本文源码:GitHub·点这里 || GitEE·点这里
一、分布式故障
分布式系统的架构,业务开发,这些在良好的思路和设计文档规范之下,是相对来说好处理的,这里的相对是指比较分布式架构下生产环境的突然故障。
在实际的开发中,有这样一个很妖娆的情况:越是核心复杂的业务,越是担心出问题,越容易出问题。
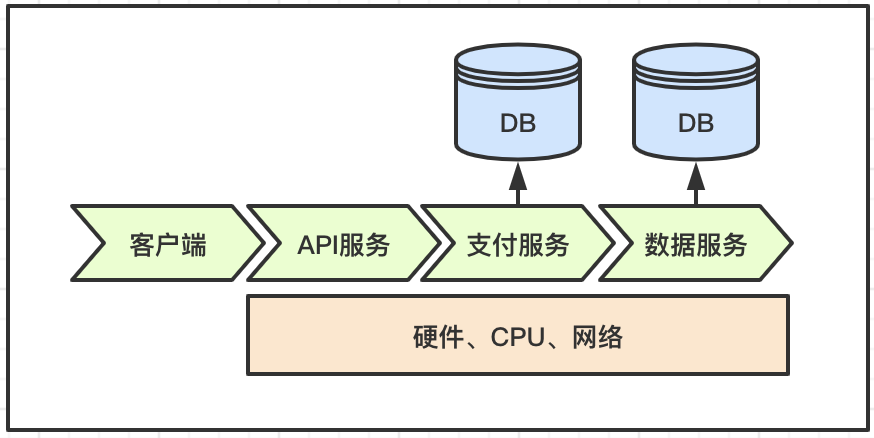
所以当核心服务的链路出现故障时,如何快速定位问题就是一件很头疼的事情,尤其是一些特殊情况下,问题很模糊很难复现,外加客户或者领导催促,这种场景心里阴影是大部分开发都有的。更有甚者,可能问题发生的切入点的开发是某人负责的,实际问题是发生在请求链路的其他服务上,这种情况遇多了,甩锅水平会直线上升。
越是复杂的系统,越是经验丰富的开发或者运维,对监控系统就越是有执念,尤其是全链路的监控,底层,网络,中间件,服务链路,日志观察预警等,用来快速定位问题,省时省心。
二、全链路监控
1、监控层次
在分布式系统中,需要监控的体系和层次极其复杂,通常整体上划分为三个层次:应用服务,软件服务,硬件服务。
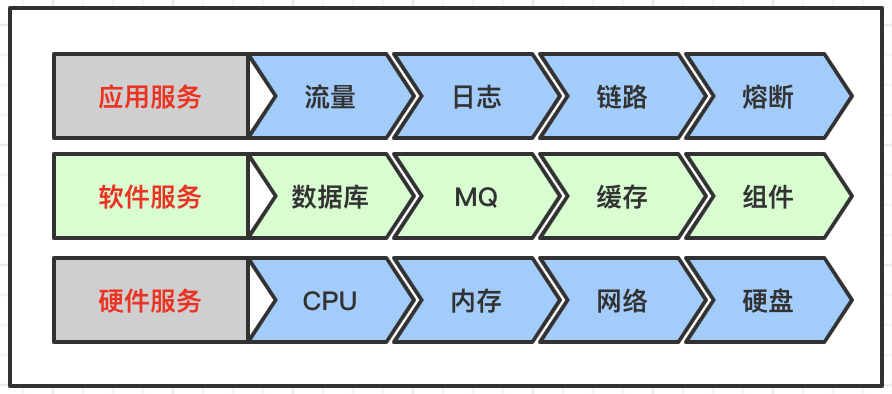
通常情况,运维管理硬件服务,开发管理应用和软件服务。
2、应用服务
应用层为开发的业务逻辑服务,也是最容易突发问题的一个层面,当在一家公司待久了,因为开发过多个业务线,就会感觉自己不是开发,是个打杂的,每天都要分出大量时间处理各种问题。应用层监控涉及下面几个核心模块:
请求流量
任何服务,高并发的流量都会暴露各种服务问题,尤其核心接口的流量更是监控的重点。
服务链路
一次请求发生问题,快速判断问题所在的服务,或者哪些服务之间,这对快速处理问题是至关重要的。
日志体系
核心接口日志记录也是必备的功能,通常情况下基于日志体系的分析结果,可以明确系统的异常点,重点优化。
3、软件服务
为了解决分布式系统的各种复杂业务场景,通常会引入各种中间软件来做支撑,例如必备的数据库,缓存,消息MQ等,通常这些中间件都会有自带的监控管理端口。
数据库:较多使用Druid监控分析;
消息队列:常用RocketMQ和控制台;
Redis缓存:提供命令获取相关监控数据;
还有一些公司甚至直接在中间件层开发一套管理运维和监控的聚合平台,这样更容易从整体上分析问题。
4、硬件服务
硬件层面,运维最关注的三大核心内容:CPU、内存、网络。底层硬件资源爆发的故障,来自上层的应用服务或者中间件服务触发的可能性偏高。
硬件层面的监控有许多成熟的框架,例如zabbix,grafana等,当然这些组件功能很丰富,不仅仅在硬件层应用。
5、雪崩效应
有些故障导致大面积服务瘫痪,也称为雪崩效应,可能故障源没有快速处理,也没有熔断机制,导致整个服务链路全部垮掉,这是常见的问题,所以在处理故障时,要学会基于全栈监控信息,全局关联分析核心故障点,快速切断单点服务的故障,保证整个系统的可用性。
三、注意事项
监控系统虽然作用很大,但是实际搭建的时候难度还是很大,需要有较好的意识,不是业务开发那种感觉,方方面面需求都需要处理,做监控系统的基本策略如下。
1、选择性
不是所有服务的所有环境,和所有接口都需要监控,通常都是监控核心链路,核心中间件,和服务所在环境。
例如:交易链路,交易库,和部署的环境;或者大客户高并发业务,一旦出问题需要及时响应,立即处理。说的直接点,带来收益的服务是需要重点关注的。
非关键服务即使出现问题,是有缓冲时间的,所以不需要花费精力添加监控,在做监控系统的时候存在这样一句话:简单的链路添加监控,复杂了容易出错;复杂链路添加监控,更复杂更容易出错,然而这样却是为了更好的解决故障。
2、独立性
监控系统的本身发生故障,不能影响正常业务流程,即使在一定情况下没有监控信息,也不能因为监控服务影响正常业务服务。
3、整体性
聚合的监控系统可以观察监控链路的全局状态,这样可以快速定位故障坐标,可以关联性分析问题原因。
4、预警性
例如CPU突然升高,某个中间件服务突然停止,内存占用过高,这些可以基于监控系统做预警通知,然后邮件或者消息通知到相关负责人,达到快速响应的目的,这个场景大部分开发都熟悉,且有心理阴影。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent
推荐阅读:架构设计系列