一个很强的科学计算库

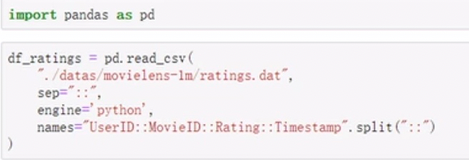
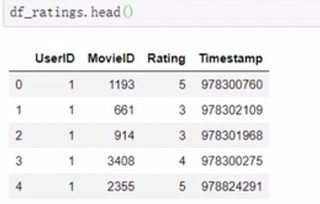
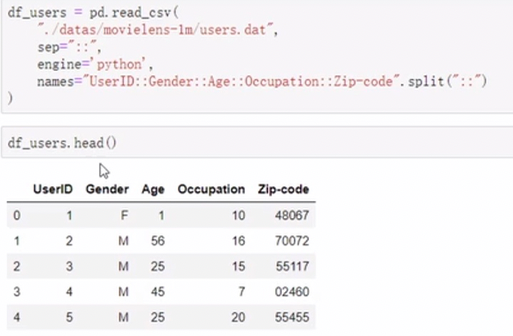
import pandas as pd
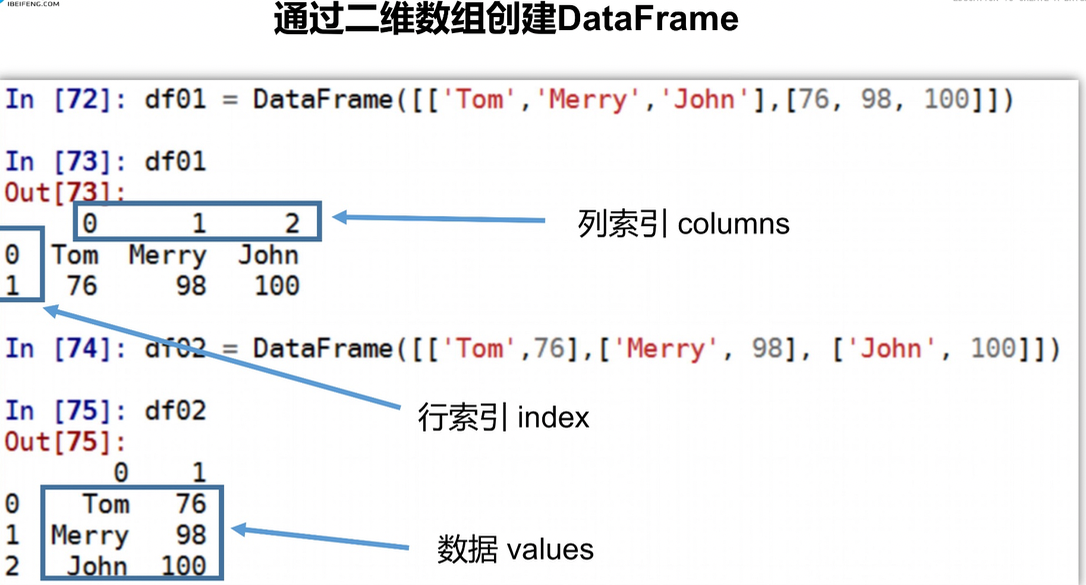
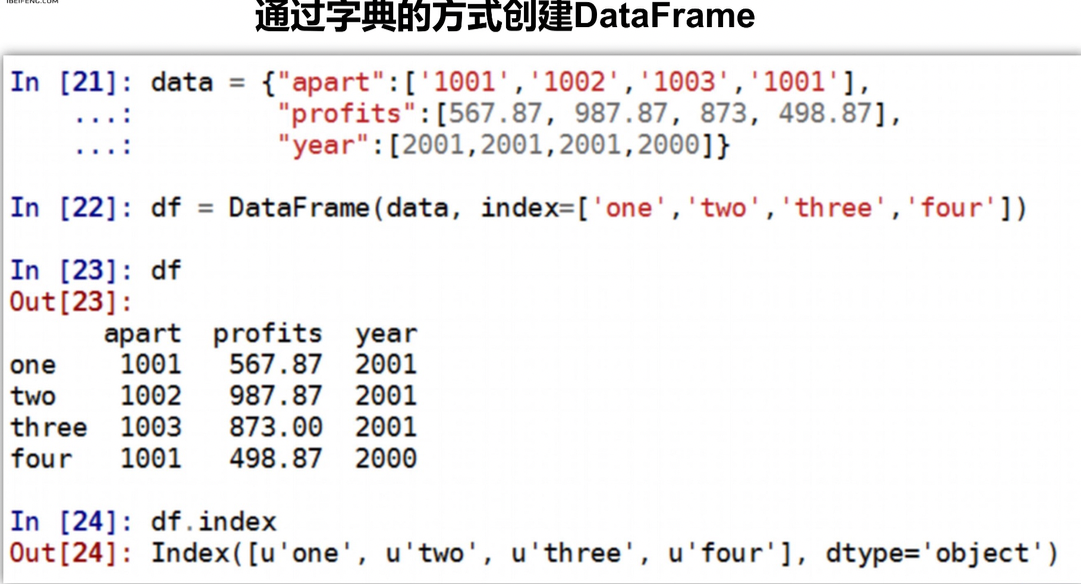
创建dataframe



DataFrame运算



Pandas画图
DataFrame.plot(x=None, y=None, kind='line')

文件读取与存储

缺失值的处理

数据离散化




表格处理
准备好表格数据,直接使用
df
主机名 IP 监控项 最新值
0 Sdata-server 127.0.0.1 CPU 使用率 14.6985
1 大上的拉数据活动即可 122.28.169.245 CPU 使用率 1.1704
2 大系统平台-测试主机 122.196.112.143 CPU 使用率 24.2978
df.to_excel(file_path,
sheet_name="Sheet1",
na_rep="",
float_format=None,
columns=None,
header=True,
index=True,
index_label=None,
startrow=0,
startcol=0,
engine=None,
merge_cells=True,
encoding=None,
inf_rep="inf",
verbose=True,
freeze_panes=None) #index=False 可以删除默认的列索引,
pandas应用
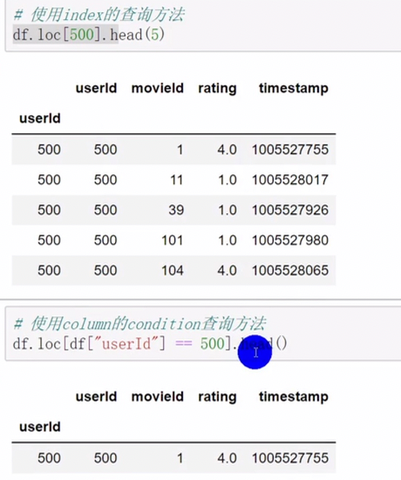
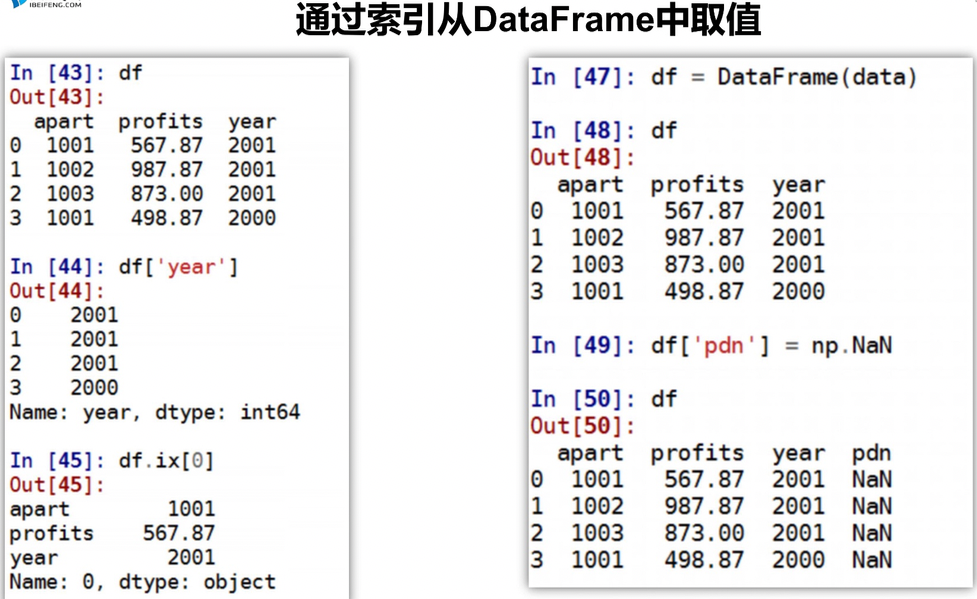
pandas查询数据

