Nginx基本安全优化
隐藏Nginx软件版本号信息
一般来说,软件的漏洞都和版本有关,这个很像汽车的缺陷,同一批次的要有问题就都有问题,别的批次可能就都是好的。因此,我们应尽量隐藏或者消除Web服务对访问用户显示各类敏感信息(例如Web软件名称以及版本号等信息),增加恶意用户攻击服务器的难度,从而加强Web服务器的安全性。
我现在在我的CentOS7上编译安装了Nginx,当我们请求服务器的时候我们可以通过chrome的调试工具看到我们请求的服务器Nginx的版本,如下图所示
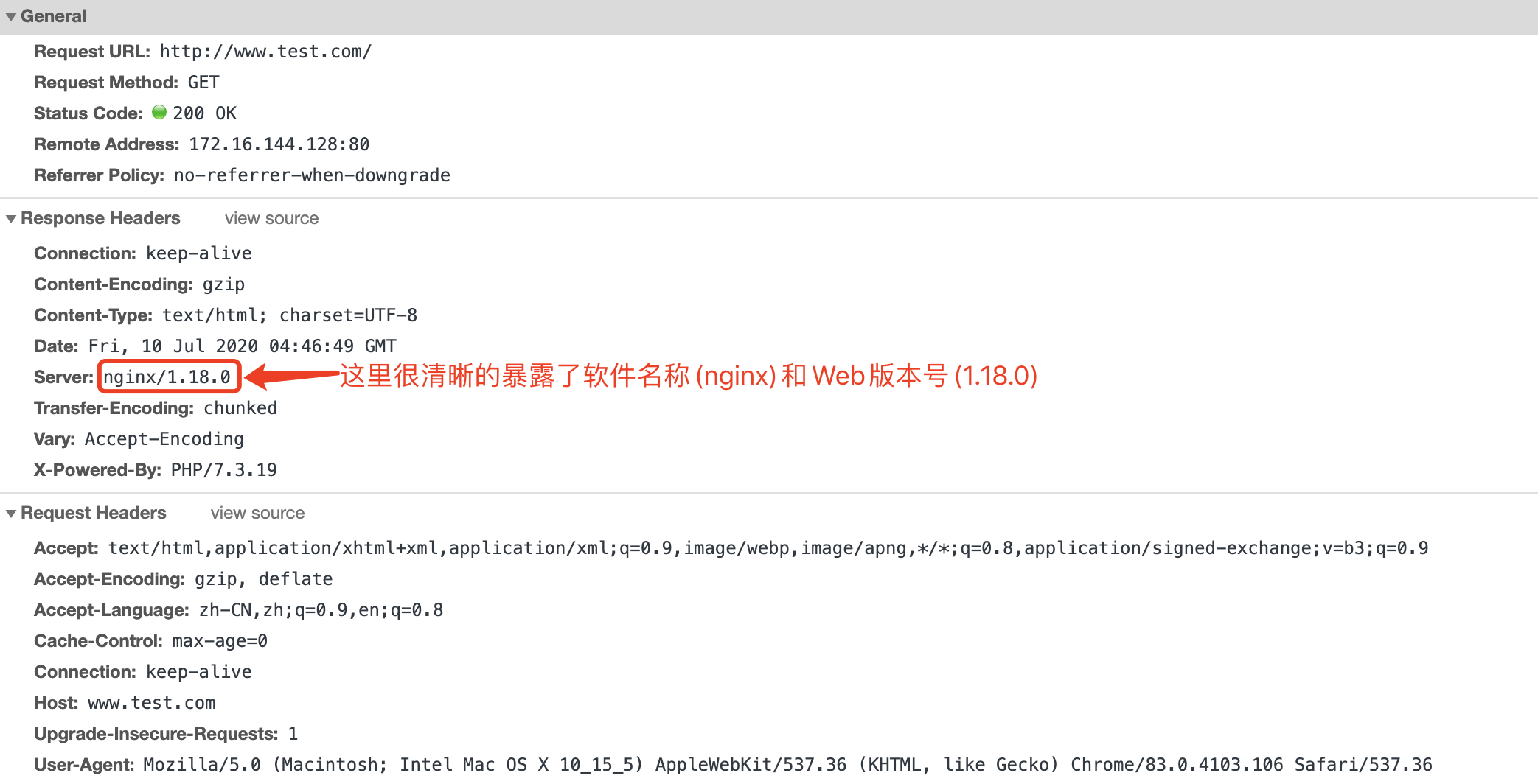
假如Nginx1.18.0这个版本有漏洞,那么恶意用户就可以根据这个信息通过漏洞来攻击我们的服务器
现在我们来在Nginx的配置文件nginx.conf中增加一项参数来隐藏Nginx的版本,这样用户就不知道我们用的是哪个版本的Nginx了。
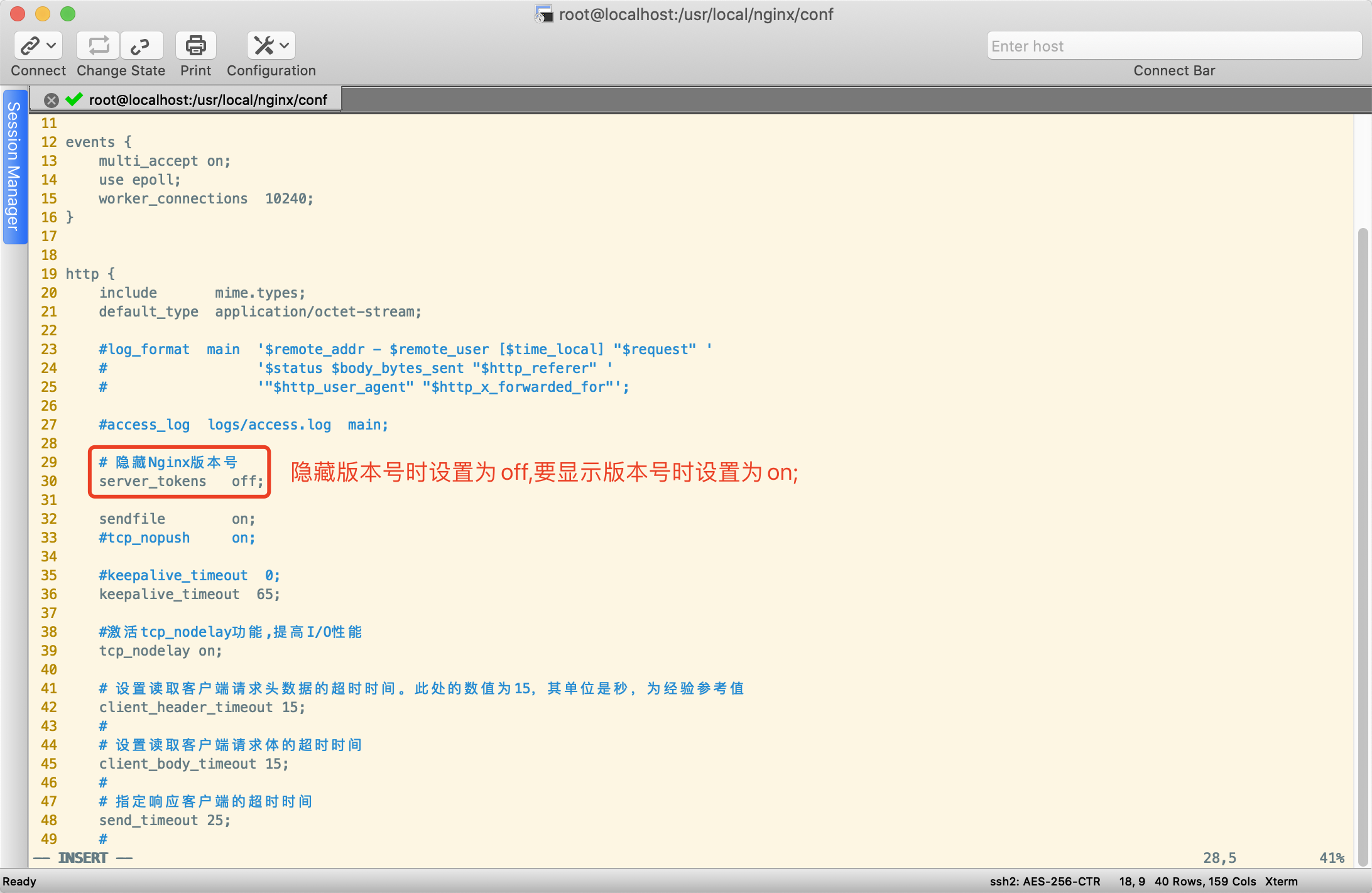
在nginx.conf中的http标签段内加入server_tokens off;参数,如下图所示
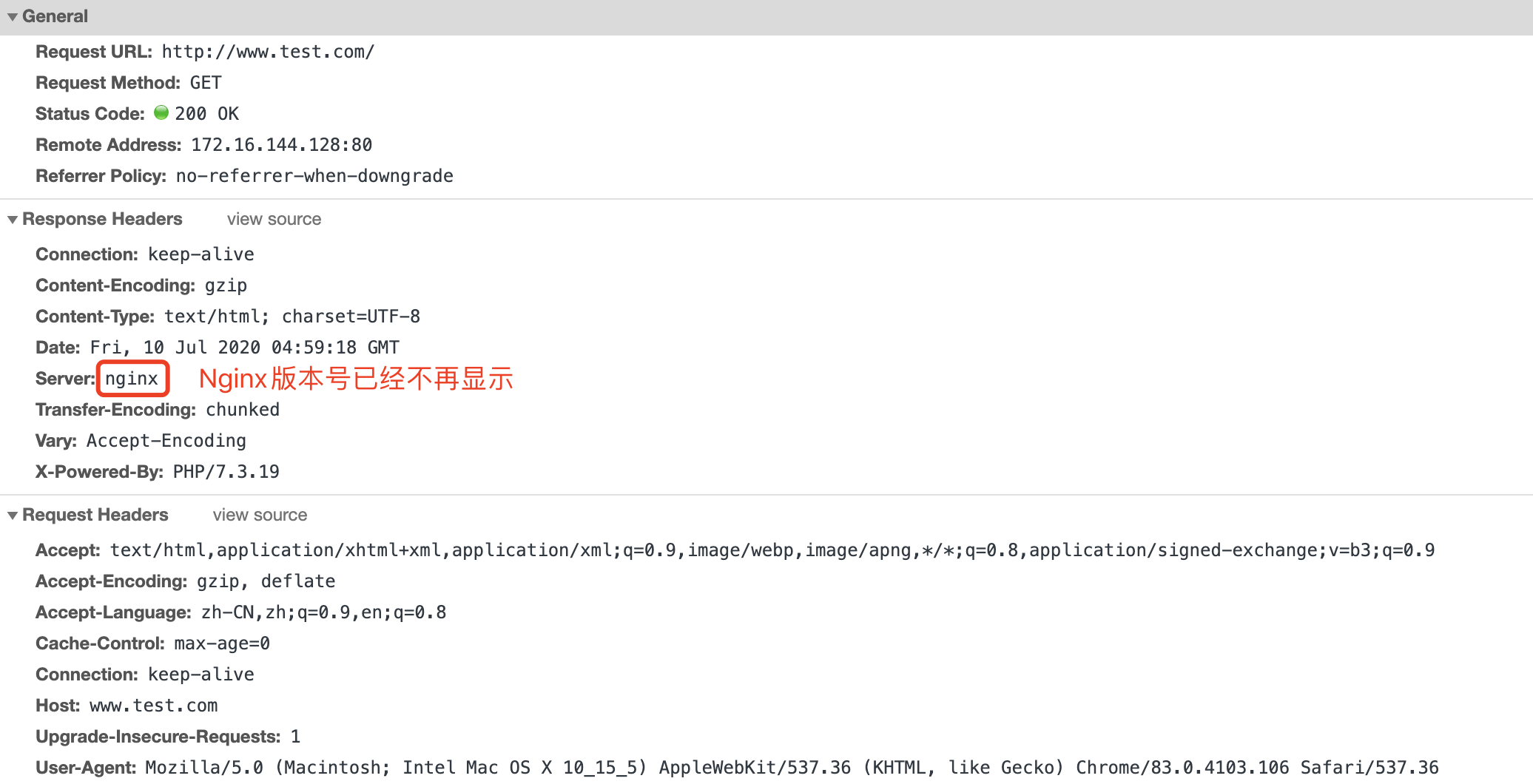
现在我们重启服务器再次访问可以看到Nginx版本号已经看不到了
更改源码隐藏Nginx软件名及版本号
隐藏了Nginx版本号后,更进一步,可以通过一些手段把Web服务软件的名称也隐藏起来,或者改为其他Web服务软件名以迷惑恶意用户。Nginx并不提供修改Nginx软件名称的参数和入口,需要修改源码才行,这里只是提供一个思路,修改源码需慎重,防止修改源码导致服务器不能正常运行。其它服务器软件同理。修改方法自行百度。
修改Nginx服务的默认用户
为了让Web服务更安全,要尽可能地改掉软件默认的配置,比如端口、用户等。
下面就来更改Ninx服务的默认用户。
首先,查看Ninx服务对应的默认用户。一般情况下,Ninx服务启动后,默认使用的用户是nobody,查看默认的配置文件命令如下:
