目录
文章目录
- 目录
- 七,类和对象
- 7.1 面向对象编程介绍
- 7.2 类和对象
- 7.3 定义类与创建对象
- 7.4 self (init,new,del,str,id)
- 7.5 封装
- 7.6 继承
- 7.7 多继承
- 7.8 多态
- 7.9 类属性与实例属性
- 7.10 类方法和静态方法
- 总结
- 八,设计模式
- 九,异常
- 十,Python模块及安装
- 十一,列表推导式
- 十二,python数据库操作
- 十三,Python科学计算类库:Numpy
- 13.1 Numpy介绍
- 13.2 Numpy的安装
- 13.3 numpy 基础
- 13.4 创建数组并查看其属性
- 13.5 常用函数
- 13.6 索引,切片和迭代
- 13.7 矩阵的操作
- 13.8 形状操作
- 总结
- 总结
- 作业
七,类和对象
7.1 面向对象编程介绍
面向对象编程——Object Oriented Programming,简称OOP,是一种程序设计思想。OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。面向对象是一种对现实世界理解和抽象的方法。
“面向过程”(Procedure Oriented)是一种以过程为中心的编程思想。“面向过程”也可称之为“面向记录”编程思想,他们不支持丰富的“面向对象”特性(比如继承、多态、封装),并且它们不允许混合持久化状态和域逻辑。
就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。
面向过程是一件事“该怎么做“,面向对象是一件事“该让谁来做”,然后那个“谁”就是对象,他要怎么做是他自己的事,反正最后一群对象合力能把事做好就行了。
面向对象三个特性:继承,封装,多态。
多态的本质:同一个指令的不同实现方式(对象不同)
封装:把类的内部属性保护起来。把会冲附使用的一块逻辑封装为方法。
7.2 类和对象
面向对象编程的2个非常重要的概念:类和对象
对象是面向对象编程的核心,在使用对象的过程中,为了将具有共同特征和行为的一组对象抽象定义,提出了另外一个新的概念——类
类就相当于制造飞机时的图纸,用它来进行创建的飞机就相当于对象
类的构成
类(Class) 由3个部分构成
- 类的名称:类名
- 类的属性:一组数据
- 类的方法:允许对进行操作的方法 (行为)
7.3 定义类与创建对象
1.类的定义
定义一个类,格式如下:
class 类名: 方法列表
# 定义一个Car类
class Car:
# 方法
def getCarInfo(self):
print('车轮子个数:%d, 颜色%s'%(self.wheelNum, self.color))
def move(self):
print("车正在移动...")
说明:
-
定义类时有2种:新式类和经典类,上面的Car为经典类,如果是Car(object)则为新式类
# 继承关系使用括号来表示,下一行代表Person继承object class Person(object): def run(self): print("person is running") -
类名的命名规则按照"大驼峰"
注意:
在类中定义属性是必须要给定默认值。
class Person(object):
name="zhangsan"
def run(self):
print("person is running")
2.创建对象
python中,可以根据已经定义的类去创建出一个个对象
创建对象的格式为:
对象名 = 类名()
创建对象demo
# 定义类
class Car:
# 移动
def move(self):
print('车在奔跑...')
# 鸣笛
def toot(self):#self可以不写self,方法中必须有且一个参数。第一个参数表示当前对象。名字随便取,但是习惯都写self
print("车在鸣笛...嘟嘟..")
# 创建一个对象,并用变量BMW来保存它的引用
BMW = Car()
# 给对象添加属性
BMW.color = '黑色'
BMW.wheelNum = 4#轮子数量
BMW.move()
BMW.toot()
print(BMW.color)
print(BMW.wheelNum)
可以单独为每一个对象添加属性,只供这个对象使用
class Person(object):
def run(self):
print("person is running")
p = Person()
p.name = "zhangsan"
p.age = 12
p.run()
print(p.name)
print(p.age)
p2 = Person()
p2.sex = "girl"
print(p2.sex)
# print(p2.name)# 错误 单独为每一个对象添加属性,只能供这个对象使用
7.4 self (init,new,del,str,id)
1. 理解self
所谓的self,可以理解为自己
可以把self当做C++中类里面的this指针一样理解,就是对象自身的意思
某个对象调用其方法时,python解释器会把这个对象作为第一个参数传递给self,所以开发者只需要传递后面的参数即可
定义方法时,需要传递一个参数self:
def toot(self):#self 可以不写self,方法中必须至少有一个参数。第一个参数表示当前对象。名字随便取,但是习惯都写self
2._init_()方法:初始化
在上一小节的demo中,我们已经给BMW这个对象添加了2个属性,wheelNum(车的轮胎数量)以及color(车的颜色),试想如果再次创建一个对象的话,肯定也需要进行添加属性,显然这样做很费事,那么有没有办法能够在创建对象的时候,就顺便把车这个对象的属性给设置呢?
__init__方法在每个对象创建时都要调用一次
-
init()方法,在创建一个对象时默认被调用,不需要手动调用
-
init(self)中,默认有1个参数名字为self,如果在创建对象时传递了2个实参,那么__init__(self)中出了self作为第一个形参外还需要2个形参,例如__init__(self,x,y)
-
init(self)中的self参数,不需要开发者传递,python解释器会自动把当前的对象引用传递进去
-
init方法不会在堆中开辟空间
-
如果重新定义了init函数,加了其他参数的话,在创建该类对象时,就需要传递相对应的参数了。
-
__init__完成对象的初始化操作,在对象被创建完成之后,立刻被调用执行,隐式调用,创建对象时的参数要跟init方法的参数保持一致
-
__init__只是完成了初始化的功能,并不是构造器
-
__init__方法可以像普通方法一样被调用
p.__init__()# 很少人这么干
1.使用方式
def 类名:
#初始化函数,用来完成一些默认的设定
def __init__():pass
2._init_()方法的调用
# 定义汽车类
class Car:
def __init__(self):
self.wheelNum = 4
self.color = '蓝色'
def move(self):
print('车在跑,目标:夏威夷')
# 创建对象
BMW = Car()
print('车的颜色为:%s'%BMW.color)
print('车轮胎数量为:%d'%BMW.wheelNum)
# 当创建Car对象后,在没有调用__init__()方法的前提下,BMW就默认拥有了2个属性wheelNum和color,原因是__init__()方法是在创建对象后,就立刻被默认调用了
既然在创建完对象后_init_()方法已经被默认的执行了,那么能否让对象在调用_init_()方法的时候传递一些参数呢?如果可以,那怎样传递呢?