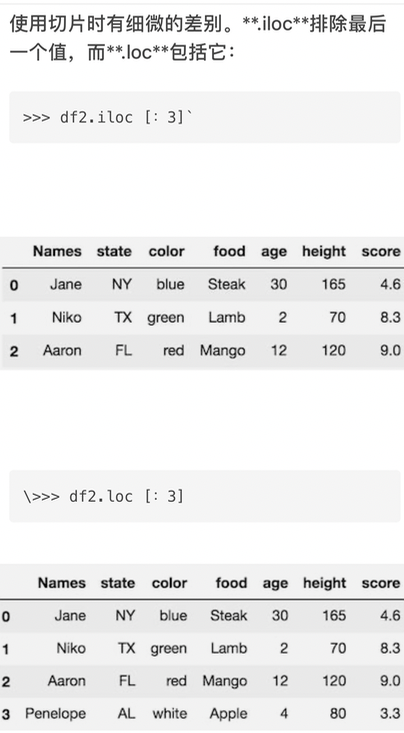
df.loc查询

数据


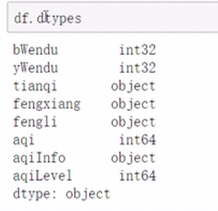
查看类型
-
单label

指定位置取值取到的是个值,指定位置切片取到的是个series -
批量查询
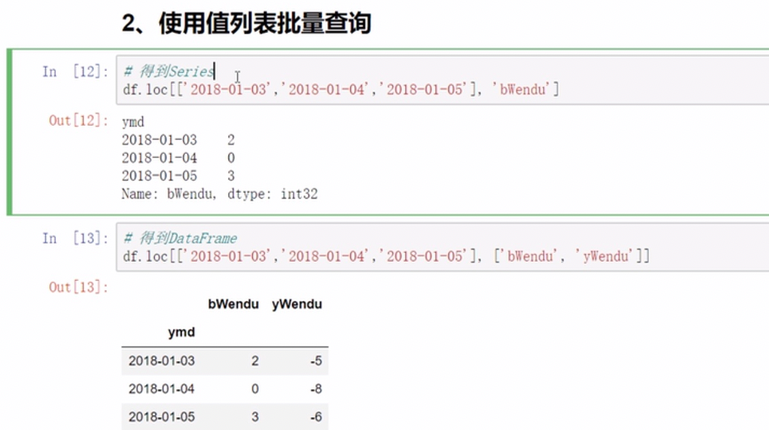
注意取到的结果对象是有区别的 -
区间查询

可以切片取值, -
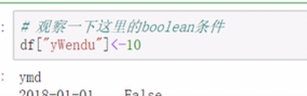
条件表达式查询
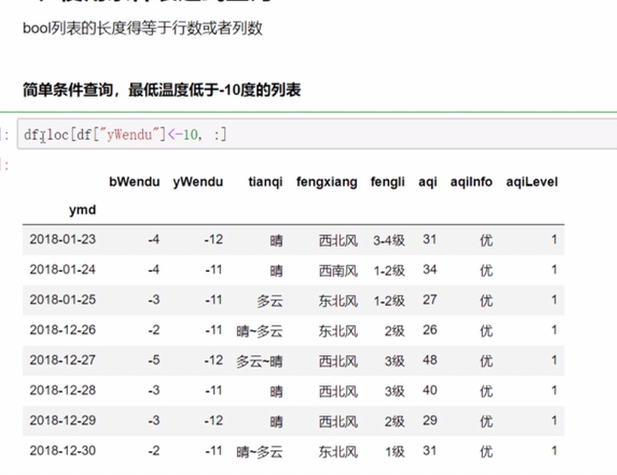
返回的是一串bool值
多条件可组合
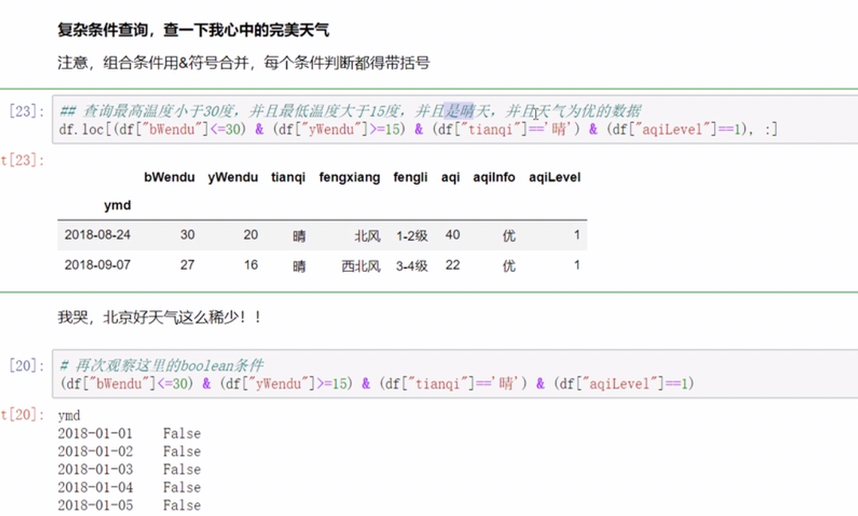
- 调用函数查询
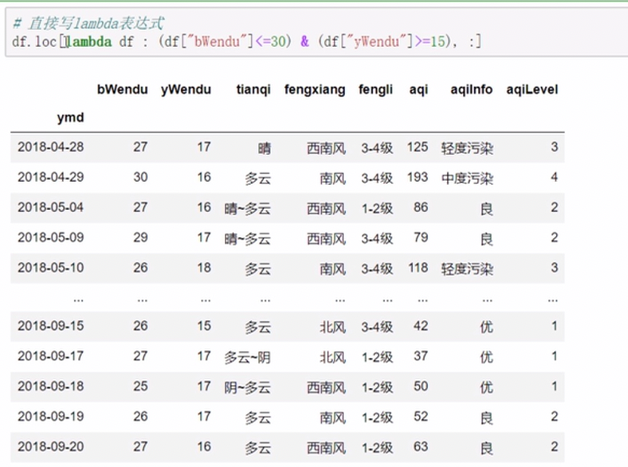
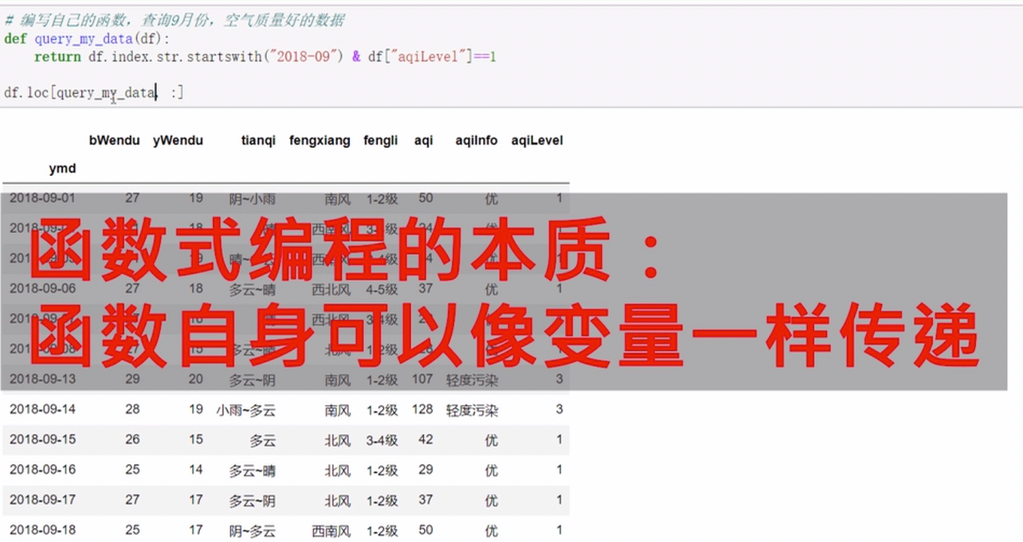
可以使用lambda函数或者直接定义一个函数
传递函数,
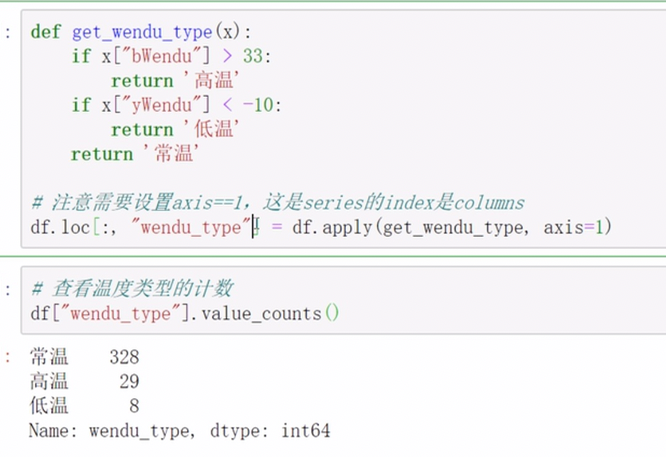
数据列的新增
大致方法