grep '#user' nginx.conf.default

为了防止黑客猜到这个Web服务的用户,我们需要更改为特殊的用户名,例如www、nginx或者特殊点的itbsl,但是这个用户必须是系统里事先存在的,下面以nginx用户为例进行说明
(1)为Nginx服务创建新用户
为Nginx服务建立新用户的操作过程如下:
useradd nginx -s /sbin/nologin -M # 不需要有系统登录权限,应当禁止其登录能力
(2)配置Nginx服务,让其使用刚建立的Nginx用户
更改Nginx服务默认使用的用户,方法有两种
第一种是直接修改配置文件参数,将默认的#user nobody;修改为如下内容:
user nginx nginx;
如果注释或不设置上述参数,默认为nobody用户,不推荐使用nobody用户名,最好采用一个普通用户。
第二种方法为直接在编译Nginx软件的时候指定编译的用户名和组,命令如下(推荐使用该种方式):
./configure
--user=nginx
--group=nginx
--prefix=/usr/local/nginx-1.18.0
--with-http_v2_module
--with-http_ssl_module
--with-http_stub_status_module
提示:在编译Nginx服务时,直接指定用户和组,这样无论配置文件中是否加参数,默认都是nginx用户。
修改参数优化Nginx服务性能
优化Nginx服务的worker进程数
在高并发、高访问量的Web服务场景,需要事先启动好更多的Nginx进程,以保证快速响应并处理大量并发用户的请求。
1.优化NGINX进程对应的配置
优化Nginx进程对应的Nginx服务的配置参数如下:
worker_processes 1; # 指定了Nginx要开启的进程数,结尾的数字就是进程的个数
上述参数调整的是Nginx服务的worker进程数,Nginx有Master进程和worker进程之分,Master为管理进程,真正处理请求的是worker进程。
