
Hadoop开发存在的问题
只能用java语言开发,如果是c语言或其他语言的程序员用Hadoop,存在语言门槛。
需要对Hadoop底层原理,api比较了解才能做开发。
Hive概述
Hive是基于Hadoop的一个数据仓库工具。可以将结构化的数据文件映射为一张表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取、转化、加载(ETL Extract-Transform-Load ),也可以叫做数据清洗,这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HiveQL,它允许熟悉 SQL 的用户查询数据。
Hive的Hql
HQL - Hive通过类SQL的语法,来进行分布式的计算。HQL用起来和SQL非常的类似,Hive在执行的过程中会将HQL转换为MapReduce去执行,所以Hive其实是基于Hadoop的一种分布式计算框架,底层仍然是MapReduce,所以它本质上还是一种离线大数据分析工具。
数据仓库的特征
1.数据仓库是多个异构数据源所集成的。
2.数据仓库存储的一般是历史数据。 大多数的应用场景是读数据(分析数据),所以数据仓库是弱事务的。
3.数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
4.数据仓库是时变的,数据存储从历史的角度提供信息。即数据仓库中的关键结构都隐式或显示地包含时间元素。
5.数据仓库是弱事务的,因为数据仓库存的是历史数据,一般都读(分析)数据场景。
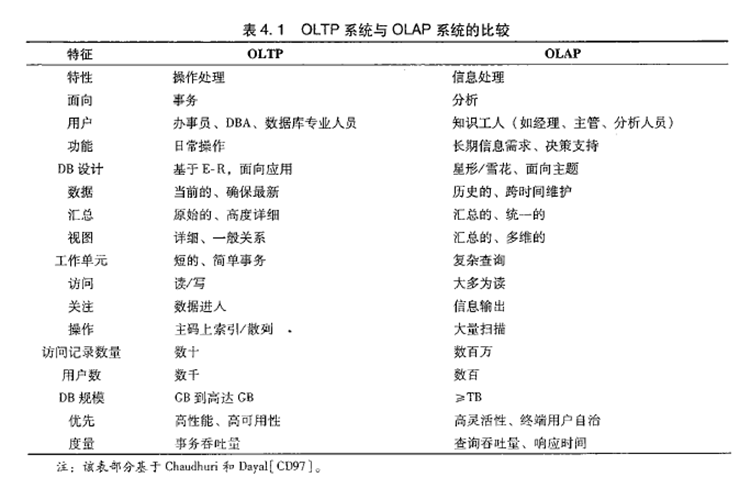
数据库属于OLTP系统。(Online Transaction Processing)联机事务处理系统。涵盖了企业大部分的日常操作,如购物、库存、制造、银行、工资、注册、记账等。比如Mysql,oracle等关系型数据库。
数据仓库属于OLAP系统。(Online Analytical Processing)联机分析处理系统。Hive,Hbase等
OLTP是面向用户的、用于程序员的事务处理以及客户的查询处理。
OLAP是面向市场的,用于知识工人(经理、主管和数据分析人员)的数据分析。
OLAP通常会集成多个异构数据源的数据,数量巨大。
OLTP系统的访问由于要保证原子性,所以有事务机制和恢复机制。
OLAP系统一般存储的是历史数据,所以大部分都是只读操作,不需要事务。
适用场景
Hive 构建在基于静态(离线)批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的离线批处理作业,例如,网络日志分析。