服务器层面优化(了解)
将数据保存在内存中,保证从内存读取数据
- 设置足够大的innodb_buffer_pool_size,将数据读取到内存中。
- 建议innodb_buffer_pool_size设置为总内存大小的3/4或者4/5。
- 怎样确定innodb_buffer_pool_size足够大,数据是从内存读取而不是硬盘?
show global status like 'innodb_buffer_pool_pages_%';
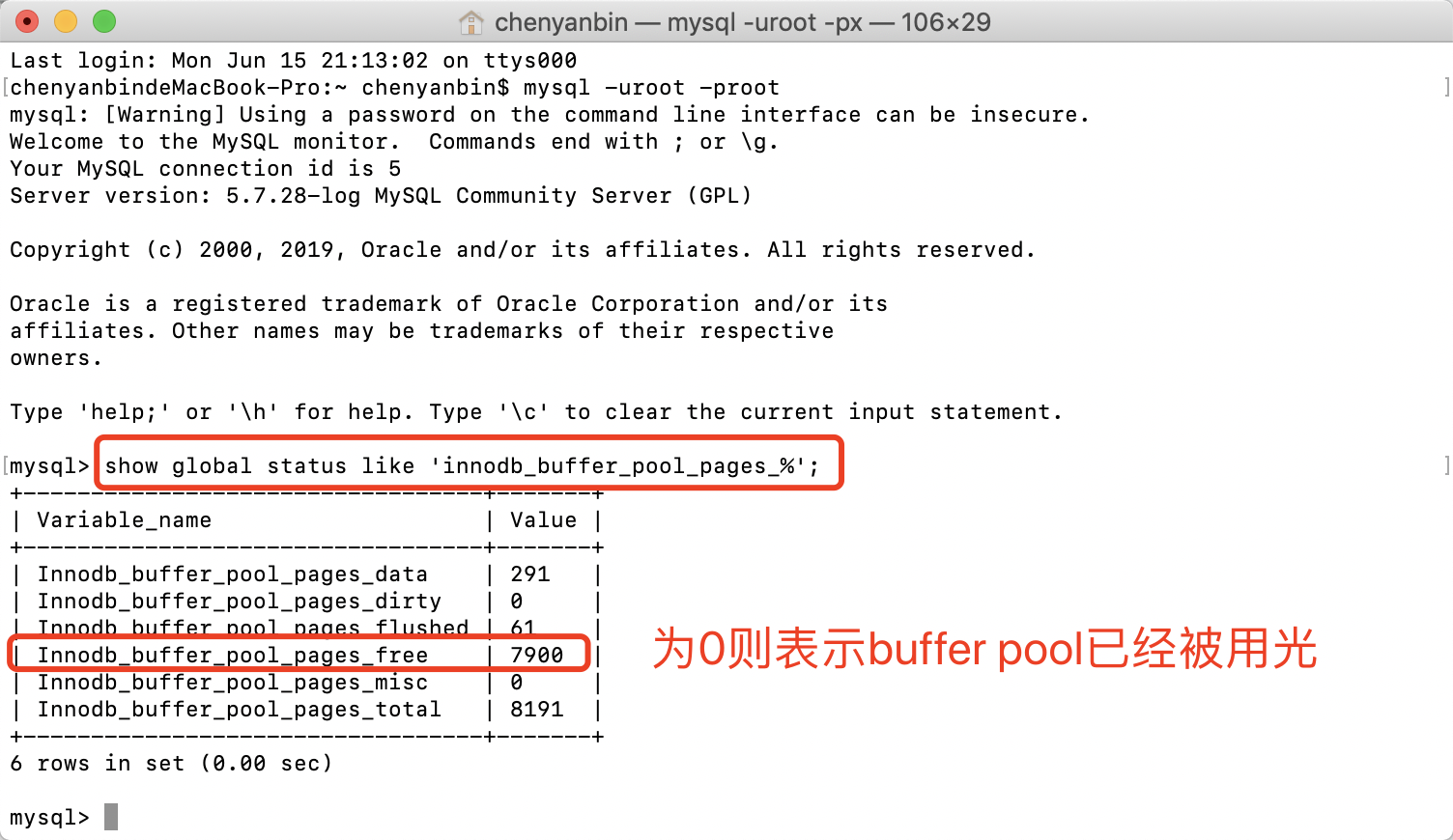
降低磁盘写入次数
- 使用足够大的写入缓存innodb_log_file_size
- 推荐innodb_log_file_size设置为0.25*innodb_buffer_pool_size
- 设置合适的innodb_flush_log_at_trx_commit
提高磁盘读写
可以考虑使用SSD硬盘,不过得考虑成本是否合适。
SQL设计优化(了解需求的人并懂技术的人)
- 设计中间表,一般针对统计分析功能,或者实时性不高的需求
- 为减少关联查询,创建合理的冗余字段
- 对于字段太多的大表,考虑拆表
- 对于表中经常不被使用的字段,考虑拆表
- 每张表都有一个主键,而且主键类型最好是int类型,建议自增主键
SQL语句优化(开发人员)
索引优化
- 为搜索字段创建索引(考虑:查询多还是增删多?)
- 尽量建立组合索引并注意组合索引的创建顺序,按照顺序组织查询条件,尽量将筛选粒度大的查询条件放到最左边
- SELECT 语句尽量不要使用*
- order by、group by语句尽量使用索引
LIMIT优化
- 如果预计SELECT 语句的查询结果是一条,最好使用LIMIT 1,可以停止全表扫描
- SELECT * FROM S_USER WHERE USERNAME='chenyanbin' LIMIT 1;
- 处理分页会使用到LIMIT,当翻页到非常靠后的页面的时候,偏移量会非常大,这时LIMIT的效率会非常差
LIMIT的优化问题,其实是OFFSET的问题,他会导致MySQL扫描大量不需要的行然后再抛弃掉。 解决方案:使用order by和索引覆盖 原sql: SELECT user_name,age FROM s_user LIMIT 10000,20; 优化后SQL: SELECT user_name,age FROM s_user ORDER BY city LIMIT 20;
其他优化
- 尽量不使用count(*)、尽量使用count(主键)
- JOIN两张表的关联字段最好都建立索引,而且最好字段类型是一样的
- WHERE条件中尽量不要使用1=1、not in 语句(建议使用not exists)
- 不用MySQL内置的函数,因为内置函数不会建立查询缓存
- 合理利用慢查询日志、explain执行计划查询、show profile查询SQL执行的资源使用情况