2.优化Nginx进程个数的策略
worker_processes参数大小的设置最好和网站的用户数量相关联,可如果是新配置,不知道网站的用户数量该怎么办?
搭建服务器时,worker进程数最开始的设置可以等于CPU的核数,且worker进程数要多一些,这样起始提供服务时就不会出现因为访问量快速增加而临时启动新进程提供服务的问题,缩短了系统的瞬时开销和提供服务的时间,提升了服务用户的速度。高流量高并发场合也可以考虑将进程数提高至CPU核数*2,具体情况要根据实际的业务来选择,因为这个参数除了要和CPU核数匹配外,也和硬盘存储的数据及系统的负载有关,设置为CPU的核数是一个好的起始配置,这也是官方的建议。
3.查看Web服务器CPU硬件资源信息
通过/proc/cpuinfo可查看CPU个数及总核数。查看PCU总核数的示例如下:
# 方法一
grep processor /proc/cpuinfo | wc -l
# 方法二
grep -c processor /proc/cpuinfo

通过top命令,然后按数字1,即可显示所有的CPU核数,如下:
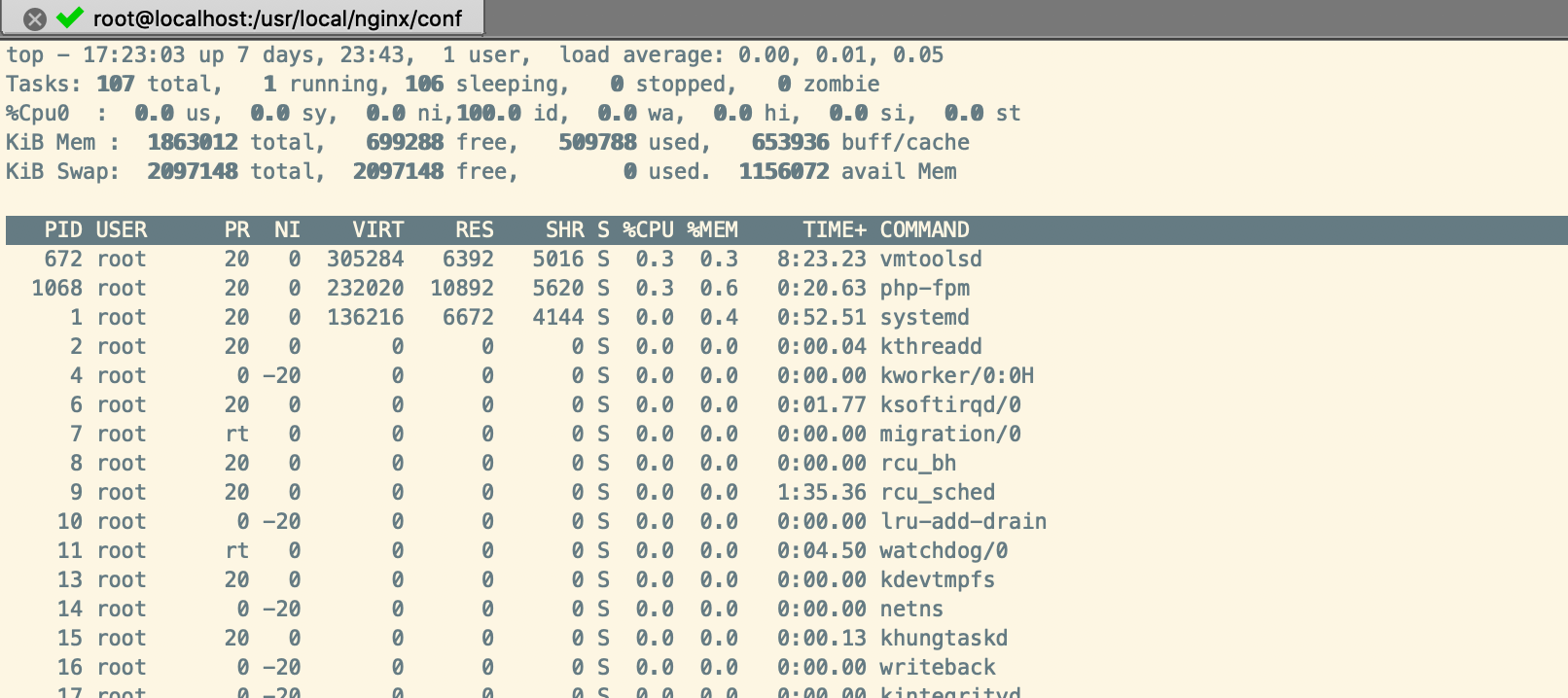
4.修改服务器Nginx配置
我的服务器时1核2G,假设服务器的CPU颗数为1颗,核数为4核,我们将参数值改为4
worker_processes 4;
修改并保存后,优雅重启Nginx,使修改生效,如下:
nginx -s reload
现在检查修改后的worker进程数量,如下:
# 假如Nginx监听的是8端口
lsof -i:80
# 或者通过如下命令查看
ps -ef | grep nginx | grep -v grep
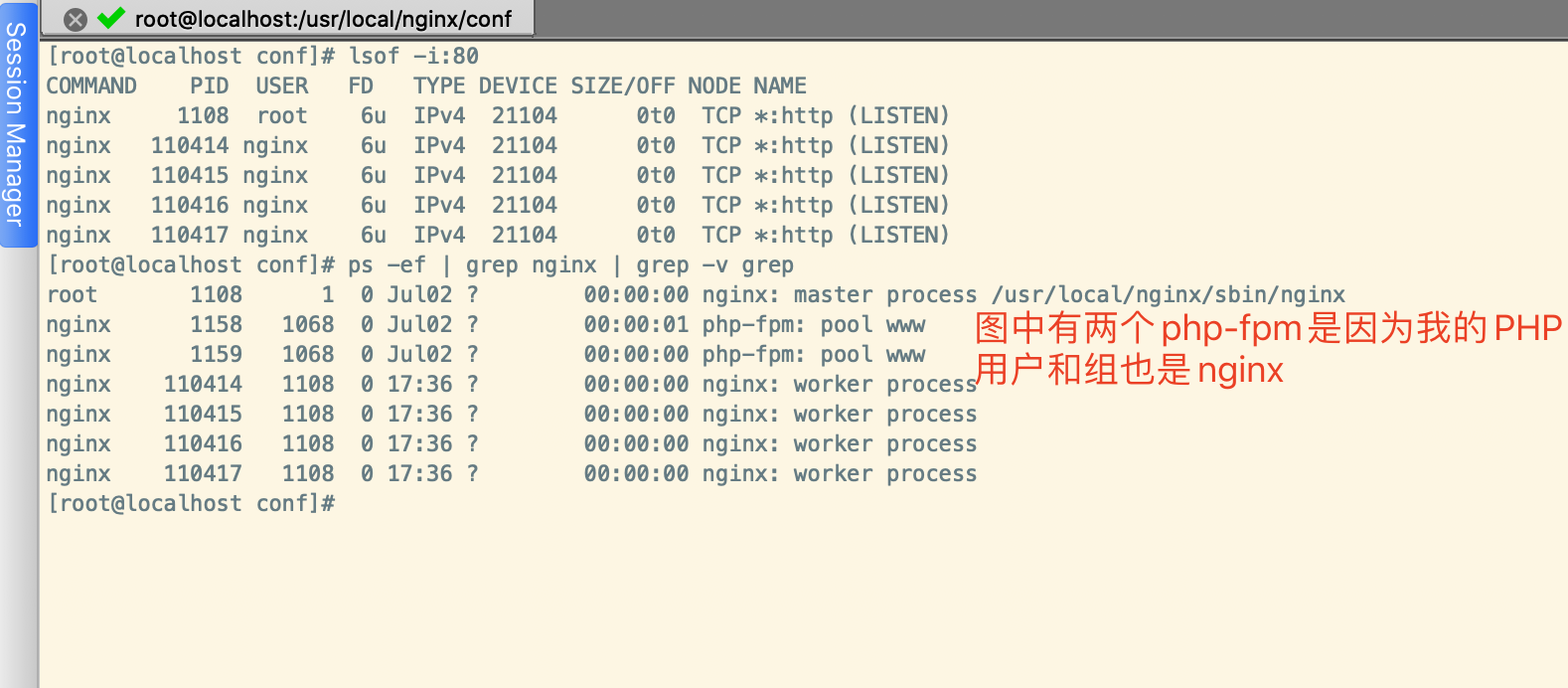
从worker_process可知,worker的进程数为4个。Nginx Master主进程不包含在这个参数里,Nginx Master的主进程为管理进程,负责调度和管理worker进程。