直接新增一列,给定一个新的列明及其值

apply对于函数的调用

assign

按照条件分组赋值

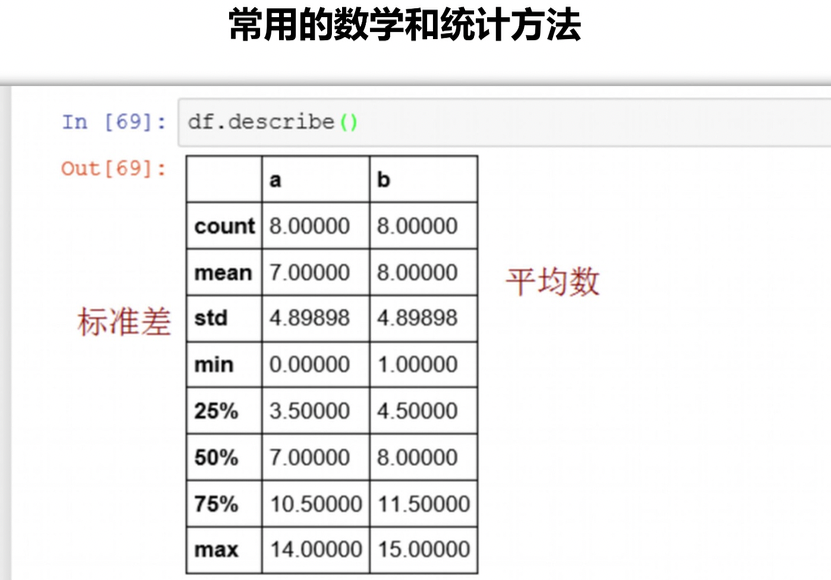
数据统计函数

describe()
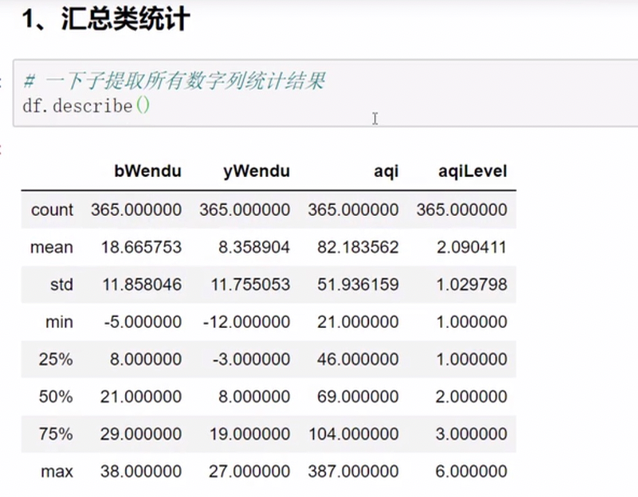
mean() max() min()

唯一去重和按值计数


相关系数 协方差

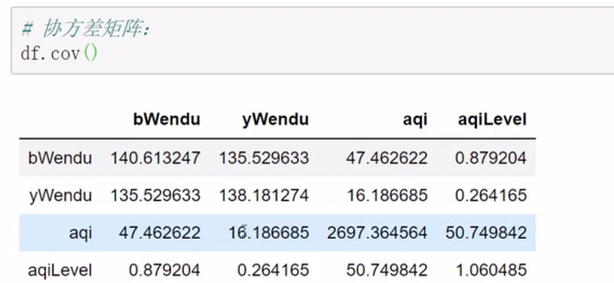
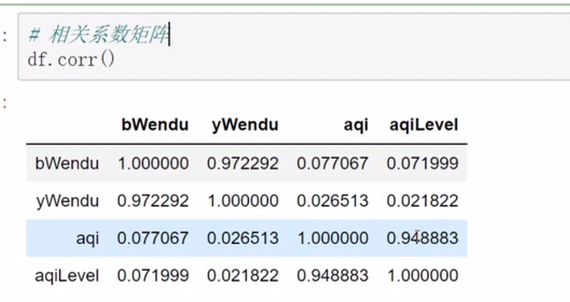
各因素相关性

pandas读取文件操作
原文件
处理后
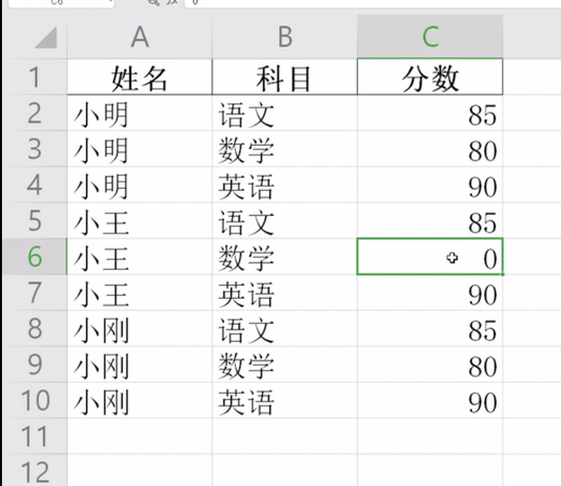
pandas对缺失值的处理

读取原文件
skiprows 跳过的行,将空数据跳过

原始数据
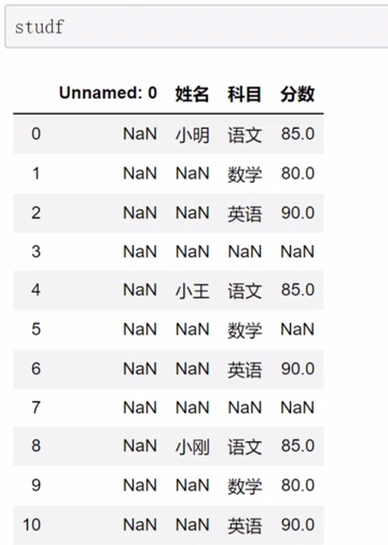
空值检测
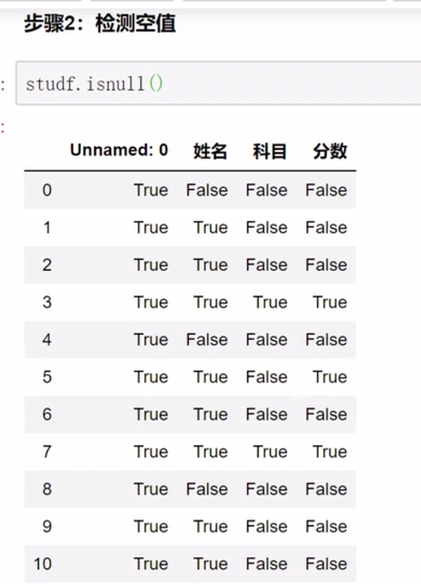
对某一列的空值检测

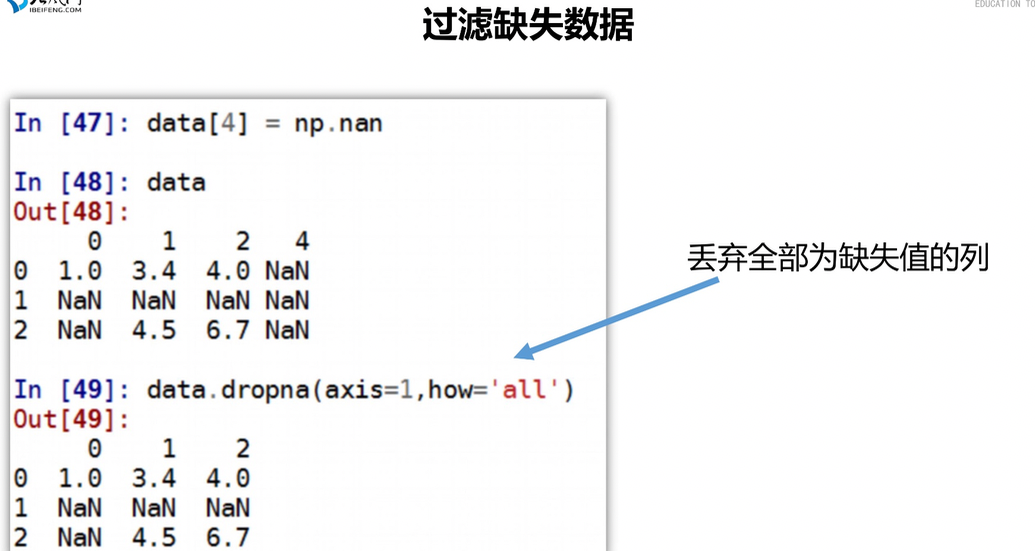
删除全是空值的列 how指定方式,all为所有都空再删,any表示任意空即删,inplace表示返回的对象是否为新对象

