一、HDFS梳理
1.组件及功能
(1)NameNode:
存储:文件系统的命名空间
a.文件名称;
b.文件目录结构;
c.文件属性【权限,创建时间,副本数量】
d.文件对应哪些数据块-->数据块对应哪些datanode节点,blockmap namenode节点不会持续的存储这种映射关系,是通过集群在启动和运行过程中,datanode 定期发送blockReport给NameNode,以此NameNode在内存中来动态维护这种映射关系。
作用:管理文件系统的命名空间。它维护着文件系统树及整棵树内所有文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间文件fsimage和编辑日志文件editlog。
(2)DataNode:
存储:数据块和数据块校验
与NameNode通信:
a.每隔3秒发送一个心跳包
b.每十次心跳发送一次blockReport
作用:读写文件的数据块
(3)SecondaryNode:
存储:fsimage+editlog
作用:定期合并fsimage+editlog文件为新的fsimage推送给NameNode。俗称检查点动作,checkpoint。
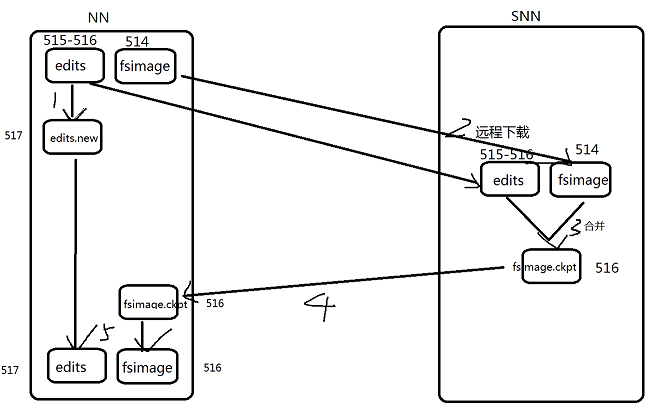
1.snn执行checkpoint动作时候,nn会停止使用当前的edit文件515-516,会暂时将读写操作记录到一个新的edit文件中 517
2.snn将nn的fsimage 514 和 edits文件 515-516 远程下载到本地
3.snn将fsimage 514加载到内存中,将 edits文件 515-516 内容之内存中从头到尾的执行一次,创建一个新的fsimage文件 516
4.snn将新的fsimage 516推送给nn
5.nn接受到fsimage 516.ckpt 滚动为fsimage 516,新的edit文件中 517.new 滚动为 edit 517 是一份最新
2.读流程
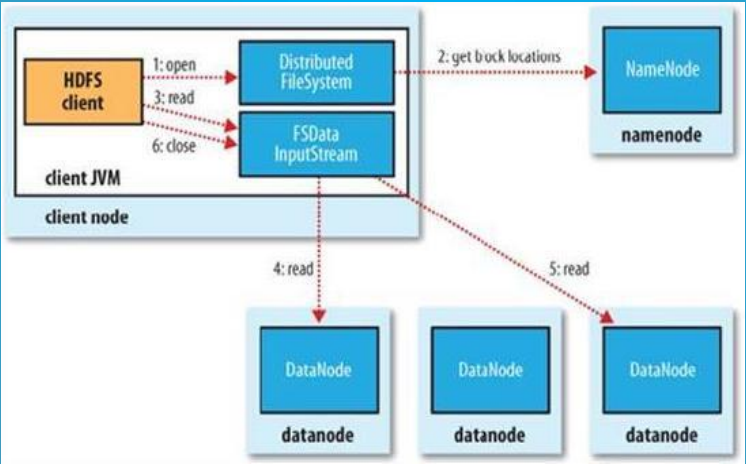
(1)Client调用FileSystem的open(filePath),与NN进行【rpc】通信,返回该文件的部分或者全部的block列表也就是返回【FSDataIntputStream】对象。
(2)Client调度【FSDataIntputStream】对象的read方法,与第一个块的最近的DN的进行读取,读取完成后,会check,假如ok就关闭与DN通信。假如不ok,就会记录块+DN的信息,下次就不从这个节点读取。那么从第二个节点读取。然后与第二个块的最近的DN的进行读取,以此类推。假如当block的列表全部读取完成,文件还没结束,就调用FileSystem从NN获取下一批次的block列表。
(3)Client调用【FSDataIntputStream】对象的close方法,关闭输入流。
3.写流程
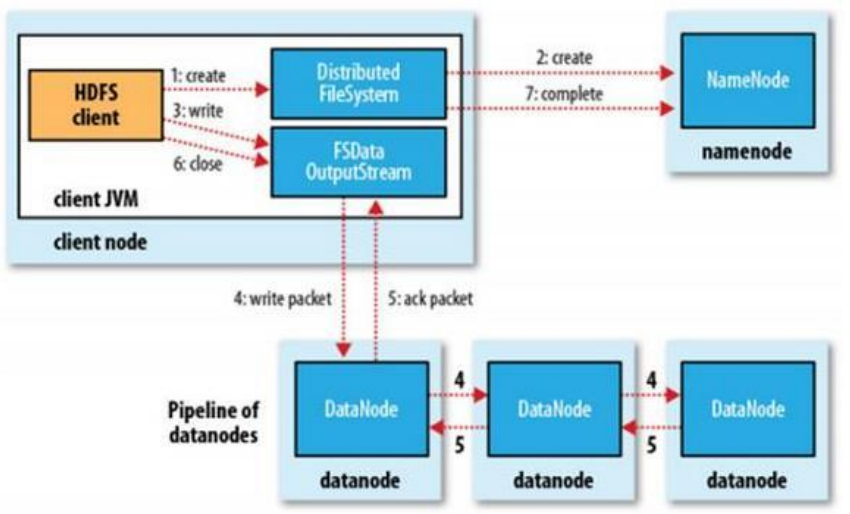
(1) HDFS Client调用FileSystem.create(filePath)方法,去和NN进行【RPC】通信。NN会去check这个文件是否存在,是否有权限创建这个文件。假如都可以,就创建一个新的文件,但是这时没有数据,是不关联任何block的。NN根据文件的大小,根据块大小 副本数,计算要上传多少的块和对应哪些DN节点上。最终这个信息返回给客户端【FSDataOutputStream】对象