绑定不同的Nginx进程到不同的CPU上
默认情况下,Nginx的多个进程有可能跑在某一个CPU或CPU的某一核上,导致Nginx进程使用硬件的资源不均,所以我们需要配置Nginx与CPU的亲和力参数,尽可能地分配不同的Nginx进程给不同的CPU处理,打到充分有效利用硬件的多CPU多核资源的目的。
在优化不同的Nginx进程对应不同的CPU配置时,四核CPU服务器的参数配置参考如下:
worker_processes 4;
# worker_cpu_affinity就是配置Nginx进程与CPU亲和力的参数,即把不同的进程分给不同的CPU处理。这里0001 0010 0100 1000
# 是掩码,分别代表第1、2、3、4核CPU,由于worker_processes进程数为4,因此,该配置会吧每个进程分配一核CPU处理,默认情况
# 下进程不会绑定任何CPU,参数位置为main段
worker_cpu_affinity 0001 0010 0100 1000;
八核CPU服务器的参数配置参考如下:
worker_processes 8;
worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000 00100000 01000000 10000000;
Nginx事件处理模型优化
Nginx的连接连接处理机制在不同的操作系统会采用不同的I/O模型,在Linux下,Nginx使用epoll的I/O多路复用模型,在Freebsd中使用kqueue的I/O多路复用模型,在Solaris中使用/dev/poll方式的I/O多路复用模型,在Windows中使用的是icop,等等。
要根据系统类型选择不同的事件处理模型,可供使用的选择有use [kqueue|rtsig|epoll|/dev/poll|select|poll]。我使用的是CentOS7,因此将Nginx的时间处理模型调整为epoll模型。
具体的配置参数如下:
# events指令是设定Nginx的工作模式及连接数上限
events {