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def run(self):
print("person is running")
p = Person("zhangsan",12)
# p.name = "zhangsan"
# p.age = 12
p.run()
print(p.name)
print(p.age)
p2 = Person("lisi",13)
p2.sex = "girl"
print(p2.name)
print(p2.sex)
注意:_init_()方法也可为参数设置默认值
class Person(object):
def __init__(self, name="abc", age=13):
self.name = name
self.age = age
def run(self):
print("person is running")
p = Person("zhangsan",12)
# p.name = "zhangsan"
# p.age = 12
p.run()
print(p.name)
print(p.age)
p2 = Person("lisi",13)
p2.sex = "girl"
print(p2.name)
print(p2.sex)
p3=Person()
print(p3.name)
print(p3.age)
person is running
zhangsan
12
lisi
girl
abc
13
3.__new__方法:构造器
-
__new__至少要有一个参数cls,代表要实例化的类,此参数在实例化时由Python解释器自动提供
-
__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类__new__出来的实例,或者直接是object的__new__出来的实例
-
__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值
-
我们可以将类比作制造商,__new__方法就是前期的原材料购买环节,__init__方法就是在有原材料的基础上,加工,初始化商品环节
-
每次默认调用的构造方法是new,init可以完成一些参数的赋值等一些基本的初始化工作
-
new方法的参数列表和创建对象时的参数列表应该一致。
-
__new__是构造方法,创建对象的是,首先调用的是new方法,new方法必须要有返回值(返回当前创建好的对象),参数必须跟创建对象传递的参数一致
-
无论什么情况,init和new方法的参数都要保持一致
-
注意:每个方法里都要有init和new,但init和new方法可以不写,它会默认调用父类object中init和new方法
class object: def __init__(self): # known special case of object.__init__ """ Initialize self. See help(type(self)) for accurate signature. """ pass @staticmethod # known case of __new__ def __new__(cls, *more): # known special case of object.__new__ """ Create and return a new object. See help(type) for accurate signature. """ pass
实例:
class Person(object):
def __init__(self, name="abcd", age=20):
print(self.name)
self.name = "abcd"
self.age = 20
def __new__(cls,name,age):
cls.name=name
cls.age=age
return object.__new__(cls)
def run(self):
print("person is running")
p = Person("zhangsan",12)
print(p.name)
zhangsan
abcd
1) 每次创建对象的时候会默认先执行__new__方法,再执行__init__方法
2) 对象的属性的赋值操作一般会在__init__方法中,可以使用__new__创建对象,使用init来进行赋值
class Person(object):
def __init__(self, name="abcd", age=20):
self.name = name
self.age = age
def __new__(cls,name,age):
return object.__new__(cls)
def run(self):
print("person is running")
p = Person("zhangsan",12)
print(p.name)
print(p.age)
p.run()
#-------------
zhangsan
12
person is running
4.init和new的调用顺序
每次创建对象的时候会默认先执行__new__方法,再执行__init__方法
class Person(object):
def __init__(self, name="abcd", age=20):
print("person init")
self.name = name
self.age = age
def __new__(cls,name,age):
print("person new")
return object.__new__(cls)
def run(self):
print("%s is running"%self.name)
p = Person("zhangsan",12)
print(p.name)
p1 = Person("lisi",20)
--------------------------
person new
person init
zhangsan
person new
person init
4.str()
和Java中的toString类似
class Person(object):
def __init__(self, name="abcd", age=20):
print("person init")
self.name = name
self.age = age
def __new__(cls,name,age):
print("person new")
return object.__new__(cls)
def __str__(self):
return "haha"
def run(self):
print("%s is running"%self.name)
p = Person("zhangsan",12)
print(p.name)
p1 = Person("lisi",20)
print(p1)
------------------------
person new
person init
zhangsan
person new
person init
haha
5.__del__方法
创建对象后,python解释器默认调用__init__()方法;
当删除一个对象时,python解释器也会默认调用一个方法,这个方法为_del_()方法
当内存中构建一个对象数据的时候回调_init_()方法,
当内存中销毁(释放)一个对象时回调__del__()方法
class Person(object):
def __init__(self, name="abcd", age=20):
print("person init")
self.name = name
self.age = age
def __new__(cls,name,age):
print("person new")
return object.__new__(cls)
def __str__(self):
return "haha"
def __del__(self):
print("del...")
def run(self):
print("%s is running"%self.name)
p = Person("zhangsan",12)
print(p.name)
p1 = Person("lisi",20)
print(p1)
------------------
person new
person init
zhangsan
person new
person init
haha
del...
del...
如果同一个类的多个对象时,del 对象名, 指挥减少堆中的这个类的计数器,计数器为0时才真正的调用__del__方法。
当有1个变量保存了对象的引用时,此对象的引用计数就会加1
当使用del删除变量指向的对象时,如果对象的引用计数不是1,比如3,那么此时只会让这个引用计数减1,即变为2,当再次调用del时,变为1,如果再调用1次del,此时会真的把对象进行删除
import time
class Animal(object):
# 初始化方法
# 创建完对象后会自动被调用
def __init__(self, name):
print('__init__方法被调用')
self.__name = name
# 析构方法
# 当对象被删除时,会自动被调用
def __del__(self):
print("__del__方法被调用")
print("%s对象马上被干掉了..." % self.__name)
# 创建对象
dog = Animal("哈皮狗")
# 删除对象
del dog
cat = Animal("波斯猫") # # 引用计数加1 现在为1
cat2 = cat # 引用计数加1 现在为2
cat3 = cat # 引用计数加1 现在为3
print("---马上 删除cat对象")
del cat # 引用计数-1
print("---马上 删除cat2对象")
del cat2 # 引用计数-1
print("---马上 删除cat3对象")
del cat3
print("程序2秒钟后结束")
time.sleep(2)
-----------------------------------------------
__init__方法被调用
__del__方法被调用
哈皮狗对象马上被干掉了...
__init__方法被调用
---马上 删除cat对象
---马上 删除cat2对象
---马上 删除cat3对象
__del__方法被调用
波斯猫对象马上被干掉了...
程序2秒钟后结束
6.打印id()
使用id()可以查看对象在内存中的地址
class Animal(object):
# 初始化方法
# 创建完对象后会自动被调用
def __init__(self, name):
print('__init__方法被调用')
self.__name = name
# 析构方法
# 当对象被删除时,会自动被调用
def __del__(self):
print("__del__方法被调用")
# 创建对象
dog = Animal("哈皮狗")
print(id(dog))
cat = Animal("波斯猫")
cat2 = cat
cat3 = Animal("波斯猫")
print(id(cat))
print(id(cat2))
-----------------------
__init__方法被调用
2126402287656
__init__方法被调用
__init__方法被调用
2126402287824
2126402287824
__del__方法被调用
__del__方法被调用
__del__方法被调用
7.str()
在python中方法名如果是_xxxx_()的,那么就有特殊的功能,因此叫做“魔法”方法
当使用print输出对象的时候,只要自己定义了_str_(self)方法,那么就会打印从在这个方法中return的数据
如果在类中自己定义了str方法的话,就会在用print打印该对象的时候打印自己实现的逻辑,如果自己没有定义的话,就会打印这个对象的内存地址。
class Car:
def __init__(self, newWheelNum, newColor):
self.wheelNum = newWheelNum
self.color = newColor
def __str__(self):
msg = "嘿,我的颜色是" + self.color + "我有" + str(self.wheelNum) + "个轮胎..."
return msg
def move(self):
print('车在跑,目标:夏威夷')
BMW = Car(4, "白色")
print(BMW)
--------------------------------------
嘿,我的颜色是白色我有4个轮胎...
总结
| 特殊方法名 | 默认的参数 | 功能描述 |
|---|---|---|
| init() | self | 已经创建了对象,初始化对象回调方法 |
| str() | self | 和toString |
| del() | self | 对象回收时候回调 |
| new() | cls | 对象创建的回调方法 |
7.5 封装
如果有一个对象,当需要对其进行修改属性时,有2种方法
- 对象名.属性名 = 数据 ---->直接修改
- 对象名.方法名() ---->间接修改
为了更好的保存属性安全,即不能随意修改,一般的处理方式为
- 将属性定义为私有属性(__属性名)
- 添加一个可以调用的方法,供调用
class Person(object):
def __init__(self, name, age):
self.__name = name # 私有属性
self.age = age
def show(self):
print(self.__name, self.age)
self.__test()
def getName(self):
return self.__name
def setName(self, name):
self.__name = name
def __test(self): # 私有方法
print("test")
p = Person("abc", 20)
p.setName("lisi")
print(p.getName())
p.show()
- Python中没有像C++中public和private这些关键字来区别公有属性和私有属性
- 它是以属性命名方式来区分,如果在属性名前面加了2个下划线’__’,则表明该属性是私有属性,否则为公有属性(方法也是一样,方法名前面加了2个下划线的话表示该方法是私有的,否则为公有的)。
- 私有的属性,不能通过对象直接访问,但是可以通过方法访问。
- 私有的方法,不能通过对象直接访问。
- 私有的属性、方法,不会被子类继承,也不能被访问。
- 一般情况下,私有的属性、方法都是不对外公布的,往往用来做内部的事情起到安全的作用。
7.6 继承
在程序中,继承描述的是事物之间的所属关系,例如猫和狗都属于动物,程序中便可以描述为猫和狗继承自动物
同理,波斯猫和巴厘猫都继承自猫,而沙皮狗和斑点狗都继承自狗
继承相关知识
-
定义子类的时候在类名后加(父类类名)
-
Python中支持多继承 子类有多个父类,父类的属性和方法子类都会继承
-
多继承中,如果多个父类中有同名的方法,那么通过子类调用此方法时,会调用哪一个?