(2)Client 调用客户端【FSDataOutputStream】对象的write方法,根据【副本放置策略】,将第一个块的第一个副本写到DN1,写完复制到DN2,写完再复制到DN3。当第三个副本写完,就返回一个ack package确认包给DN2,DN2接收到ack 加上自己写完,发送ack给DN1,DN1接收到ack加上自己写完,就发送ack给客户端【FSDataOutputStream】对象,告诉它第一个块三副本写完了。以此类推。
(3)当所有的块全部写完,Client调用【FSDataOutputStream】对象的close方法,关闭输出流。再次调用FileSystem.complete方法 ,告诉nn文件写成功。
二、YARN梳理
1.说明
Yarn 是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
2.作业提交流程
(1).Client 向RM提交应用程序,其中包含applicationmaster主程序和启动命令
(2).applications manager 会为【应用程序分配第一个container容器】,来运行applicationmaster主程序
(3).applicationmaster主程序就会向applications manager 注册,就可以做yarn的web界面上看到job的运行状态
(4).applicationmaster主程序采取轮询的方式通过【rpc】协议向resourcescheduler,申请和领取资源(哪台机器 领取多少内存 多少cpu VCORE)
(5).一旦applicationmaster主程序拿到资源的列表,就和对应的nm进程进行通信,要求启动container来运行task任务
(6).nm就为task任务设置好运行的环境(container容器)将任务启动命令写在脚本里,并且通过脚本启动任务task
(7).各个container的task 任务(map task、reduce task任务),通过【rpc】协议向applicationmaster主程序进行汇报进度和状态,以此让applicationmaster主程序随时掌握task的运行状态。当task任务运行失败,也会重启container任务
(8).当所有的task任务全部完成,applicationmaster主程序会向applications manager 申请注销和关闭作业,这时在web界面查看任务是 是否完成 ,是成功还是失败。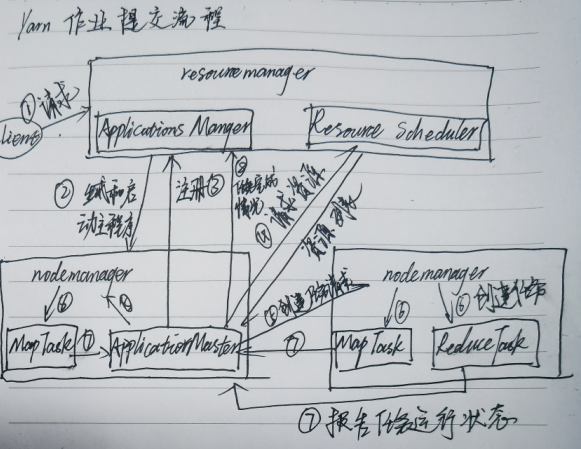
三、HA梳理
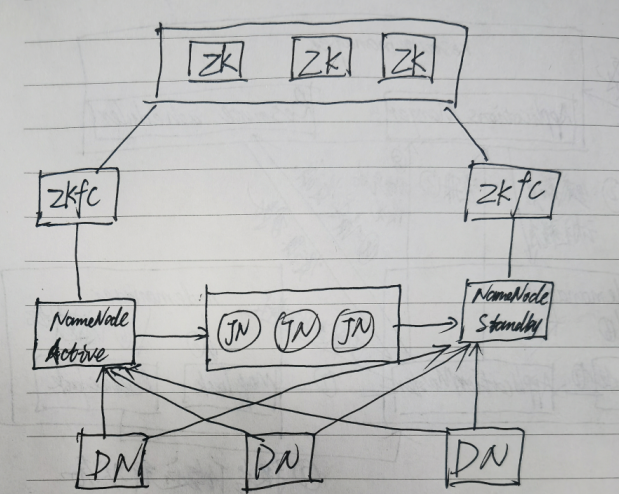
HDFS HA
ZKFC: 是单独的进程,它监控NN健康状态,向zk集群定期发送心跳,使得自己可以被选举;当自己被zk选举为active的时候,zkfc进程通过RPC协议调用使NN节点的状态变为active。
重演:active nn 接收client的rpc请求,同时自己的editlog文件写一条记录。同时发给jn日志集群写一条。standby nn 同时会接收jn日志集群的这条记录,在自己本身执行一下,使得自己的元数据和active nn的元数据是一致的。这步叫做重演。
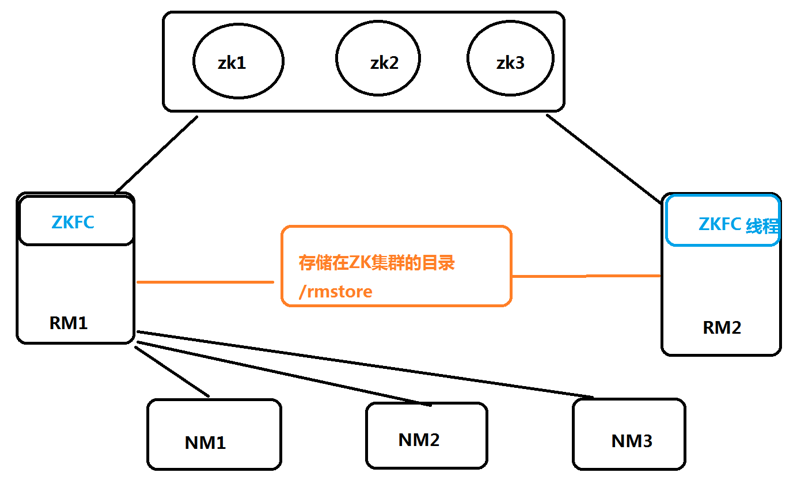
Yarn HA