use epoll;
worker_connections 10240;
}
# use是一个事件模块指令,用来指定Nginx的工作模式。Nginx支持的工作模式有select、poll、kqueue、epoll、rtsig和/dev/poll
# 其中select和poll都是标准的工作模式,kqueue和epoll是高效的工作模式,不同的是epoll用在Linux平台上,kqueue用在BSD系统中。对于Linux系统Linux2.6+的内核,推荐选择epoll工作模式,这是高性能高并发的设置
调整Nginx单进程允许的客户端最大连接数
接下来,调整Nginx单个进程允许的客户端最大连接数,这个控制连接数的参数为worker_connections。
events {
# worker_connections也是个事件模块指令,用于定义Nginx每个进程的最大连接数,默认是1024。最大客户端连接数由
# worker_processes和worker_connections决定,即Max_client=worker_processes*worker_connections。进程
# 的最大连接数受Linux系统进程的最大打开文件数限制,在执行操作系统命令`ulimit -HSn 65535`或配置相关文件后,
# worker_connections的设置才能生效
worker_connections 10240;
}
说明:worker_connections用来设置一个worker process支持的最大并发连接数,这个连接数包括了所有连接,例如:代理服务器的连接、客户端的连接等,实际的并发连接数除了受worker_connections参数控制外,还和最大打开文件数 worker_rlimit_nofile有关,Nginx总并发连接=worker数量 * worker_connections。
配置Nginx worker进程最大打开文件数