会调用父类类名列表中的第一个父类的方法。
-
用子类类名.mro 可以查看子类对象查找类时的先后顺序
class Animal(object):
def __init__(self, name):
self.name = name
def run(self):
print(self.name + " is running")
class Cat(Animal):
def __init__(self, name, type):
super().__init__(name)
self.type = type
cat = Cat("lele", "cat")
cat.run()
-------------------
lele is running
继承示例
# 定义一个父类,如下:
class Cat(object):
def __init__(self, name, color="白色"):
self.name = name
self.color = color
def run(self):
print("%s--在跑" % self.name)
# 定义一个子类,继承Cat类,如下:
class Bosi(Cat):
def setNewName(self, newName):
self.name = newName
def eat(self):
print("%s--在吃" % self.name)
bs = Bosi("印度猫")
print('bs的名字为:%s' % bs.name)
print('bs的颜色为:%s' % bs.color)
bs.eat()
bs.setNewName('波斯')
bs.run()
----------------
bs的名字为:印度猫
bs的颜色为:白色
印度猫--在吃
波斯--在跑
说明:
虽然子类没有定义__init__方法,但是父类有,所以在子类继承父类的时候这个方法就被继承了,所以只要创建Bosi的对象,就默认执行了那个继承过来的__init__方法
总结
- 子类在继承的时候,在定义类时,小括号()中为父类的名字
- 父类的属性、方法,会被继承给子类
- 私有的属性、方法,不会被子类继承,也不能被访问
注意点
class Animal(object):
def __init__(self, name='动物', color='白色'):
self.__name = name
self.color = color
def __test(self):
print(self.__name)
print(self.color)
def test(self):
print(self.__name)
print(self.color)
class Dog(Animal):
def dogTest1(self):
# print(self.__name)
# 不能访问到父类的私有属性
print(self.color)
def dogTest2(self):
# self.__test()
# 不能访问父类中的私有方法
self.test()
A = Animal()
# print(A.__name)
# 程序出现异常,不能访问私有属性
print(A.color)
# A.__test()
# 程序出现异常,不能访问私有方法
A.test()
print("------分割线-----")
D = Dog(name="小花狗", color="黄色")
D.dogTest1()
D.dogTest2()
-------------------------------------
白色
动物
白色
------分割线-----
黄色
小花狗
黄色
1、私有的属性,不能通过对象直接访问,但是可以通过方法访问
2、私有的方法,不能通过对象直接访问
3、私有的属性、方法,不会被子类继承,也不能被访问
4、一般情况下,私有的属性、方法都是不对外公布的,往往用来做内部的事情,起到安全的作用
7.7 多继承
1.多继承
-
定义子类的时候在类名后加(父类类名)
-
Python中支持多继承 子类有多个父类,父类的属性和方法子类都会继承
-
多继承中,如果多个父类中有同名的方法,那么通过子类调用此方法时,会调用哪一个?
会调用父类类名列表中的第一个父类的方法。
-
用子类类名.mro 可以查看子类对象查找类时的先后顺序
Python中多继承的格式如下:
# 定义一个父类
class A:
def printA(self):
print('----A----')
# 定义一个父类
class B:
def printB(self):
print('----B----')
# 定义一个子类,继承自A、B
class C(A, B):
def printC(self):
print('----C----')
obj_C = C()
obj_C.printA()
obj_C.printB()
运行结果:
----A----
----B----
说明:
1、python中是可以多继承的
2、父类中的方法、属性,子类会继承
如果在上面的多继承例子中,如果父类A和父类B中,有一个同名的方法,那么通过子类去调用的时候,调用哪个?
# coding=utf-8
class base(object):
def test(self):
print('----base test----')
class A(base):
def test(self):
print('----A test----')
# 定义一个父类
class B(base):
def test(self):# 重写父类的方法
print('----B test----')
# 定义一个子类,继承自A、B
class C(A, B):
pass
obj_C = C()
obj_C.test()
print(C.__mro__) # 可以查看C类的对象搜索方法时的先后顺序,C3算法得到一个元组
运行结果:
----A test----
(<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class '__main__.base'>, <class 'object'>)
- 多继承中,如果多个父类中有同名的方法,那么通过子类调用此方法时, 会调用父类类名列表(A,B)中的第一个父类的方法。
- 用子类类名._mro_ 可以查看子类对象查找类时的先后顺序
2.重写
所谓重写,就是子类中,有一个和父类相同名字的方法,在子类中的方法会覆盖掉父类中同名的方法
3.调用父类的方法
方式一:父类类名.方法名
方式二:super(父类类名).方法名
方式三:super().方法名
# coding=utf-8
class Cat(object):
def __init__(self, name):
self.name = name
self.color = 'yellow'
class Bosi(Cat):
def __init__(self, name):
# 调用父类的__init__方法1(python2)
# Cat.__init__(self,name)
# 调用父类的__init__方法2
# super(Bosi,self).__init__(name)
# 调用父类的__init__方法3
super().__init__(name)
def getName(self):
return self.name
bosi = Bosi('xiaohua')
print(bosi.name)
print(bosi.color)
-----------------------
xiaohua
yellow
7.8 多态
多态的概念是应用于Java和C#这一类强类型语言中,而Python崇尚“鸭子类型”。
所谓多态:定义时的类型和运行时的类型不一样,此时就成为多态
由于python中方法的参数列表中不需要指定参数的类型,所以不能实现父类引用指向子类对象,不是真正意义上的多态。
# python鸭子模型
class F1(object):
def show(self):
print("F1 show")
class S1(F1):
def show(self):
print("S1 show")
class S2(F1):
def show(self):
print("S2 show")
# 单独定义一个类,没有继承F1
class S3:
def show(self):
print("S3 show")
def Func(obj):
obj.show()
s1 = S1()
s2 = S2()
f1 = F1()
s3 = S3()
Func(s1)# 在Func函数中传入S1类的对象s1,执行 S1 的show方法,结果:S1 show
Func(s2)
Func(f1)
Func(s3)
运行结果:
S1 show
S2 show
F1 show
S3 show
7.9 类属性与实例属性
在前面的例子中我们接触到的就是实例属性(对象属性),顾名思义,类属性就是类对象所拥有的属性,它被所有类对象的实例对象所共有,在内存中只存在一个副本,这个和C++,java中类的静态成员变量有点类似。对于公有的类属性,在类外可以通过类对象和实例对象访问。
类属性:所属类,这个类下所有的对象都可以共享这个类属性。 相当于java中静态属性。
定义在类中,方法外就是类属性,方法内的就是实例属性
类属性在内存中只存在一个副本,被这个类的所有对象共享。
比如:
class Person{
public static String name="abc"
}
1.类属性
class Person(object):
# 公有类属性
name = "zhangsan"
# 私有的类属性
__age = 30
def __init__(self, name, age):
self.name = name
self.__age = age
def getAge(self):
return self.__age
print(Person.name)
# print(Person.getAge())
p = Person("lisi", 100)
Person.name="wangwu"
print(p.name)
print(p.getAge())
print(Person.name)
print(p.__age) #错误,不能在类外通过实例对象访问私有的类属性
print(Person.__age) #错误,不能在类外通过类对象访问私有的类属性
-------------------------
zhangsan
lisi
100
wangwu
2.实例属性(对象属性)
class People(object):
address = '山东' # 类属性
def __init__(self):
self.name = 'xiaowang' # 实例属性
self.age = 20 # 实例属性
p = People()
p.age = 12 # 实例属性
print(p.address) # 正确
print(p.name) # 正确
print(p.age) # 正确
print(People.address) # 正确
# print(People.name) # 错误 name是实例属性,属于一个对象,不能使用类名调用,应该使用对象来调用
# print(People.age) # 错误 age是实例属性,属于一个对象,不能使用类名调用,应该使用对象来调用
--------------------------------
山东
xiaowang
12
山东
3.通过实例(对象)去修改类属性
class People(object):
country = 'china' # 类属性
print(People.country)
p = People()
print(p.country)
p.country = 'japan'
print(p.country) # 实例属性会屏蔽掉同名的类属性
print(People.country)
del p.country # 删除实例属性
print(p.country)
----------------------------------
china
china
japan
china
china
总结
如果需要在类外修改类属性,必须通过类对象去引用然后进行修改。如果通过实例对象去引用,会产生一个同名的实例属性,这种方式修改的是实例属性,不会影响到类属性,并且之后如果通过实例对象去引用该名称的属性,实例属性会强制屏蔽掉类属性,即引用的是实例属性,除非删除了该实例属性。
| 属性叫法 | 变量叫法 | 描述 |
|---|---|---|
| 类属性(私有和公有) | 类变量 | 所有对象共享同一份类属性。 |
| 实例属性(私/公) | 成员变量 | 每个不同对象,有不一样值的实例属性 |
7.10 类方法和静态方法
1.类方法
是类对象所拥有的方法,需要用修饰器@classmethod来标识其为类方法,对于类方法,第一个参数必须是类对象,一般以cls作为第一个参数(当然可以用其他名称的变量作为其第一个参数,但是大部分人都习惯以cls作为第一个参数的名字,就最好用cls了),能够通过实例对象和类对象去访问。
class Person(object):
name = "zhangsan"
__age = 30
def __init__(self, name, age):
self.name = name
self.__age = age
# 类方法,用classmethod来进行修饰
@classmethod