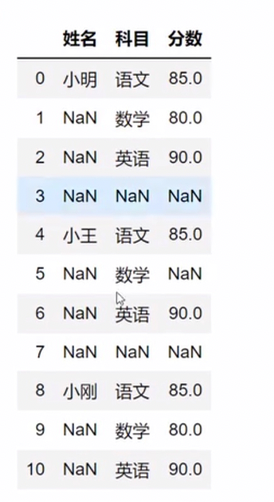
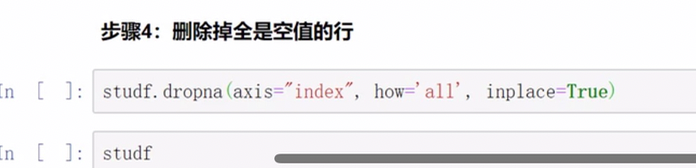
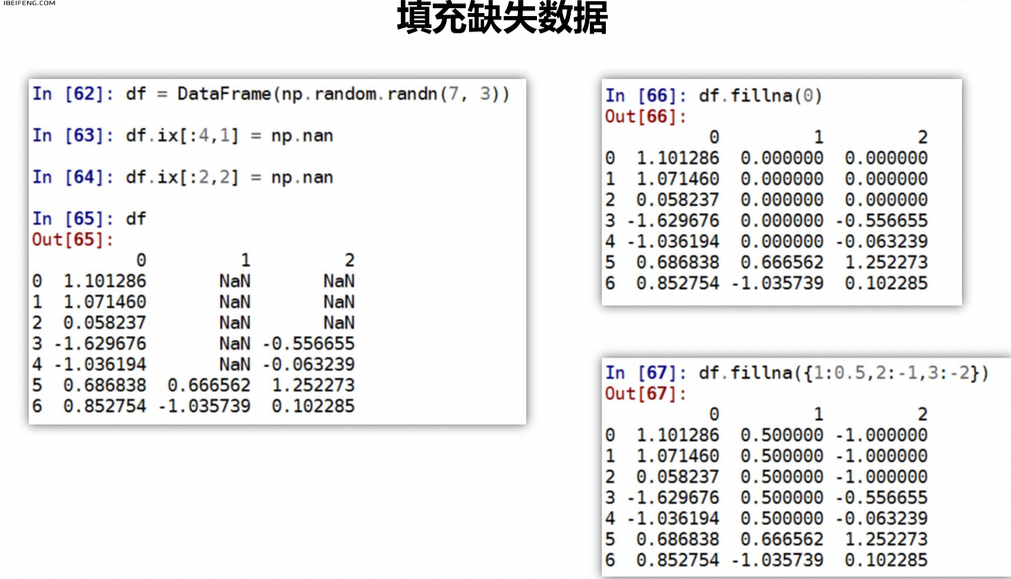
空值填充
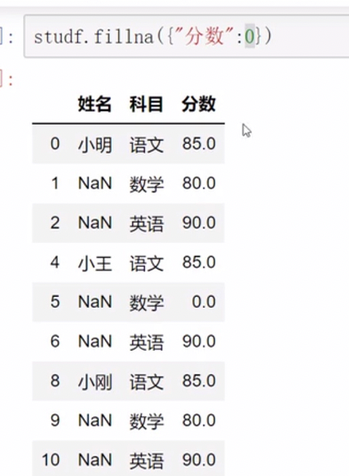

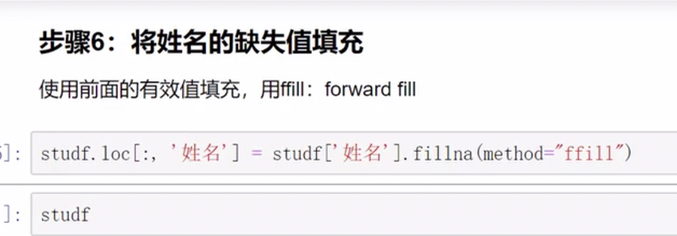
名称填充 ,method指定是跟前面/后面的数据为准进行填充

pandas的SettingWithCopyWarning报警

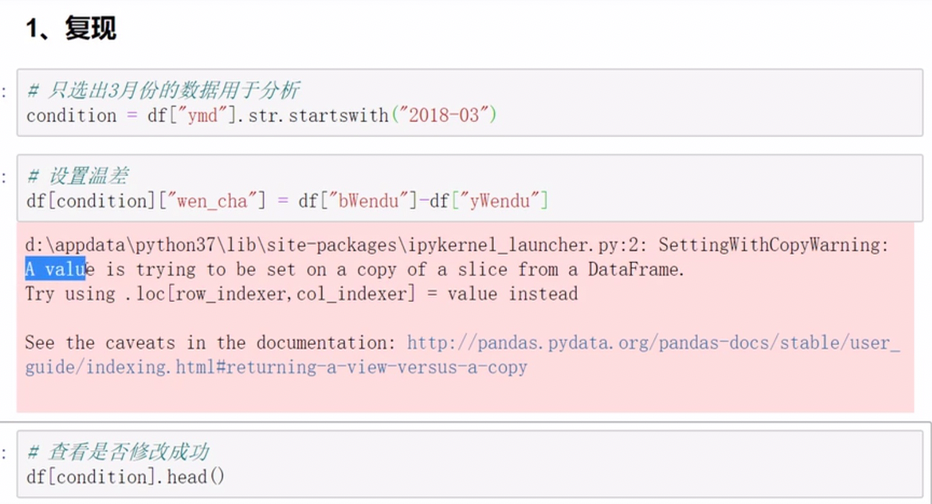
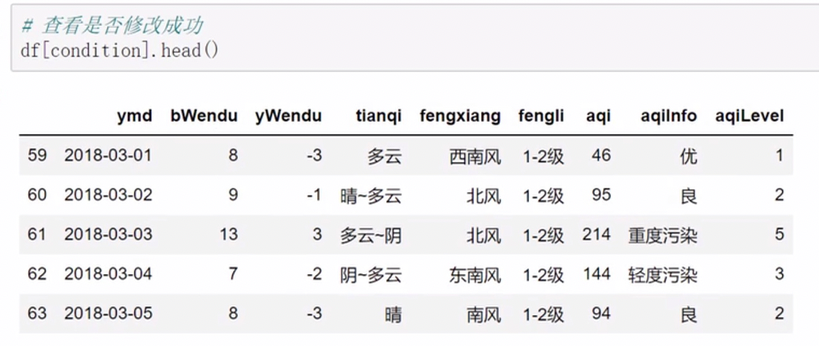