Yarn中ZKFC是在RM中以线程形式存在的,他没有单独的JN,而是在Zookeeper中创建了一个/rmstore目录来实现相似的效果。
RM启动时会向zk集群的hadoop-ha目录写个lock文件,写成功就标识为active,否则为standby。
standby RM会一直监控lock文件是否存在,如果不存在就尝试去创建,争取为active。
RM会接收client客户端的请求,接收和监控nm的资源汇报,负责资源的分配和调度,启动和监控application master。
官网翻译
In a typical HA cluster, two separate machines are configured as NameNodes. At any point in time, exactly one of the NameNodes is in an Active
state, and the other is in a Standby state. The Active NameNode is responsible for all client operations in the cluster, while the Standby is
simply acting as a slave, maintaining enough state to provide a fast failover if necessary. In order for the Standby node to keep its state synchronized with the Active node, both nodes communicate with a group of separate daemons called
“JournalNodes” (JNs). When any namespace modification is performed by the Active node, it durably logs a record of the modification to a majority
of these JNs. The Standby node is capable of reading the edits from the JNs, and is constantly watching them for changes to the edit log. As the
Standby Node sees the edits, it applies them to its own namespace. In the event of a failover, the Standby will ensure that it has read all of
the edits from the JournalNodes before promoting itself to the Active state. This ensures that the namespace state is fully synchronized before
a failover occurs. In order to provide a fast failover, it is also necessary that the Standby node have up-to-date information regarding the location of blocks in