def getAge(cls):
return cls.__age # 返回类属性age30
def getAge2(self):
return self.__age # 返回实例属性age
print(Person.name)
print(Person.getAge()) # 类方法可以通过类对象引用
p = Person("lisi", 100)
Person.name = "wangwu"
print(p.name)
print(p.getAge()) # 类方法可以用过实例对象引用
print(p.getAge2())
print(Person.name)
----------------------------------------------
zhangsan
30
lisi
30
100
wangwu
类方法还有一个用途就是可以对类属性进行修改:
class People(object):
country = 'china'
# 类方法,用classmethod来进行修饰
@classmethod
def getCountry(cls):
return cls.country
@classmethod
def setCountry(cls, country):
cls.country = country
p = People()
print(p.getCountry()) # 可以通过实例对象引用
print(People.getCountry()) # 可以通过类对象引用
p.setCountry('japan')
print(p.getCountry())
print(People.getCountry())
------------------------------------------
china
china
japan
japan
结果显示在用类方法对类属性修改之后,通过类对象和实例对象访问都发生了改变
2.静态方法
需要通过修饰器@staticmethod来进行修饰,静态方法不需要多定义参数,静态方法中可以不传参数
class People(object):
country = 'china'
@staticmethod # 静态方法
def getCountry():
return People.country
print(People.getCountry())# china
总结
从类方法和实例方法以及静态方法的定义形式就可以看出来,类方法的第一个参数是类对象cls,那么通过cls引用的必定是类对象的属性和方法;
而实例方法的第一个参数是实例对象self,那么通过self引用的可能是类属性、也有可能是实例属性(这个需要具体分析),不过在存在相同名称的类属性和实例属性的情况下,实例属性优先级更高。
静态方法中不需要额外定义参数,因此在静态方法中引用类属性的话,必须通过类对象来引用
| 方法类别 | 语法 | 描述 |
|---|---|---|
| 类方法 | @classmethod | 第一个形参cls。默认传递 |
| 静态方法 | @staticmethod | 没有默认传递的形参 |
| 对象方法(成员方法) | def 方法名 | 第一个形参self ,默认传递 |
总结

八,设计模式
8.1 单例模式
1. 单例是什么
举个常见的单例模式例子,我们日常使用的电脑上都有一个回收站,在整个操作系统中,回收站只能有一个实例,整个系统都使用这个唯一的实例,而且回收站自行提供自己的实例。因此回收站是单例模式的应用。
确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个类称为单例类,单例模式是一种对象创建型模式。
2.创建单例-保证只有1个对象
# 实例化一个单例
class Singleton(object):
__instance = None
def __new__(cls, age, name):
# 如果类数字能够__instance没有或者没有赋值
# 那么就创建一个对象,并且赋值为这个对象的引用,保证下次调用这个方法时
# 能够知道之前已经创建过对象了,这样就保证了只有1个对象
if not cls.__instance:
cls.__instance = object.__new__(cls)
return cls.__instance
a = Singleton(18, "bin")
b = Singleton(8, "bin")
print(id(a))
print(id(b))
a.age = 19 # 给a指向的对象添加一个属性
print(b.age) # 获取b指向的对象的age属性
----------------------------------------------
1763383070504
1763383070504
19
3.创建单例时,只执行1次__init__方法
# 实例化一个单例
class Singleton:
__instance = None
__First_init = True
def __init__(self, name):
if self.__First_init:
self.__First_init = False
self.name = name
print("init...")
def __new__(cls,name):
print("new...")
if not cls.__instance:
cls.__instance = object.__new__(cls)
return cls.__instance
def run(self):
print("running...")
s = Singleton("zhangsan")
s1 = Singleton("lisi")# 不能赋值
print(id(s))
print(id(s1))
print(s.name)
print(s1.name)
-------------------------------
new...
init...
new...
3193738032464
3193738032464
zhangsan
zhangsan
8.2 工厂模式
工厂模式是我们最常用的实例化对象模式了,是用工厂方法代替new操作的一种模式。虽然这样做,可能多做一些工作,但会给你系统带来更大的可扩展性和尽量少的修改量(可维护性)。
1.简单工厂模式
Simple Factory模式不是独立的设计模式,他是Factory Method模式的一种简单的、特殊的实现。他也被称为静态工厂模式,通常创建者的创建方法被设计为static方便调用。
1、静态的工厂类
2、用全局函数改写工厂类
class Person(object):
def __init__(self, name):
self.name = name
def work(self, type):
print(self.name, "开始工作了")
# person完成work,需要使用一把斧头
# axe = StoneAxe()
# axe = SteelAxe()
axe = Factory.getAxe(type)
axe.cut_tree()
class Axe(object):
def __init__(self, name):
self.name = name
def cut_tree(self):
print("使用", self.name, "砍树")
class StoneAxe(Axe):
def __init__(self):
pass
def cut_tree(self):
print("使用石斧开始砍树")
class SteelAxe(Axe):
def __init__(self):
pass
def cut_tree(self):
print("使用钢斧开始砍树")
class DianJu(Axe):
def __init__(self):
pass
def cut_tree(self):
print("使用电锯开始砍树")
# 工厂类
class Factory(object):
@staticmethod
def getAxe(type):
if "stone" == type:
return StoneAxe()
elif "steel" == type:
return SteelAxe()
elif "dianju" == type:
return DianJu()
else:
print("参数有问题")
p = Person("zhangsan")
p.work("stone")
p = Person("lisi")
p.work("steel")
p = Person("wangwu")
p.work("dianju")
------------------------------------
zhangsan 开始工作了
使用石斧开始砍树
lisi 开始工作了
使用钢斧开始砍树
wangwu 开始工作了
使用电锯开始砍树
2.工厂方法模式
工厂方法模式去掉了简单工厂模式中工厂方法的静态方法,使得它可以被子类继承。对于python来说,就是工厂类被具体工厂继承。这样在简单工厂模式里集中在工厂方法上的压力可以由工厂方法模式里不同的工厂子类来分担。
抽象的工厂类提供了一个创建对象的方法,也叫作工厂方法。
-
抽象工厂角色(Factory): 这是工厂方法模式的核心,它与应用程序无关。是具体工厂角色必须实现的接口或者必须继承的父类。
-
具体工厂角色(Stone_Axe_Factory,Steel_Axe_Factory):它含有和具体业务逻辑有关的代码。由应用程序调用以创建对应的具体产品的对象。
-
抽象产品角色(Axe):它是具体产品继承的父类或者是实现的接口。在python中抽象产品一般为父类。
-
具体产品角色(Stone_Axe,Steel_Axe):具体工厂角色所创建的对象就是此角色的实例。由一个具体类实现。
class Person(object):
def __init__(self, name):
self.name = name
def work(self, axe):
print(self.name, "开始工作了")
axe.cut_tree()
# 抽象产品角色
class Axe(object):
def __init__(self, name):
self.name = name
def cut_tree(self):
print("使用", self.name, "砍树")
# 具体产品角色
class StoneAxe(Axe):
def __init__(self):
pass
def cut_tree(self):
print("使用石斧开始砍树")
# 具体产品角色
class SteelAxe(Axe):
def __init__(self):
pass
def cut_tree(self):
print("使用钢斧开始砍树")
# 工厂类
class Factory:
def create_Axe(self):
pass
# 具体工厂角色
class Stone_Axe_Factory(Factory):
def create_Axe(self):
return StoneAxe()
# 具体工厂角色
class Steel_Axe_Factory(Factory):
def create_Axe(self):
return SteelAxe()
p = Person("zhangsan")
p.work(Stone_Axe_Factory().create_Axe())
p = Person("lisi")
p.work(Steel_Axe_Factory().create_Axe())
-------------------------------------------
zhangsan 开始工作了
使用石斧开始砍树
lisi 开始工作了
使用钢斧开始砍树
九,异常
9.1 异常简介
看如下示例:
print("test1")
open("123.txt","r")
print("test2")
运行结果:
test1
Traceback (most recent call last):
File "D:/PycharmProjects/PythonTest/com/cw/python/01HelloWorld.py", line 2, in <module>
open("123.txt","r")
FileNotFoundError: [Errno 2] No such file or directory: '123.txt'
说明:
打开一个不存在的文件123.txt,当找不到123.txt 文件时,就会抛出给我们一个IOError类型的错误,No such file or directory:123.txt (没有123.txt这样的文件或目录)
异常:
当Python检测到一个错误时,解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的"异常"
9.2 捕获异常
1.捕获异常 try…except…
try:
print("test1")
open("123.txt", "r")
print("test2")
except FileNotFoundError as msg:
print("发生异常了")
print(msg)
# print(FileNotFoundError) # <class 'FileNotFoundError'>
else:
print("异常处理完了")
finally:
print("finally...")