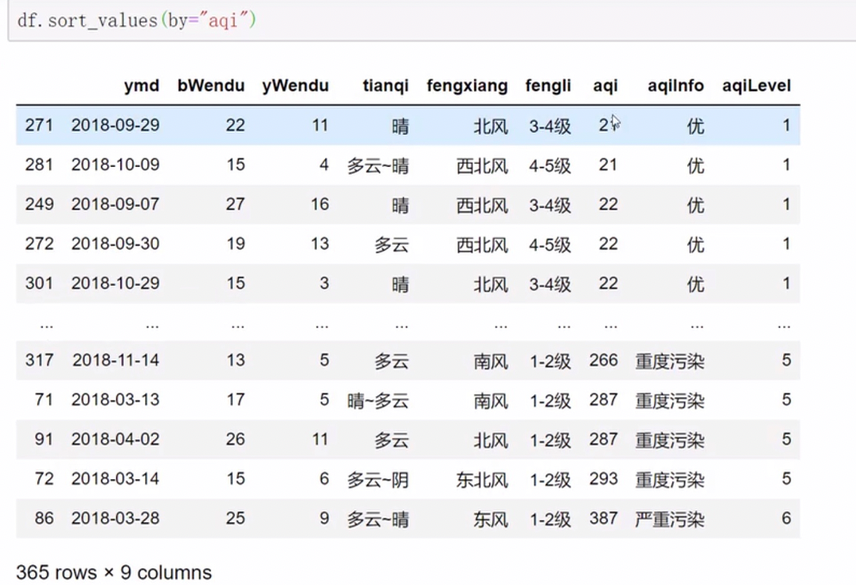
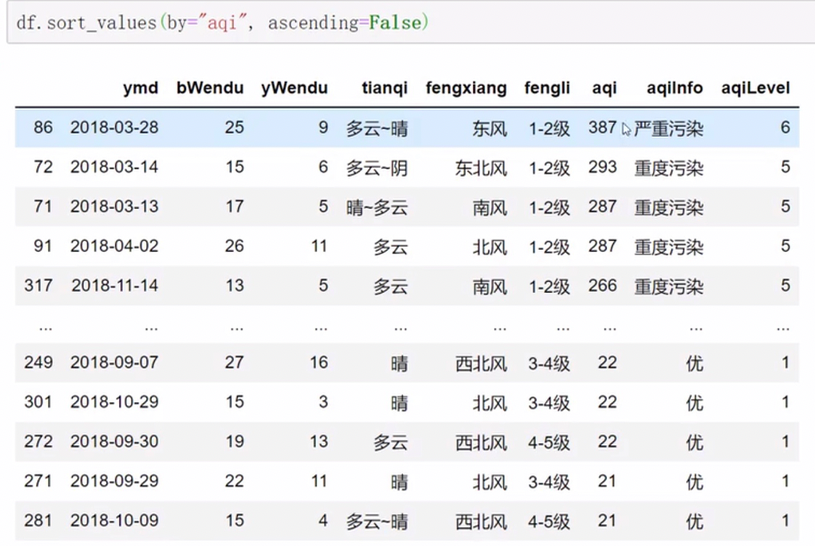
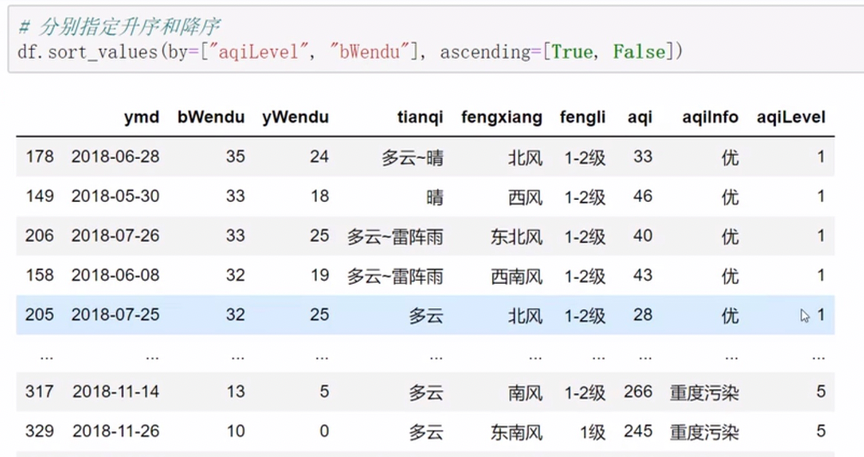
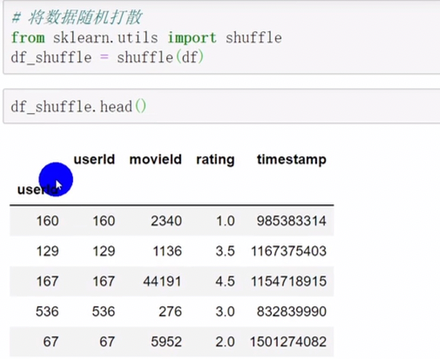
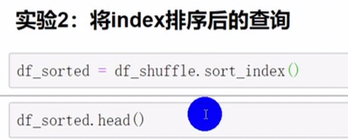
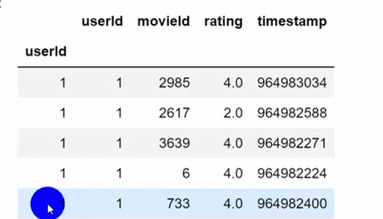
pandas排序

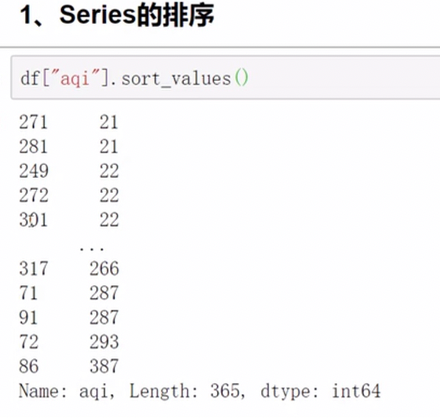

中文也可以



pandas字符串处理




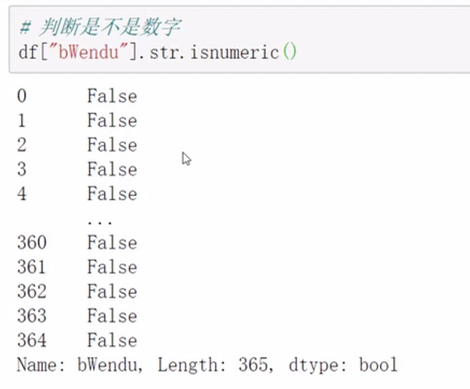
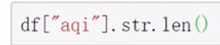
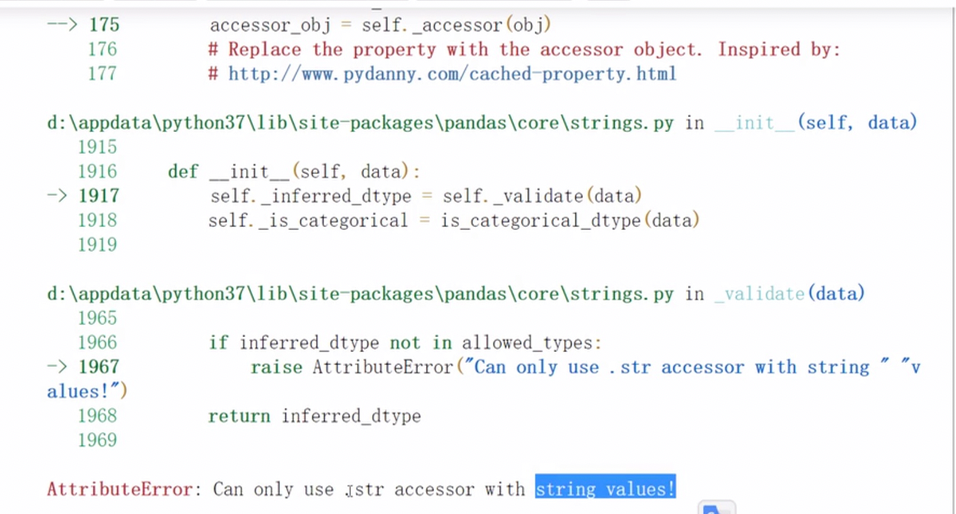
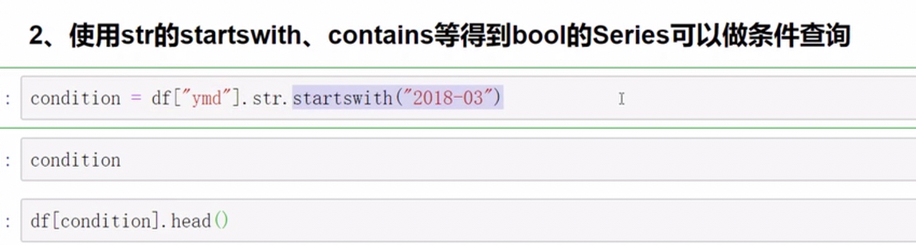
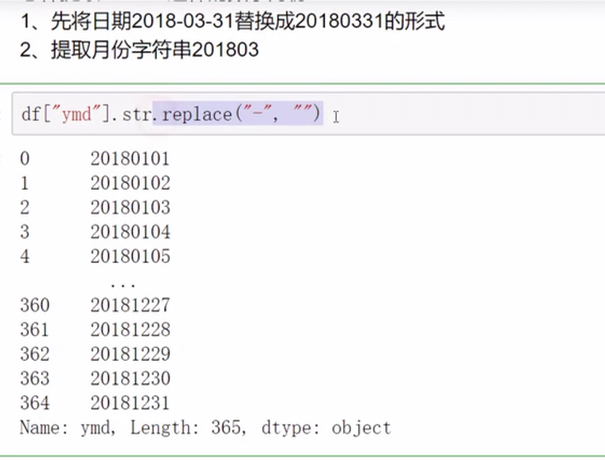
字符串方法只能用于字符串上
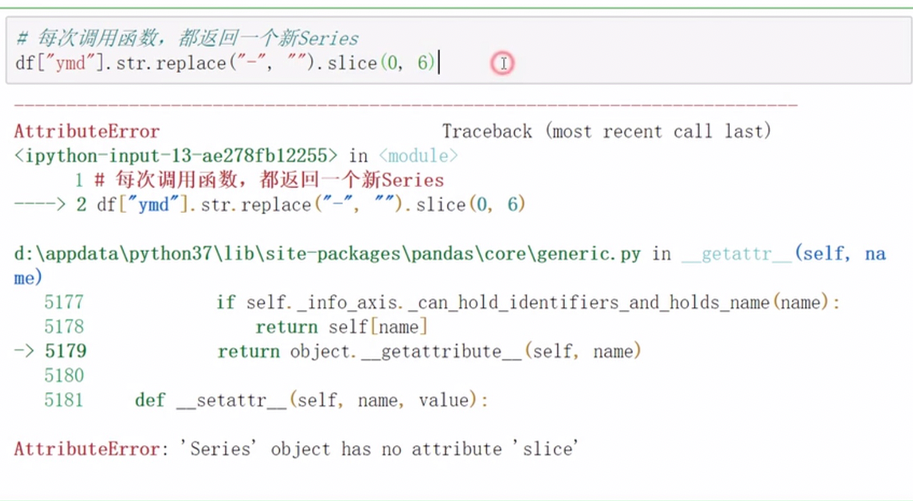