接下来,调整配置Nginx worker进程的最大打开文件数,这个控制连接数的参数为worker_rlimit_nofile。该参数的实际配置如下:
# 最大打开文件数,可设置为系统优化后的ulimit -HSn的结果,调整系统文件描述和这个问题有相同之处
worker_rlimit_nofile 65535;
开启高效文件传输模式
1.设置参数: sendfile on;
sendfile参数用于开启文件的高效传输模式。同时将tcp_nopush和tcp_nodelay两个指令设置为on,可防止网络及磁盘I/O阻塞,提升Nginx工作效率。
sendfile on;
2.设置参数:tcp_nopush on;
参数作用:激活或禁用
限制文件上传大小
下面介绍如何调整上传文件的大小(http Request body size)限制。
在nginx.conf的http段增加如下配置参数:
client_max_body_size 10m; # 最大允许上传的文件大小根据业务需求来设置
如果上传的文件大小超过该设置,那么就会报413 Request Entity Too Large的错误。
配置gzip压缩实现性能优化
Nginx gzip压缩功能介绍
Nginx gzip压缩模块提供了压缩文件内容的功能,用户请求的内容在发送到用户客户端之前,Nginx服务器会根据一些具体的策略实施压缩策略,以节约网站出口带宽,同时加快数据传输效率,来提升用户访问体验。
Nginx gzip压缩的优点
- 提升网站用户体验:发送给用户的内容小了,用户访问单位大小的页面就加快了,用户体验提升了,网站口碑就好了
- 节约网站带宽成本:数据是压缩传输的,因此节省了网站的带宽流量成本,不过压缩时会稍微消耗一些CPU资源,这个一般可以忽略不计
需要和不需要压缩的对象
- 纯文本内容压缩比很高,因此,纯文本的内容最好进行压缩,例如:html、css、js、xml、shtml等格式的文件
- 被压缩的纯文本文件必须大于1KB,由于压缩算法的特殊原因,极小的文件压缩后可能反而变大