print("test3")
运行结果:
test1
发生异常了
[Errno 2] No such file or directory: '123.txt'
finally...
test3
当把open("123.txt", "r")注释掉时,结果变为:
test1
test2
异常处理完了
finally...
test3
此程序看不到任何错误,因为用except 捕获到了FileNotFoundError异常,并添加了处理的方法
小总结:
- 把可能出现问题的代码,放在try中
- 把处理异常的代码,放在except中
- 不管怎么样finally都会执行,无论是否发生异常
- else是在没有出现异常时执行
2.except捕获多个异常
当捕获多个异常时,可以把要捕获的异常的名字,放到except 后,并使用元组的方式仅进行存储
实际开发中,捕获多个异常的方式
try:
print("test1")
open("123.txt", "r")
print(1 / 0)
print("test2")
# except Exception as e:
# print(e)
# print("Exception")
except (FileNotFoundError,ZeroDivisionError) as msg: # 先写小异常再写大异常
print("发生异常了")
print(msg)
# print(FileNotFoundError) # <class 'FileNotFoundError'>
# except ZeroDivisionError as msg2:
# print(msg2)
else:
print("异常处理完了")
finally:
print("finally...")
print("test3")
------------------------------------------------
test1
发生异常了
[Errno 2] No such file or directory: '123.txt'
finally...
test3
3.获取异常的信息描述

4.捕获所有异常

5.else
在if中,它的作用是当条件不满足时执行的实行;同样在try…except…中也是如此,即如果没有捕获到异常,那么就执行else中的事情
try:
num = 100
print(num)
except NameError as errorMsg:
print('产生错误了:%s' % errorMsg)
else:
print('没有捕获到异常,真高兴')
--------------------------------
100
没有捕获到异常,真高兴
6.try…finally…
try…finally…语句用来表达这样的情况:
在程序中,如果一个段代码必须要执行,即无论异常是否产生都要执行,那么此时就需要使用finally。 比如文件关闭,释放锁,把数据库连接返还给连接池等
import time
try:
f = open('test.txt')
try:
while True:
content = f.readline()
if len(content) == 0:
break
time.sleep(2)
print(content)
except TypeError as ex: # 如果在读取文件的过程中,产生了异常,那么就会捕获到#比如 按下了 ctrl+c
pass
finally:
f.close()
print('关闭文件')
except:
print("没有这个文件")
运行结果:
hello world
world china
python
关闭文件
说明:
test.txt文件中每一行数据打印,但是我有意在每打印一行之前用time.sleep方法暂停2秒钟。这样做的原因是让程序运行得慢一些。在程序运行的时候,按Ctrl+c中断(取消)程序。
我们可以观察到KeyboardInterrupt异常被触发,程序退出。但是在程序退出之前,finally从句仍然被执行,把文件关闭。
9.3 异常的传递
1. try嵌套中
import time
try:
f = open('test.txt')
try:
while True:
content = f.readline()
if len(content) == 0:
break
time.sleep(2)
print(content)
finally:
f.close()
print('关闭文件')
except:
print("没有这个文件")
hello world
world china
python
关闭文件
2.函数嵌套调用中
def test1():
print("----test1-1----")
print(num)
print("----test1-2----")
def test2():
print("----test2-1----")
test1()
print("----test2-2----")
def test3():
try:
print("----test3-1----")
test1()
print("----test3-2----")
except Exception as result:
print("捕获到了异常,信息是:%s" % result)
print("----test3-2----")
test3()
print("------华丽的分割线-----")
test2()
运行结果:
Traceback (most recent call last):
----test3-2----
File "D:/PycharmProjects/PythonTest/com/cw/python/01HelloWorld.py", line 25, in <module>
test2()
----test3-1----
File "D:/PycharmProjects/PythonTest/com/cw/python/01HelloWorld.py", line 9, in test2
----test1-1----
test1()
捕获到了异常,信息是:name 'num' is not defined
File "D:/PycharmProjects/PythonTest/com/cw/python/01HelloWorld.py", line 3, in test1
------华丽的分割线-----
print(num)
----test2-1----
NameError: name 'num' is not defined
----test1-1----
总结:
如果try嵌套,那么如果里面的try没有捕获到这个异常,那么外面的try会接收到这个异常,然后进行处理,如果外边的try依然没有捕获到,那么再进行传递。。。
如果一个异常是在一个函数中产生的,例如函数A---->函数B---->函数C,而异常是在函数C中产生的,那么如果函数C中没有对这个异常进行处理,那么这个异常会传递到函数B中,如果函数B有异常处理那么就会按照函数B的处理方式进行执行;如果函数B也没有异常处理,那么这个异常会继续传递,以此类推。。。如果所有的函数都没有处理,那么此时就会进行异常的默认处理,即通常见到的那样
注意观察上图中,当调用test3函数时,在test1函数内部产生了异常,此异常被传递到test3函数中完成了异常处理,而当异常处理完后,并没有返回到函数test1中进行执行,而是在函数test3中继续执行
9.4 自定义异常
可以用raise语句来引发一个异常。异常/错误对象必须有一个名字,且它们应是Error或Exception类的子类
(1) 继承Exception
(2) 编写异常类处理
(3) 可定义错误信息:定义属性:msg=“xxxxxx”
# 自定义异常
class ShortInputError(Exception):
def __init__(self, length, atleast):
# super().__init__()
self.length = length
self.atleast = atleast
def func():
str = input("请输入参数")
try:
if len(str) < 3:
raise ShortInputError(len(str), 3) # raise引发一个你定义的异常
except ShortInputError as result:
print("字符串的长度是%d,至少需要长度是:%d" % (result.length, result.atleast))
else:
print('没有异常发生.')
finally:
print("执行完毕")
func()
运行结果:
请输入参数69
字符串的长度是2,至少需要长度是:3
执行完毕
请输入参数333
没有异常发生.