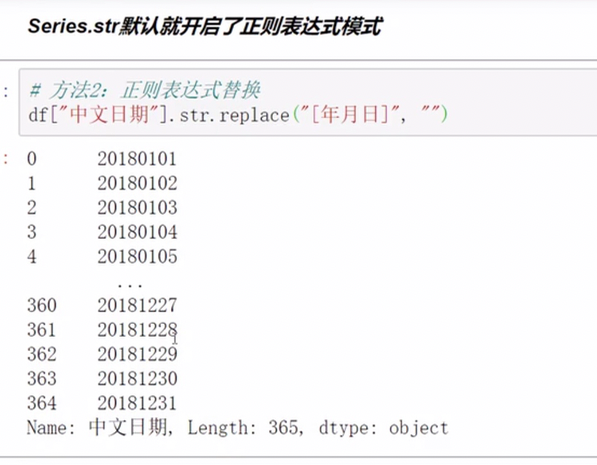
正则处理

匹配中括号中的任意一个即为成功
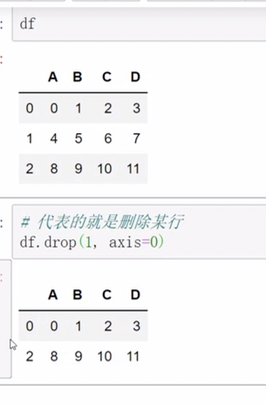
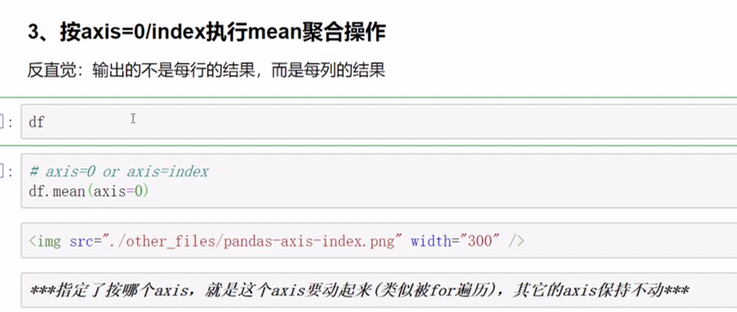
pandas中axis参数的理解




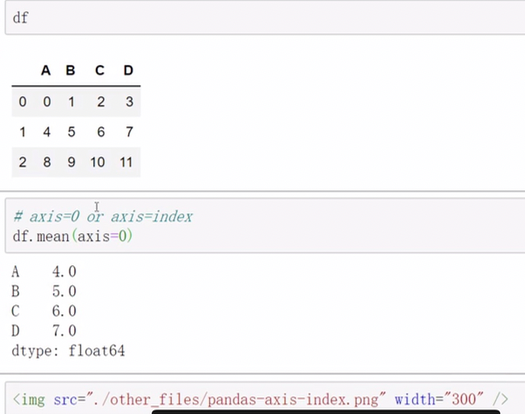

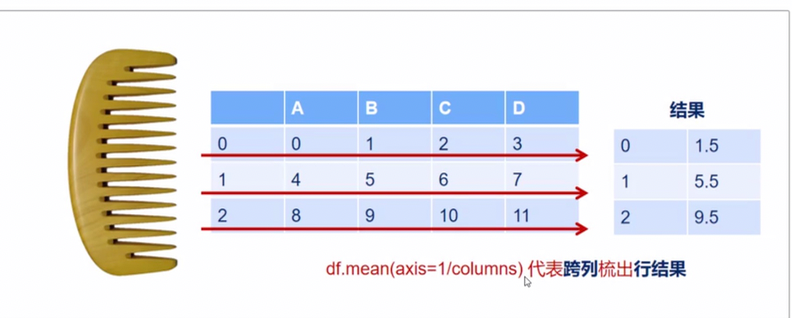
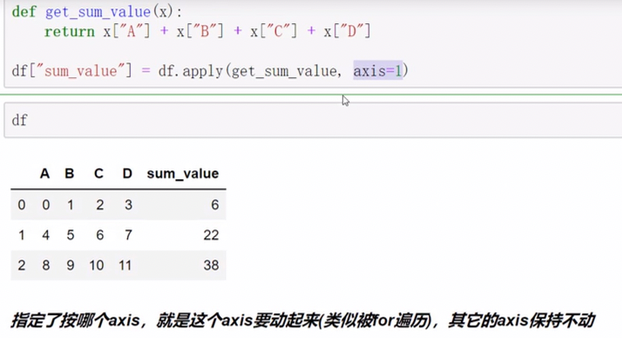
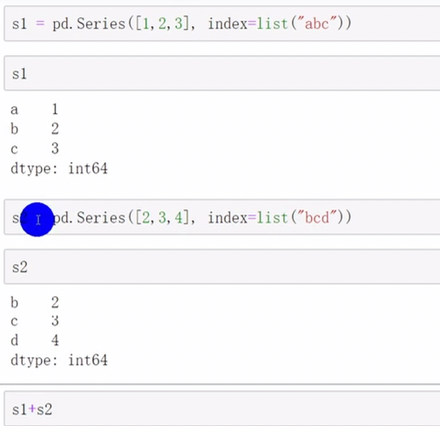
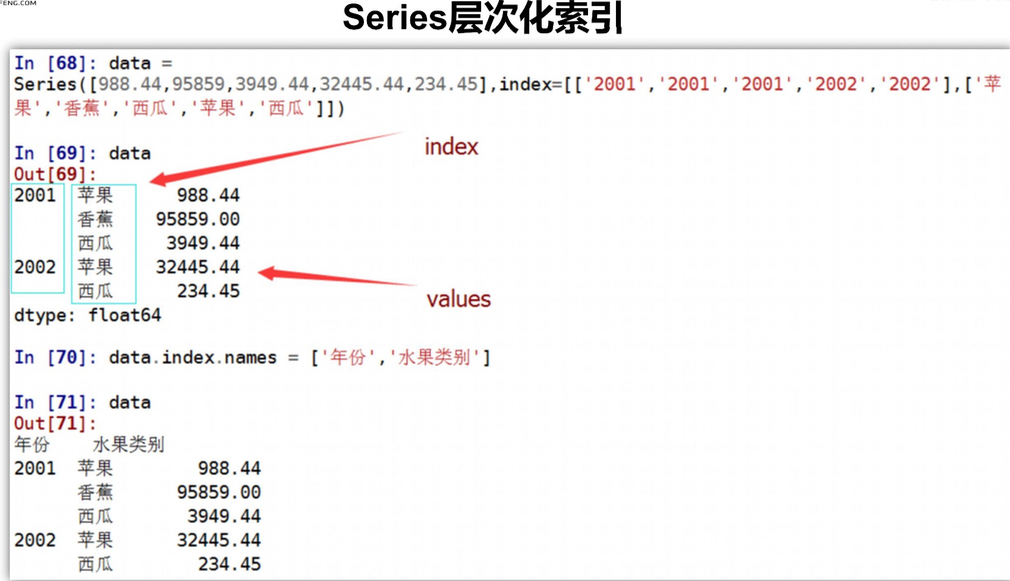
index用途