- 图片、视频(流媒体)等文件尽量不要压缩,因为这些文件大多都是经过压缩的,如果再压缩很可能不会减小或减小很少,或者可能增大,同事压缩时还会消耗大量的CPU、内存资源
参数介绍及配置使用
此压缩功能与早期的Apache服务的mod_deflate压缩功能很相似,Nginx的gzip压缩功能依赖于ngx_http_gzip_module模块,默认已安装。
对应的压缩参数说明如下:
#压缩配置
# 开启gzip压缩功能
gzip on;
# 设置允许压缩的页面最小字节数,页面字节数从header头的Content-Length中获取。默认值是0,表示不管页面多大都进行压缩。
# 建议设置成大于1K,如果小于1K可能会越压越大
gzip_min_length 1k;
# 压缩缓存区大小。表示申请4个单位的位16K的内存作为压缩结果流缓存,
# 默认值是申请与原始数据大小相同的内存空间来存储gizp压缩结构
gzip_buffers 4 16k;
# 压缩版本(默认1.1),用于设置识别HTTP协议版本,默认是1.1,目前大部分浏览器都支持GZIP解压,使用默认即可
gzip_http_version 1.1;
# 压缩比率。用来指定gzip压缩比,1压缩比最小,处理速度最快;9压缩比最大,传输速度快,但处理最慢,也比较消耗CPU资源
gzip_comp_level 2;
# 用来指定压缩的类型
gzip_types text/plain text/css text/xml application/javascript;
# vary header支持。该选项可以让前端的缓存服务器缓存经过gzip压缩的页面,例如用Squid缓存经过Nginx压缩的数据
gzip_vary on;
不同Nginx版本中,gzip_types的配置可能会有不同,对应的文件类型,请查看安装目录的mime.types文件
增加http accept-ranges头来提高性能
网页的图片,js ,css ,视频 都加 http accept-ranges头,以支持多线程加载,断点续传,提高性能!目前各大网站都在使用此方式!