执行完毕
注意
以上程序中,关于代码#super().init()的说明
这一行代码,可以调用也可以不调用,建议调用,因为__init__方法往往是用来对创建完的对象进行初始化工作,如果在子类中重写了父类的__init__方法,即意味着父类中的很多初始化工作没有做,这样就不保证程序的稳定了,所以在以后的开发中,如果重写了父类的__init__方法,最好是先调用父类的这个方法,然后再添加自己的功能
9.5 异常处理中抛出异常
class Test(object):
def __init__(self, switch):
self.switch = switch # 开关
def calc(self, a, b):
try:
return a / b
except Exception as result:
if self.switch:
print("捕获开启,已经捕获到了异常,信息如下:")
print(result)
else: # 重新抛出这个异常,此时就不会被这个异常处理给捕获到,从而触发默认的异常处理
raise
a = Test(True)
a.calc(11, 0)
print("----------------------华丽的分割线----------------")
a.switch = False
a.calc(11, 0)
-------------------------------
Traceback (most recent call last):
File "D:/PycharmProjects/PythonTest/com/cw/python/01HelloWorld.py", line 20, in <module>
a.calc(11, 0)
File "D:/PycharmProjects/PythonTest/com/cw/python/01HelloWorld.py", line 7, in calc
return a / b
ZeroDivisionError: division by zero
捕获开启,已经捕获到了异常,信息如下:
division by zero
----------------------华丽的分割线----------------
总结
try:是异常捕获开始代码,try放在特别关心的那段代码前面
pass:如果这行代码出现了异常,那么后面的代码不会运行
pass2
pass3
except 异常的类型 as ex: 捕获某种类型的异常
except…多个except。按照顺序依次比对类型
else:没有异常时执行
finally:不管有没有异常都会执行

十,Python模块及安装
10.1 模块的使用及安装
1.Python中的模块
在Python中有一个概念叫做模块(module),这个和C语言中的头文件以及Java中的jar包很类似,比如在Python中要调用sqrt函数,必须用import关键字引入math这个模块,下面就来了解一下Python中的模块。
说的通俗点:模块就好比是工具包,要想使用这个工具包中的工具(就好比函数),就需要导入这个模块
2.import
在Python中用关键字import来引入某个模块,比如要引用模块math,就可以在文件最开始的地方用import
math来引入。
形如:
import module1,mudule2...
当解释器遇到import语句,如果模块在当前的搜索路径就会被导入。
在调用math模块中的函数时,必须这样引用:
模块名.函数名
import math
print sqrt(2) #这样会报错
print math.sqrt(2) #这样才能正确输出结果
有时候我们只需要用到模块中的某个函数,只需要引入该函数即可,此时可以用下面方法实现:
3.from…import
Python的from语句让你从模块中导入一个指定的部分到当前命名空间中
语法如下:
from modname import name1[, name2[, ... nameN]]
例如,要导入模块math的sqrt函数,使用如下语句:
from math import sqrt
print(sqrt(9))
print(math.sqrt(9))# 报错
注意:不会把整个math模块导入到当前的命名空间中,它只会将math里的sqrt单个引入
4.from … import *
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
注意:这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
5.定位模块
当你导入一个模块,Python解析器对模块位置的搜索顺序是:
1、当前目录
2、如果不在当前目录,Python则搜索在shell变量PYTHONPATH下的每个目录。
3、如果都找不到,Python会查看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/
4、模块搜索路径存储在system模块的sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
总结:模块导入的几种方式
模块导入的方式
1.import 模块名称
使用时必须加上模块名称math.sqrt()
2.from 模块名称 import 模块中的内容
3.from 模块名称 import *
导入模块中所有的内容
4.form 包名+模块名称 import *
import 包名+模块名称 as 别名
import math
from math import sqrt
from math import *
import math as m
5.安装模块
conda create -n py2 python=2.7
conda install 模块
pip install 模块
pymysql
numpy
1.方式一:pip安装
# win+r 进入cmd命令行
# 安装模块
C:Userscw>pip install pymysql
Collecting pymysql
Downloading https://files.pythonhosted.org/packages/ed/39/15045ae46f2a123019aa968dfcba0396c161c20f855f11dea6796bcaae95/PyMySQL-0.9.3-py2.py3-none-any.whl (47kB)
100% |████████████████████████████████| 51kB 113kB/s
distributed 1.21.8 requires msgpack, which is not installed.
Installing collected packages: pymysql
Successfully installed pymysql-0.9.3
# 卸载模块
C:Userscw>pip uninstall pymysql
Uninstalling PyMySQL-0.9.3:
Would remove:
d:anaconda3libsite-packagespymysql-0.9.3.dist-info*
d:anaconda3libsite-packagespymysql*
Proceed (y/n)? y
Successfully uninstalled PyMySQL-0.9.3
此时即可导入pymysql了
import pymysql

2.方式二:conda
C:Userscw>conda install numpy
10.2 模块制作
1.定义自己的模块
在Python中,每个Python文件都可以作为一个模块,模块的名字就是文件的名字。
比如有这样一个文件test.py,在test.py中定义了函数add
def add(a,b):
return a+b
def sub(a,b):
return a-b
def mul(a,b):
return a*b
def div(a,b):
return a/b
2.调用自己定义的模块
那么在其他文件中就可以先import MyMath,然后通过MyMath.add(a,b)来调用了,当然也可以通过from MyMath import *来引入
# import com.cw.MyMath as m
# print(m.add(1,2))
import MyMath # 报错不用管
print(MyMath.add(1,2))
print(MyMath.sub(1,2))
print(MyMath.div(1,2))
print(MyMath.mul(1,2))
3.测试模块
在实际开中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息,例如:
def add(a, b):
return a + b # 用来进行测试
ret = add(12, 22)
print('int test.py file,,,,12+22=%d' % ret)
如果此时,在其他py文件中引入了此文件的话,想想看,测试的那段代码是否也会执行呢!
import test
result = test.add(11, 22)
print(result)
至此,可发现test.py中的测试代码,应该是单独执行test.py文件时才应该执行的,不应该是其他的文件中引用而执行
为了解决这个问题,python在执行一个文件时有个变量_name_
4.模块中的_all_
可以根据__name__变量的结果能够判断出,是直接执行的python脚本还是被引入执行的,从而能够有选择性的执行测试代码
# MyMath.py
__all__=["add","sub"]#可以设置哪些方法可以被执行
def add(a,b):
return a+b
def sub(a,b):
return a-b
def mul(a,b):
return a*b
def div(a,b):
return a/b
# 测试
from com.cw.test.MyMath import *
print(add(1,2))
print(sub(1,2))
print(div(1,2))# 报错
10.3 Python中的模块
1.python中的包
1.1 包就是一个目录
1.2 把多个py文件放到同一个文件夹下
1.3 使用import 文件夹.模块 的方式导入
python3可以导入包,python2不行。
1.4 使用from 文件夹 import 模块 的方式导入
python3可以导入包,python2不行。
1.5 在包的文件夹下创建__init__.py文件。
在python2中:有一个目录,并且目录下有一个__init__.py的文件。才叫包。
虽然文件内容没有,但是python2可以用了
有_init_.py文件在python3中没有有错。以后我们都在包的目录下新建一个init文件。
1.6 在_init_.py文件中写入
from . import 模块1
from . import 模块2
那么可以使用import 文件夹 导入
1.7 也可以使用from 文件夹 import 模块 的方式导入
总结:
包将有联系的模块组织在一起,即放到同一个文件夹下,并且在这个文件夹创建一个名字为_init_.py 文件,那么这个文件夹就称之为包
有效避免模块名称冲突问题,让应用组织结构更加清晰
2._init_.py文件有什么用
_init_.py 控制着包的导入行为
2.1 _init_.py为空
仅仅是把这个包导入,不会导入包中的模块
2.2 (了解)可以在_init_.py文件中编写内容
可以在这个文件中编写语句,当导入时,这些语句就会被执行
_init_.py文件
#com.cw.python下的__init__.py文件
print("init package")
from os import *
#module.py
from com.cw.python import *
print(listdir())
结果:
init package
['module.py', '__init__.py', '__pycache__']
10.4 模块的发布
1.mymodule目录结构体如下:
.