自动对齐数据


merge

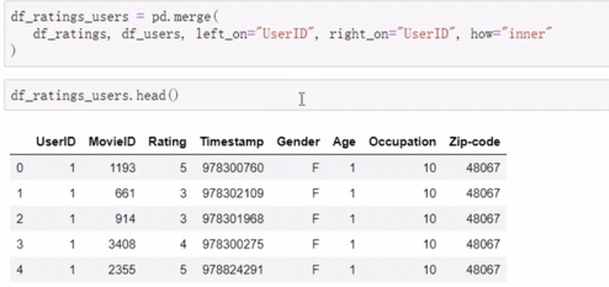
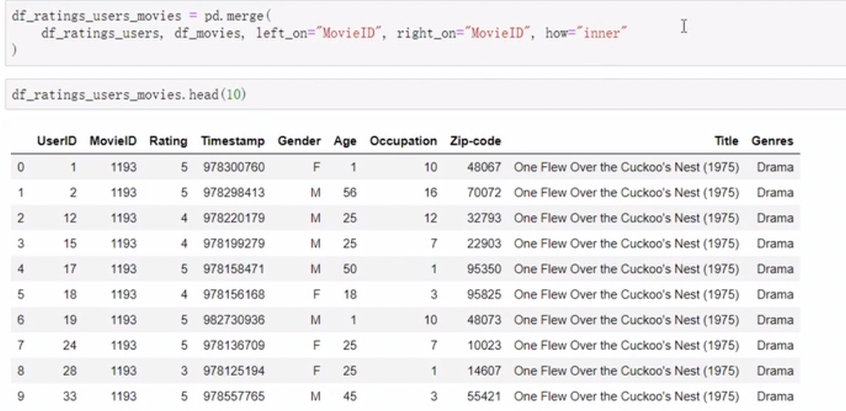

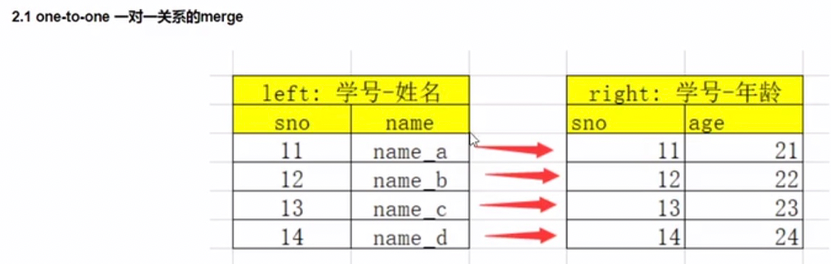
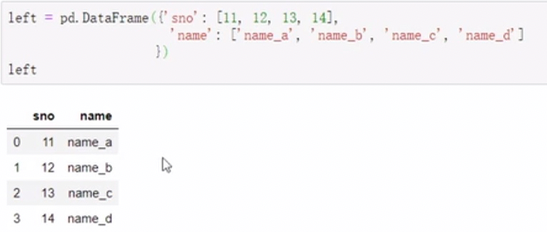

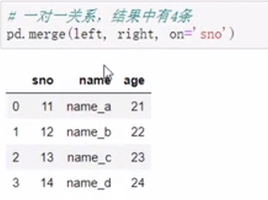
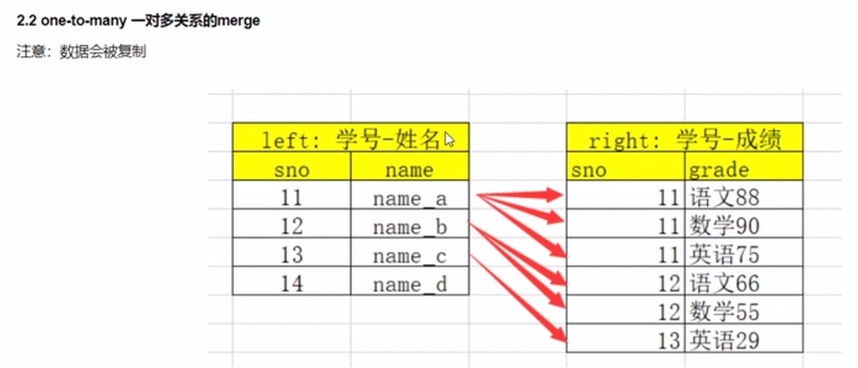


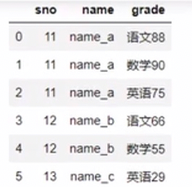
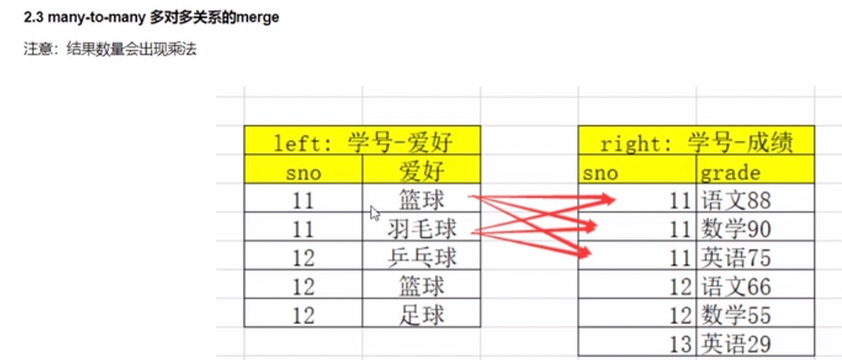