server {
listen 80;
server_name p2hp.com;
location ~ ^/(img/|js/|css/|upload/|font/|fonts/|res/|video) {
add_header Access-Control-Allow-Origin *;
add_header Accept-Ranges bytes;
root /var/www/...;
access_log off;
expires 30d;
}
}
Nginx日志相关优化与安全
Nginx access日志切割
为什么要做日志切割?
因为随时系统访问量的增长,访问日志里会出现越来越多的数据,如果不去按照时间去做合理的日志切割,访问日志里的数据多到无法打开的地步,所以需要做日志切割。
创建一个runlog.sh文件,按天切割
LOGPATH=/usr/local/nginx/logs/access.log
BASEPATH=/usr/local/nginx/logs/access/$(date -d yesterday +%Y%m)
mkdir -p $BASEPATH
BACKUP=$BASEPATH/$(date -d yesterday +%Y%m%d).access.log
mv $LOGPATH $BACKUP
touch $LOGPATH
/usr/local/nginx/sbin/nginx -s reopen

然后配合定时任务,每天零点切割一次
0 0 * * * sh /usr/local/nginx/logs/runlog.sh

Nginx图片及目录防盗链解决方案
如果我们自己网站内的图片资源被其它网站所盗用,这会增加自己网站的带宽资源,增加很多额外的消耗,而且会对我们系统的稳定性有影响,为了防止自己网站上的图片资源被其它网站所盗用,我们需要给自己的服务器配置防盗链。
在Nginx的配置文件nginx.conf的 server段匹配图片资源允许的域名,,不匹配的直接重定向到其它连接或者直接返回403错误。
# 图片防盗链
location ~* .(png|jpg|jpeg|gif|swf|flv)$ {
valid_referers none blocked www.test.com *.test.com;
if ($invalid_referer) {
# 如果有盗链的情况就使用url重写到错误页面(示例重定向到了百度首页logo图片)
rewrite ^/ https://www.baidu.com/img/bd_logo1.png?qua=high;
# 或者直接返回403错误码
#return 403;
}
}
Nginx防爬虫优化
robots.txt机器人协议介绍
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎那些页面可以抓取,那些页面不能抓取。
Nginx防爬虫优化配置
我们可以根据客户端的user-agent信息,轻松地阻止指定的爬虫爬取我们的网站。下面来看几个案例。
范例1:阻止下载协议代理,命令如下:
if ($http_user_agent ~* LWP::Simple|BBBike|wget) {
return 403;
}
说明:如果用户匹配了if后面的客户端(例如wget),就返回403
范例2:测试禁止不同的浏览器软件访问
示例代码如下:
if ($http_user_agent ~* "Firefox|MSIE") {
rewrite ^(.*) http://www.baidu.com/$1 permanent;
}
如果浏览器为FireFox或IE,就会跳转到http://www.baidu.com。
整理自:
跟老男孩学Linux运维:Web集群实战,机械工业出版社
网页的图片,js ,css ,视频 都加 http accept-ranges头,以提高性能
如果该文章对您有帮助,请点击推荐,感谢。
node上的__dirname和./的区别
Mysql存储之ORM框架SQLAlchemy(一)
selenium只打开一个浏览器窗口
Mysql存储之原生语句操作(pymysql)
汽车之家反爬
javascript反混淆之packed混淆(一)
python近期遇到的一些面试问题(三)
[转载]关于python字典类型最疯狂的表达方式
.net爬虫了解一下