├── setup.py
├── suba
│ ├── aa.py
│ ├── bb.py
│ └── init.py
└── subb
├── cc.py
├── dd.py
└── init.py
2.编辑setup.py文件
py_modules需指明所需包含的py文件
from distutils.core import setup
setup(name="压缩包的名字", version="1.0", description="描述", author="作者", py_modules=['suba.aa', 'suba.bb', 'subb.cc', 'subb.dd'])
3.构建模块
python setup.py build
4.生成发布压缩包
python setup.py sdist
10.5 模块安装、使用
1.安装的方式
1、找到模块的压缩包(拷贝到其他地方)
2、解压
3、进入文件夹
4、执行命令python setup.py install
注意:如果在install的时候,执行目录安装,可以使用python setup.py install --prefix=安装路径
conda create -n py2 python=2.7
2.模块的引入
在程序中,使用from import 即可完成对安装的模块使用
from 模块名 import 模块名或者*
总结

十一,列表推导式

-
给程序传参数
import sys print(sys.argv)
-
列表推导式
-
所谓的列表推导式,就是指的轻量级循环创建列表:
a = [i for i in range(1,10)] b= [11 for i in range(1,10)] [(1,1),(2,4),(3,9),(4,16).....] -
在循环的过程中使用if 来确定 列表中元素的条件
a = [i for i in range(1,10) if i%2==0] -
2个for循环
a=[(i,j) for i in range(1,5) for j in range(6,10)] -
3个for循环
a= [(x,y,z) for x in range(2) for y in range(2) for z in range(2)]
-
-
set:集合类型
| 列表(list) | a=[] | 先后顺序,有下标位[index],可以重复,可变类型 |
|---|---|---|
| 元组(tuple) | a=() | 有先后顺序,有下标位,元素可以重复,不可变(只能查) |
| 字典(dict) | a={key:value} | 没有先后顺序,没有下标,key不可重复,value可以,可变 |
| 集合(set) | a=set() | 没有先后顺序,没有下标,不可重复,可变类型 |
注意:使用set,可以快速的完成对list中的元素去重复的功能
# 创建列表
i = [i for i in range(1, 10)]
print(i)
i = [i for i in range(1, 10) if i % 2 == 0]
print(i)
i = [i for i in range(1, 10) if i % 2 == 0 if i > 5]
print(i)
# 创建元组
i = [(i, j) for i in range(1, 10) for j in range(1, 10)]
print(i)
i = [(i, j, k) for i in range(1, 10) for j in range(1, 10) for k in range(1, 10)]
print(i)
# 创建字典
i = [{i, j, k} for i in range(1, 10) for j in range(1, 10) for k in range(1, 10)]
print(i)
运行结果
[1, 2, 3, 4, 5, 6, 7, 8, 9]
[2, 4, 6, 8]
[6, 8]
[(1, 1), (1, 2), (1, 3), (1, 4), (1, 5), (1, 6), (1, 7), (1, 8), (1, 9), (2, 1), (2, 2), (2, 3), (2, 4), (2, 5), (2, 6), (2, 7), (2, 8), (2, 9), (3, 1), (3, 2), (3, 3), (3, 4), (3, 5), (3, 6), (3, 7), (3, 8), (3, 9), (4, 1), (4, 2), (4, 3), (4, 4), (4, 5), (4, 6), (4, 7), (4, 8), (4, 9), (5, 1), (5, 2), (5, 3), (5, 4), (5, 5), (5, 6), (5, 7), (5, 8), (5, 9), (6, 1), (6, 2), (6, 3), (6, 4), (6, 5), (6, 6), (6, 7), (6, 8), (6, 9), (7, 1), (7, 2), (7, 3), (7, 4), (7, 5), (7, 6), (7, 7), (7, 8), (7, 9), (8, 1), (8, 2), (8, 3), (8, 4), (8, 5), (8, 6), (8, 7), (8, 8), (8, 9), (9, 1), (9, 2), (9, 3), (9, 4), (9, 5), (9, 6), (9, 7), (9, 8), (9, 9)]
[(1, 1, 1), (1, 1, 2), (1, 1, 3), (1, 1, 4), (1, 1, 5), (1, 1, 6), (1, 1, 7), (1, 1, 8), (1, 1, 9), (1, 2, 1), (1, 2, 2), (1, 2, 3), (1, 2, 4), (1, 2, 5), (1, 2, 6), (1, 2, 7), (1, 2, 8), (1, 2, 9), (1, 3, 1), (1, 3, 2), (1, 3, 3), (1, 3, 4), (1, 3, 5), (1, 3, 6), (1, 3, 7), (1, 3, 8), (1, 3, 9), (1, 4, 1), (1, 4, 2), (1, 4, 3), (1, 4, 4), (1, 4, 5), (1, 4, 6), (1, 4, 7), (1, 4, 8), (1, 4, 9), (1, 5, 1), (1, 5, 2), (1, 5, 3), (1, 5, 4), (1, 5, 5), (1, 5, 6), (1, 5, 7), (1, 5, 8), (1, 5, 9), (1, 6, 1), (1, 6, 2), (1, 6, 3), (1, 6, 4), (1, 6, 5), (1, 6, 6), (1, 6, 7), (1, 6, 8), (1, 6, 9), (1, 7, 1), (1, 7, 2), (1, 7, 3), (1, 7, 4), (1, 7, 5), (1, 7, 6), (1, 7, 7), (1, 7, 8), (1, 7, 9), (1, 8, 1), (1, 8, 2), (1, 8, 3), (1, 8, 4), (1, 8, 5), (1, 8, 6), (1, 8, 7), (1, 8, 8), (1, 8, 9), (1, 9, 1), (1, 9, 2), (1, 9, 3), (1, 9, 4), (1, 9, 5), (1, 9, 6), (1, 9, 7), (1, 9, 8), (1, 9, 9), (2, 1, 1), (2, 1, 2), (2, 1, 3), (2, 1, 4), (2, 1, 5), (2, 1, 6), (2, 1, 7), (2, 1, 8), (2, 1, 9), (2, 2, 1), (2, 2, 2), (2, 2, 3), (2, 2, 4), (2, 2, 5), (2, 2, 6), (2, 2, 7), (2, 2, 8), (2, 2, 9), (2, 3, 1), (2, 3, 2), (2, 3, 3), (2, 3, 4), (2, 3, 5), (2, 3, 6), (2, 3, 7), (2, 3, 8), (2, 3, 9), (2, 4, 1), (2, 4, 2), (2, 4, 3), (2, 4, 4), (2, 4, 5), (2, 4, 6), (2, 4, 7), (2, 4, 8), (2, 4, 9), (2, 5, 1), (2, 5, 2), (2, 5, 3), (2, 5, 4), (2, 5, 5), (2, 5, 6), (2, 5, 7), (2, 5, 8), (2, 5, 9), (2, 6, 1), (2, 6, 2), (2, 6, 3), (2, 6, 4), (2, 6, 5), (2, 6, 6), (2, 6, 7), (2, 6, 8), (2, 6, 9), (2, 7, 1), (2, 7, 2), (2, 7, 3), (2, 7, 4), (2, 7, 5), (2, 7, 6), (2, 7, 7), (2, 7, 8), (2, 7, 9), (2, 8, 1), (2, 8, 2), (2, 8, 3), (2, 8, 4), (2, 8, 5), (2, 8, 6), (2, 8, 7), (2, 8, 8), (2, 8, 9), (2, 9, 1), (2, 9, 2), (2, 9, 3), (2, 9, 4), (2, 9, 5), (2, 9, 6), (2, 9, 7), (2, 9, 8), (2, 9, 9), (3, 1, 1), (3, 1, 2), (3, 1, 3), (3, 1, 4), (3, 1, 5), (3, 1, 6), (3, 1, 7), (3, 1, 8), (3, 1, 9), (3, 2, 1), (3, 2, 2), (3, 2, 3), (3, 2, 4), (3, 2, 5), (3, 2, 6), (3, 2, 7), (3, 2, 8), (3, 2, 9), (3, 3, 1), (3, 3, 2), (3, 3, 3), (3, 3, 4), (3, 3, 5), (3, 3, 6), (3, 3, 7), (3, 3, 8), (3, 3, 9), (3, 4, 1), (3, 4, 2), (3, 4, 3), (3, 4, 4), (3, 4, 5), (3, 4, 6), (3, 4, 7), (3, 4, 8), (3, 