1.mixup原理介绍
mixup 论文地址
mixup是一种非常规的数据增强方法,一个和数据无关的简单数据增强原则,其以线性插值的方式来构建新的训练样本和标签。最终对标签的处理如下公式所示,这很简单但对于增强策略来说又很不一般。
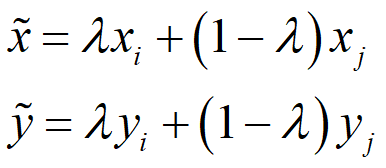

,两个数据对是原始数据集中的训练样本对(训练样本和其对应的标签)。其中是一个服从B分布的参数,
。Beta分布的概率密度函数如下图所示,其中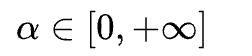
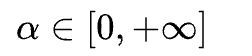
因此,α 是一个超参数,随着α的增大,网络的训练误差就会增加,而其泛化能力会随之增强。而当 α→∞ 时,模型就会退化成最原始的训练策略。
2.mixup的代码实现
如下代码所示,实现mixup数据增强很简单,其实我个人认为这就是一种抑制过拟合的策略,增加了一些扰动,从而提升了模型的泛化能力。
def get_batch(x, y, step, batch_size, alpha=0.2):
"""
get batch data
:param x: training data
:param y: one-hot label
:param step: step
:param batch_size: batch size
:param alpha: hyper-parameter α, default as 0.2
:return:
"""
candidates_data, candidates_label = x, y
offset = (step * batch_size) % (candidates_data.shape[0] - batch_size)
# get batch data
train_features_batch = candidates_data[offset:(offset + batch_size)]
train_labels_batch = candidates_label[offset:(offset + batch_size)]
# 最原始的训练方式
if alpha == 0:
return train_features_batch, train_labels_batch
# mixup增强后的训练方式
if alpha > 0:
weight = np.random.beta(alpha, alpha, batch_size)
x_weight = weight.reshape(batch_size, 1, 1, 1)
y_weight = weight.reshape(batch_size, 1)
index = np.random.permutation(batch_size)
x1, x2 = train_features_batch, train_features_batch[index]
x = x1 * x_weight + x2 * (1 - x_weight)
y1, y2 = train_labels_batch, train_labels_batch[index]
y = y1 * y_weight + y2 * (1 - y_weight)
return x, y
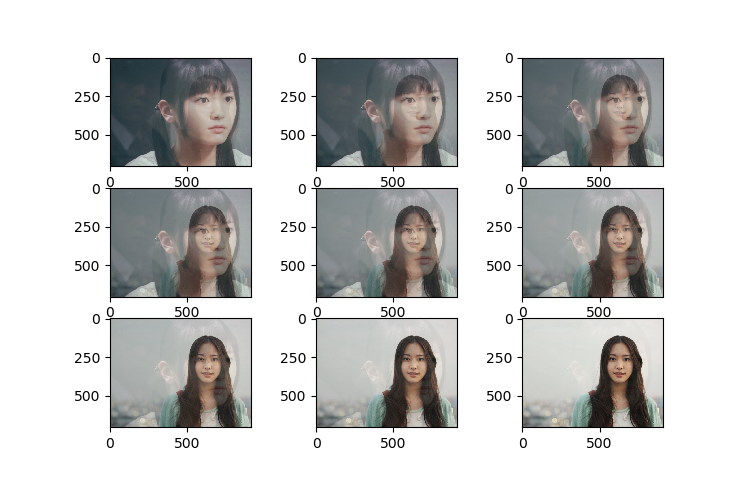
3.mixup增强效果展示
import matplotlib.pyplot as plt
import matplotlib.image as Image
import numpy as np
im1 = Image.imread(r"C:UsersDaisyDesktop1xyjy.png")
im2 = Image.imread(r"C:UsersDaisyDesktop1xyjy2.png")
for i in range(1,10):
lam= i*0.1
im_mixup = (im1*lam+im2*(1-lam))
plt.subplot(3,3,i)
plt.imshow(im_mixup)
plt.show()
————————————————————
后来又发现一篇好文:https://www.zhihu.com/question/308572298?sort=created