the cluster. In order to achieve this, the DataNodes are configured with the location of both NameNodes, and send block location information and
heartbeats to both. It is vital for the correct operation of an HA cluster that only one of the NameNodes be Active at a time. Otherwise, the namespace state would
quickly diverge between the two, risking data loss or other incorrect results. In order to ensure this property and prevent the so-called
“split-brain scenario,” the JournalNodes will only ever allow a single NameNode to be a writer at a time. During a failover, the NameNode which
is to become active will simply take over the role of writing to the JournalNodes, which will effectively prevent the other NameNode from
continuing in the Active state, allowing the new Active to safely proceed with failover.
在一个高可用集群中,NameNode分别配置在两个独立的主机上。在任何一个时间点,只有一个NameNode是Active状态,另一个是Standby状态。Active状态下的NameNode来处理集群上的所有请求,同时Standby状态的NameNode
只是想一个小弟一样将大哥的这些操作重演一遍,它会一直维持这个状态,如果需要,它会立刻进行切换。
为了让Standby和Active能够一直保持这种同步状态,两个节点之间通过名叫“JournalNodes”的独立的集群守护程序进行通信。当Active中的信息被修改之后,它会将日志保存下来,并修改这些JN中的内容。Standby可以从JN中读取,
并且不断监视他们对日志文件的修改。当备用节点发现修改过,它会将修改的内容保存到自己的命名空间中。在发生故障转移时,备用节点会确保自己已经读取所有数据,并将自己升级成为活动状态。这可以确保命名空间在发生故障
时转移。为了保证发生故障时快速切换,备用节点必须保存有集群中数据块位置的最新信息。为了实现这一点,DataNode配置了两个相同的NameNode位置,并同时向他们两个发送心跳和块信息。
对于高可用集群能够正常工作,一次只有一个活动状态下的NamNode时非常重要的。否则,命名空间的状态会发生冲突,这样可能会造成数据丢失或者其他错误结果。为了保证这一被称作“脑裂”情况的发生,JN一次
只允许一个NameNode活动。在发生故障时,NameNode会很快的向JN中写入数据,这能有效的防治另一个NameNode继续处于活动状态,允许新的服务能够安全的进行故障转移。