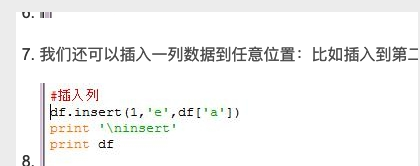
移动列


pd去重

pandas对触发器的方法解析
trigger_args = {
'templateids': '',
'output': ['description', 'priority', 'expression', 'status'],
'selectItems': ['name', 'key_', 'value_type', 'delay', 'status'],
'selectFunctions': 'extend',
''
'expandDescription': True,
'expandExcpression': True,
}
item_args = {
'templated': True, 'selectApplications': ['name'],
'output': ['name', 'value_type', 'type', 'delay', 'status'],
'templateids': '',
'with_triggers': False
}
def analysis_function(df):
function_df = df['functions']
items_df = df['items']
func_tri_merge = []
for idx, expression in enumerate(df['expression']):
func_tmp = pd.DataFrame(function_df[idx])
item_tmp = pd.DataFrame(items_df[idx])
tmp = pd.merge(func_tmp, item_tmp, on=['itemid']).loc[:,['functionid','name','function','parameter','itemid','triggerid','value_type','delay','status']]
func_tri_merge.append(tmp)
for index in tmp.index:
function_id, item_name, function, function_parameter = tmp.loc[index][:4]
df['expression'][idx] = df['expression'][idx].replace('{{{}}}'.format(function_id),'{}.{}({})'.format(item_name, function,
function_parameter))
return func_tri_merge
def merge_triger(df,tri_df):
ret = []
sub_set = []
for i in df['triggerid']:
if isinstance(i,str):
ret.append(tri_df[tri_df['triggerid']==i]['description'].values[0])
else:
sub_set = []
for j in i:
sub_set.append(tri_df[tri_df['triggerid']==j]['description'].values[0])
ret.append(','.join(sub_set))
df['trigger_info'] = ret
# templateid=10172
templateid=10462
trigger_args.update({'templateids': templateid})
item_args.update({'templateids': templateid})
trigger_protos = api.triggerprototype.get(**trigger_args)
triggers = api.trigger.get(**trigger_args)
tri_data = triggers + trigger_protos
tri_df = pd.DataFrame(tri_data)
# 获取需要合并ret_df = ret_df.reset_index(drop=True)+的监控项信息和处理完expression的tri_df
concat_data = analysis_function(tri_df)
concat_df = pd.concat(concat_data)
# concat_df = concat_df.groupby('name').agg(np.unique).reset_index()
# merge_triger(concat_df,tri_df)
# 删除重复的监控项
# concat_df.drop_duplicates(subset=['name', 'itemid'], keep='first', inplace=True)
# concat_df = concat_df.loc[:, ['triggerid', 'itemid', 'name', 'value_type', 'delay', 'status','trigger_info']]
concat_df = concat_df.loc[:, ['triggerid', 'itemid', 'name', 'value_type', 'delay', 'status']]
tri_df = tri_df.loc[:, ['triggerid', 'priority', 'expression', 'status','description']]
tri_merge = pd.merge(concat_df, tri_df, on=['triggerid'], how='outer')
try:
tri_merge = tri_merge.groupby(['itemid','name']).agg(np.unique).reset_index()
except Exception as e:
tri_merge = tri_merge.groupby('name').agg(np.unique).reset_index()
# 重新构造索引
# concat_df = concat_df.reset_index(drop=True)
# concat_df.drop('itemid', axis=1, inplace=True)
# 获取未被触发器使用的监控项
item_protos = api.itemprototype.get(**item_args)
items = api.item.get(**item_args)
item_data = item_protos + items
if item_data:
item_df = pd.DataFrame(item_data)
print(tri_merge,tri_merge.columns)
df1 = tri_merge.loc[:,['itemid','name', 'value_type', 'delay', 'status_x', 'description', 'expression','priority','status_y']]
df1.columns = ['itemid','name','value_type','delay','status','description','expression','priority','trigger_status']
df2 = item_df.loc[:, ['itemid', 'name', 'value_type', 'delay', 'status', ]]
ret_df = pd.concat([df1,df2])
ret_df.drop_duplicates(subset=['name', 'itemid'], keep='first', inplace=True)
# ret_df.drop('itemid',axis=1,inplace=True)
ret_df = ret_df.reset_index(drop=True)
else:
print(tri_merge,tri_merge.columns)
df1 = tri_merge.loc[:,['itemid','name', 'value_type', 'delay', 'status_x', 'description', 'expression','priority','status_y']]
df1.columns = ['itemid','name','value_type','delay','status','description','expression','priority','trigger_status']
ret.append(ret_df)
处理模板基线
# def _tmp(self, series):
# ret = []
# for i in series:
# ret.append(i['name'])
# return ','.join(ret)
#
# def _trigger(self, series, property):
# ret = []
# for i in series:
# if property == 'priority':
# ret.append(ALERT_MAP[i[property]])
# else:
# ret.append(i[property])
# return ','.join(ret)
#
# def _analysis_function(self, df):
# function_df = df['functions']
# items_df = df['items']
#
# func_tri_merge = []
# for idx, expression in enumerate(df['expression']):
# func_tmp = pd.DataFrame(function_df[idx])
# item_tmp = pd.DataFrame(items_df[idx])
# tmp = pd.merge(func_tmp, item_tmp, on=['itemid']).loc[:,
# ['functionid','name','function','parameter','itemid','triggerid','value_type','delay','status']]
# func_tri_merge.append(tmp)
# for index in tmp.index:
# function_id, item_name, function, function_parameter = tmp.loc[index][:4]
# df['expression'][idx] = df['expression'][idx].replace('{{{}}}'.format(function_id),
# '{}.{}({})'.format(item_name, function,
# function_parameter))
# return func_tri_merge
# def get_template_info_pd(self, key_=None, group_id=None, name=None, parent_key=None):
# """
# 获取监控系统当前模板的监控项,触发器的信息
# :param key_:
# :param group_id:
# :param name:
# :param parent_key:
# :return: list[str,df] [模板名称,模板监控明细的df对象]
# """
# res_df = []
# templates = self.api.template.get(selectHosts=['name'], output=['name'])
# trigger_args = {
# 'templateids': '',
# 'output': ['description', 'priority', 'expression', 'status'],
# 'selectItems': ['name', 'key_', 'value_type', 'delay', 'status'],
# 'selectFunctions': 'extend',
# 'expandDescription': True,
# 'expandExcpression': True,
# }
# item_args = {
# 'templated': True, 'selectApplications': ['name'],
# 'output': ['name', 'value_type', 'type', 'delay', 'status'],
# 'templateids': '',
# 'with_triggers': False
# }
# for template in templates:
# trigger_args.update({'templateids': template['templateid']})
# item_args.update({'templateids': template['templateid']})
#
# trigger_protos = self.api.triggerprototype.get(**trigger_args)
# triggers = self.api.trigger.get(**trigger_args)
# tri_data = triggers + trigger_protos
# tri_df = pd.DataFrame(tri_data)
# # 获取需要合并的监控项信息和处理完expression的tri_df
# concat_data = self._analysis_function(tri_df)
# concat_df = pd.concat(concat_data)
# # 删除重复的监控项
# concat_df = concat_df.loc[:, ['triggerid', 'itemid', 'name', 'value_type', 'delay', 'status']]
# tri_df = tri_df.loc[:, ['triggerid', 'priority', 'expression', 'status', 'description']]
# # concat_df.drop_duplicates(subset=['name', 'itemid'], keep='first', inplace=True)
# # concat_df = concat_df.loc[:, ['triggerid', 'itemid', 'name', 'value_type', 'delay', 'status']]
# # tri_df = tri_df.loc[:, ['triggerid', 'description', 'priority', 'expression', 'status']]
# # tri_merge = pd.merge(concat_df, tri_df, on=['triggerid'], how='outer')
# tri_merge = pd.merge(concat_df, tri_df, on=['triggerid'], how='outer')
# tri_merge = tri_merge.groupby('name').agg(np.unique).reset_index()
# # 重新构造索引
# # concat_df.drop('itemid', axis=1, inplace=True)
#
# # 获取未被触发器使用的监控项
# item_protos = self.api.itemprototype.get(**item_args)
# items = self.api.item.get(**item_args)
# item_data = item_protos + items
# item_df = pd.DataFrame(item_data)
# try:
# df1 = tri_merge.loc[:,['itemid', 'name', 'value_type', 'delay', 'status_x', 'description', 'expression', 'priority','status_y']]
# except Exception as e:
# print()
# print(tri_merge)
# df1.columns = ['itemid', 'name', 'value_type', 'delay', 'status', 'description', 'expression', 'priority','trigger_status']
# df2 = item_df.loc[:, ['itemid', 'name', 'value_type', 'delay', 'status', ]]
# ret_df = pd.concat([df1, df2])
# ret_df.drop_duplicates(subset=['name', 'itemid'], keep='first', inplace=True)
# ret_df.drop('itemid',axis=1,inplace=True)
# ret_df = ret_df.reset_index(drop=True)
# res_df.append(ret_df)
# if data:
# df = pd.DataFrame(data)
# df['application'] = df['applications'].apply(self._tmp) if isinstance(df.get('applications'),
# Series) else None
# df['value_type'] = df['value_type'].apply(lambda x: VALUE_MAP[x]) if isinstance(df.get('value_type'),
# Series) else None
# if isinstance(df.get('triggers'), Series):
# df['description'] = df['triggers'].apply(self._trigger, args=('description',))
# df['priority'] = df['triggers'].apply(self._trigger, args=('priority',))
# df['expression'] = df['triggers'].apply(self._trigger, args=('expression',))
# df['trigger_status'] = df['triggers'].apply(self._trigger, args=('status',))
# else:
# df['description'] = None
# df['priority'] = None
# df['expression'] = None
# df['trigger_status'] = None
#
# df = df.loc[:,
# ['name', 'delay', 'value_type', 'status', 'application', 'description', 'expression', 'priority',
# 'trigger_status']]
# res_df.append([template['name'].replace('Template', 'Tpl')[:31], df])
# else:
# continue
# return res_df
二次学习














聚合

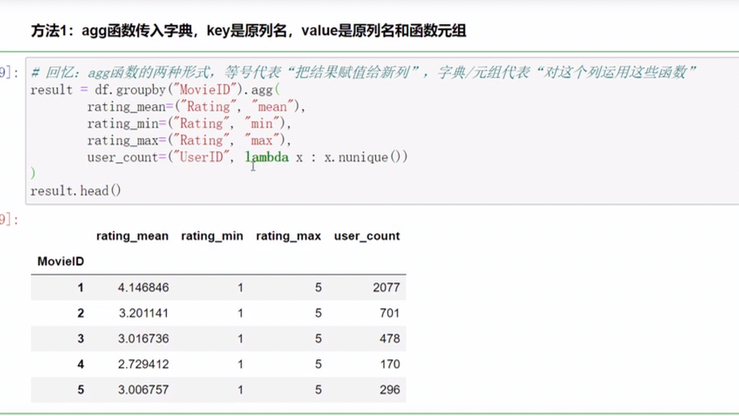


apply
今天以df去apply 用series的时候 指定了series.name(源数据中有这个字段)
不能这么用,会跟pandas原生的series.name冲突 展示index值,需要使用['name']来取值