1.foreach
val list = new ArrayBuffer() myRdd.foreach(record => { list += record })
2.foreachPartition
val list = new ArrayBuffer rdd.foreachPartition(it => { it.foreach(r => { list += r }) })
说明:
foreachPartition属于算子操作,可以提高模型效率。比如在使用foreach时,将RDD中所有数据写Mongo中,就会一条数据一条数据地写,每次函数调用可能就会创建一个数据库连接,此时就势必会频繁地创建和销毁数据库连接,性能是非常低下;但是如果用foreachPartitions算子一次性处理一个partition的数据,那么对于每个partition,只要创建一个数据库连接即可,然后执行批量插入操作,此时性能是比较高的。
参考官网的说明:
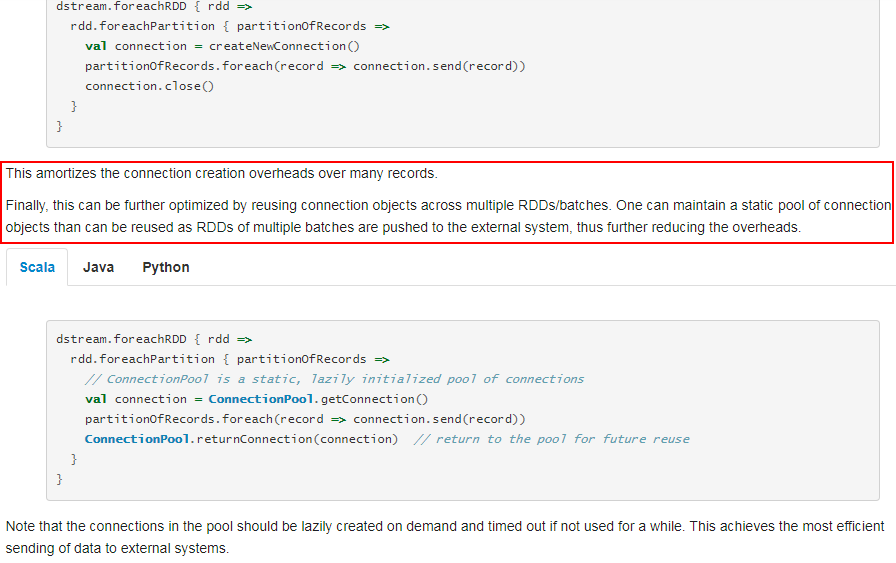
获取每个分区的索引:
rdd.foreachPartition { partitionOfRecords: Iterator[Row] =>
partitionOfRecords.foreach((record: Row) => {
println(TaskContext.getPartitionId)
print(record.get(0))
print(record.get(1))
print(record.get(2))
})
}