{lca}) 的框架,令 (x, y) 向上跳,(x, y) 每向上移动一段路径,就合并该路径对应的线性基。
至此我们有一个 (mathcal{O(n log^3 n) - O(log^3 n)}) 的做法。
这个做法还不够优秀,考虑挖掘线性基合并的一些性质。
有一个树上倍增的 trick:
若一个运算满足 (a oplus a = a),则我们称这个运算满足 " 可重复贡献 " 性。
例如 (max)、(min)、(gcd) 等运算均满足 " 可重复贡献 " 性。
考虑 (x) 到 (y) 之间的路径,记 (z = ext{lca}(x, y))。
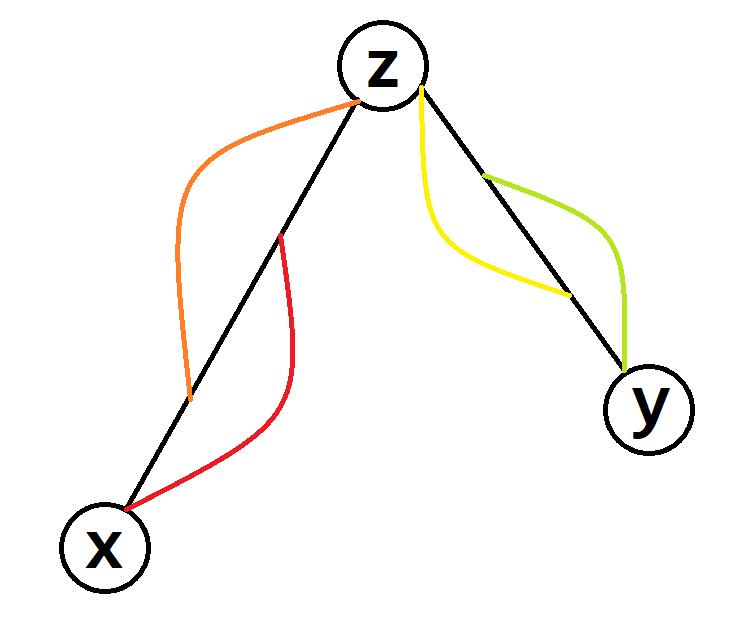
我们将 (x) 到 (y) 的路径分成了 ({color{red}红路径})、 ({color{orange}橙路径})、 ({color{yellow}黄路径})、 ({color{green}绿路径}) 四部分,每一部分的长度都是不超过 " 所在大路径的长度 " 的 (2) 的最大整数次幂(({color{red}红路径}) 和 ({color{orange}橙路径}) 归在 (x) 到 (z) 的大路径里,({color{yellow}黄路径}) 和 ({color{green}绿路径}) 归在 (y) 到 (z) 的大路径里),每一部分的贡献都可以通过倍增数组求出,故答案为 ({color{red}红路径贡献} oplus {color{orange}橙路径贡献} oplus {color{yellow}黄路径贡献} oplus {color{green}绿路径贡献})。
设 (oplus) 运算的复杂度为 (mathcal{O(w)}),若配合 " 长链剖分求树上 (k) 级祖先 " 以及 " tarjan 求 ( ext{lca}) ",即可 (mathcal{O(w)}) 回答询问。
回到此题,注意到线性基合并也是满足 " 可重复贡献 " 性的。具体的说:若线性基 (a) 与线性基 (b) 所代表的路径之间有交集,则线性基 (a) 与线性基 (b) 经过 ( ext{merge}) 运算后所得到的线性基代表的路径为线性基 (a) 与线性基 (b) 所代表的路径的并集。因为交集部分的元素在重复插入线性基的时候显然不会多做贡献。

于是套用上述 trick 即可将复杂度优化至 (mathcal{O(n log^3 n) - O(log^2 n)})。
注意到 ( ext{merge}) 操作的复杂度为 (mathcal{O(log^2 n)}),所以我们还是可以用树上倍增来求 " 树上 (k) 级祖先 " 以及 " ( ext{lca}) "。
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <queue>
using namespace std;
const int N = 20100, M = 40100;
int logx[N];
int n, m;
long long val[N];
int tot, head[N], ver[M], Next[M];
void add(int u, int v) {
ver[++ tot] = v; Next[tot] = head[u]; head[u] = tot;
}
struct bas {
long long p[64];
bas() {
for (int i = 0; i <= 63; i ++)
p[i] = 0;
}
};
long long calc(bas a) {
long long ans = 0;
for (int i = 63; i >= 0; i --)
if ((ans ^ a.p[i]) > ans) ans ^= a.p[i];
return ans;
}
bas operator + (bas a, long long x) {
for (int i = 63; i >= 0; i --) {
if (!(x >> i)) continue;
if (!a.p[i]) { a.p[i] = x; break; }
else x ^= a.p[i];
}
return a;
}
bas operator + (bas a, bas b) {
for (int i = 63; i >= 0; i --)
if (b.p[i]) a = a + b.p[i];
return a;
}
int d[N];
int f[N][20];
bas g[N][20];
void bfs() {
queue<int> q;
q.push(1), d[1] = 1;
while (q.size()) {
int u = q.front(); q.pop();
for (int i = head[u]; i; i = Next[i]) {
int v = ver[i];
if (d[v]) continue;
d[v] = d[u] + 1;
f[v][0] = u;
g[v][0] = g[v][0] + val[u];
for (int j = 1; j <= 19; j ++) {
f[v][j] = f[f[v][j - 1]][j - 1];
if (f[v][j]) g[v][j] = g[v][j - 1] + g[f[v][j - 1]][j - 1];
}
q.push(v);
}
}
}
int lca(int x, int y) {
if (d[x] > d[y]) swap(x, y);
for (int i = 19; i >= 0; i --)
if (d[x] <= d[f[y][i]]) y = f[y][i];
if (x == y) return x;
for (int i = 19; i >= 0; i --)
if (f[x][i] != f[y][i]) x = f[x][i], y = f[y][i];
return f[x][0];
}
int jump(int x, int lv) {
for (int i = 19; i >= 0; i --)
if (lv >> i & 1) x = f[x][i];
return x;
}
long long ask(int x, int y) {
bas ans;
ans = ans + val[x];
ans = ans + val[y];
int L = lca(x, y);
if (d[x] - d[L] >= 1) {
int lv = logx[d[x] - d[L]];
ans = ans + g[x][lv];
ans = ans + g[jump(x, d[x] - d[L] - (1 << lv))][lv];
} if (d[y] - d[L] >= 1) {
int lv = logx[d[y] - d[L]];
ans = ans + g[y][lv];
ans = ans + g[jump(y, d[y] - d[L] - (1 << lv))][lv];
}
return calc(ans);
}
int main() {
logx[0] = -1;
for (int i = 1; i <= 20000; i ++)
logx[i] = logx[i / 2] + 1;
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i ++)
scanf("%lld", &val[i]);
for (int i = 1, u, v; i < n; i ++) {
scanf("%d%d", &u, &v);
add(u, v), add(v, u);
}
bfs();
while (m --) {
int x, y; scanf("%d%d", &x, &y);
printf("%lld
", ask(x, y));
}
return 0;
}