4, 9), (3, 5, 1), (3, 5, 2), (3, 5, 3), (3, 5, 4), (3, 5, 5), (3, 5, 6), (3, 5, 7), (3, 5, 8), (3, 5, 9), (3, 6, 1), (3, 6, 2), (3, 6, 3), (3, 6, 4), (3, 6, 5), (3, 6, 6), (3, 6, 7), (3, 6, 8), (3, 6, 9), (3, 7, 1), (3, 7, 2), (3, 7, 3), (3, 7, 4), (3, 7, 5), (3, 7, 6), (3, 7, 7), (3, 7, 8), (3, 7, 9), (3, 8, 1), (3, 8, 2), (3, 8, 3), (3, 8, 4), (3, 8, 5), (3, 8, 6), (3, 8, 7), (3, 8, 8), (3, 8, 9), (3, 9, 1), (3, 9, 2), (3, 9, 3), (3, 9, 4), (3, 9, 5), (3, 9, 6), (3, 9, 7), (3, 9, 8), (3, 9, 9), (4, 1, 1), (4, 1, 2), (4, 1, 3), (4, 1, 4), (4, 1, 5), (4, 1, 6), (4, 1, 7), (4, 1, 8), (4, 1, 9), (4, 2, 1), (4, 2, 2), (4, 2, 3), (4, 2, 4), (4, 2, 5), (4, 2, 6), (4, 2, 7), (4, 2, 8), (4, 2, 9), (4, 3, 1), (4, 3, 2), (4, 3, 3), (4, 3, 4), (4, 3, 5), (4, 3, 6), (4, 3, 7), (4, 3, 8), (4, 3, 9), (4, 4, 1), (4, 4, 2), (4, 4, 3), (4, 4, 4), (4, 4, 5), (4, 4, 6), (4, 4, 7), (4, 4, 8), (4, 4, 9), (4, 5, 1), (4, 5, 2), (4, 5, 3), (4, 5, 4), (4, 5, 5), (4, 5, 6), (4, 5, 7), (4, 5, 8), (4, 5, 9), (4, 6, 1), (4, 6, 2), (4, 6, 3), (4, 6, 4), (4, 6, 5), (4, 6, 6), (4, 6, 7), (4, 6, 8), (4, 6, 9), (4, 7, 1), (4, 7, 2), (4, 7, 3), (4, 7, 4), (4, 7, 5), (4, 7, 6), (4, 7, 7), (4, 7, 8), (4, 7, 9), (4, 8, 1), (4, 8, 2), (4, 8, 3), (4, 8, 4), (4, 8, 5), (4, 8, 6), (4, 8, 7), (4, 8, 8), (4, 8, 9), (4, 9, 1), (4, 9, 2), (4, 9, 3), (4, 9, 4), (4, 9, 5), (4, 9, 6), (4, 9, 7), (4, 9, 8), (4, 9, 9), (5, 1, 1), (5, 1, 2), (5, 1, 3), (5, 1, 4), (5, 1, 5), (5, 1, 6), (5, 1, 7), (5, 1, 8), (5, 1, 9), (5, 2, 1), (5, 2, 2), (5, 2, 3), (5, 2, 4), (5, 2, 5), (5, 2, 6), (5, 2, 7), (5, 2, 8), (5, 2, 9), (5, 3, 1), (5, 3, 2), (5, 3, 3), (5, 3, 4), (5, 3, 5), (5, 3, 6), (5, 3, 7), (5, 3, 8), (5, 3, 9), (5, 4, 1), (5, 4, 2), (5, 4, 3), (5, 4, 4), (5, 4, 5), (5, 4, 6), (5, 4, 7), (5, 4, 8), (5, 4, 9), (5, 5, 1), (5, 5, 2), (5, 5, 3), (5, 5, 4), (5, 5, 5), (5, 5, 6), (5, 5, 7), (5, 5, 8), (5, 5, 9), (5, 6, 1), (5, 6, 2), (5, 6, 3), (5, 6, 4), (5, 6, 5), (5, 6, 6), (5, 6, 7), (5, 6, 8), (5, 6, 9), (5, 7, 1), (5, 7, 2), (5, 7, 3), (5, 7, 4), (5, 7, 5), (5, 7, 6), (5, 7, 7), (5, 7, 8), (5, 7, 9), (5, 8, 1), (5, 8, 2), (5, 8, 3), (5, 8, 4), (5, 8, 5), (5, 8, 6), (5, 8, 7), (5, 8, 8), (5, 8, 9), (5, 9, 1), (5, 9, 2), (5, 9, 3), (5, 9, 4), (5, 9, 5), (5, 9, 6), (5, 9, 7), (5, 9, 8), (5, 9, 9), (6, 1, 1), (6, 1, 2), (6, 1, 3), (6, 1, 4), (6, 1, 5), (6, 1, 6), (6, 1, 7), (6, 1, 8), (6, 1, 9), (6, 2, 1), (6, 2, 2), (6, 2, 3), (6, 2, 4), (6, 2, 5), (6, 2, 6), (6, 2, 7), (6, 2, 8), (6, 2, 9), (6, 3, 1), (6, 3, 2), (6, 3, 3), (6, 3, 4), (6, 3, 5), (6, 3, 6), (6, 3, 7), (6, 3, 8), (6, 3, 9), (6, 4, 1), (6, 4, 2), (6, 4, 3), (6, 4, 4), (6, 4, 5), (6, 4, 6), (6, 4, 7), (6, 4, 8), (6, 4, 9), (6, 5, 1), (6, 5, 2), (6, 5, 3), (6, 5, 4), (6, 5, 5), (6, 5, 6), (6, 5, 7), (6, 5, 8), (6, 5, 9), (6, 6, 1), (6, 6, 2), (6, 6, 3), (6, 6, 4), (6, 6, 5), (6, 6, 6), (6, 6, 7), (6, 6, 8), (6, 6, 9), (6, 7, 1), (6, 7, 2), (6, 7, 3), (6, 7, 4), (6, 7, 5), (6, 7, 6), (6, 7, 7), (6, 7, 8), (6, 7, 9), (6, 8, 1), (6, 8, 2), (6, 8, 3), (6, 8, 4), (6, 8, 5), (6, 8, 6), (6, 8, 7), (6, 8, 8), (6, 8, 9), (6, 9, 1), (6, 9, 2), (6, 9, 3), (6, 9, 4), (6, 9, 5), (6, 9, 6), (6, 9, 7), (6, 9, 8), (6, 9, 9), (7, 1, 1), (7, 1, 2), (7, 1, 3), (7, 1, 4), (7, 1, 5), (7, 1, 6), (7, 1, 7), (7, 1, 8), (7, 1, 9), (7, 2, 1), (7, 2, 2), (7, 2, 3), (7, 2, 4), (7, 2, 5), (7, 2, 6), (7, 2, 7), (7, 2, 8), (7, 2, 9), (7, 3, 1), (7, 3, 2), (7, 3, 3), (7, 3, 4), (7, 3, 5), (7, 3, 6), (7, 3, 7), (7, 3, 8), (7, 3, 9), (7, 4, 1), (7, 4, 2), (7, 4, 3), (7, 4, 4), (7, 4, 5), (7, 4, 6), (7, 4, 7), (7, 4, 8), (7, 4, 9), (7, 5, 1), (7, 5, 2), (7, 5, 3), (7, 5, 4), (7, 5, 5), (7, 5, 6), (7, 5, 7), (7, 5, 8), (7, 5, 9), (7, 6, 1), (7, 6, 2), (7, 6, 3), (7, 6, 4), (7, 6, 5), (7, 6, 6), (7, 6, 7), (7, 6, 8), (7, 6, 9), (7, 7, 1), (7, 7, 2), (7, 7, 3), (7, 7, 4), (7, 7, 5), (7, 7, 6), (7, 7, 7), (7, 7, 8), (7, 7, 9), (7, 8, 1), (7, 8, 2), (7, 8, 3), (7, 8, 4), (7, 8, 5), (7, 8, 6), (7, 8, 7), (7, 8, 8), (7, 8, 9), (7, 9, 1), (7, 9, 2), (7, 9, 3), (7, 9, 4), (7, 9, 5), (7, 9, 6), (7, 9, 7), (7, 9, 8), (7, 9, 9), (8, 1, 1), (8, 1, 2), (8, 1, 3), (8, 1, 4), (8, 1, 5), (8, 1, 6), (8, 1, 7), (8, 1, 8), (8, 1, 9), (8, 2, 1), (8, 2, 2), (8, 2, 3), (8, 2, 4), (8, 2, 5), (8, 2, 6), (8, 2, 7), (8, 2, 8), (8, 2, 9), (8, 3, 1), (8, 3, 2), (8, 3, 3), (8, 3, 4), (8, 3, 5), (8, 3, 6), (8, 3, 7), (8, 3, 8), (8, 3, 9), (8, 4, 1), (8, 4, 2), (8, 4, 3), (8, 4, 4), (8, 4, 5), (8, 4, 6), (8, 4, 7), (8, 4, 8), (8, 4, 9), (8, 5, 1), (8, 5, 2), (8, 5, 3), (8, 5, 4), (8, 5, 5), (8, 5, 6), (8, 5, 7), (8, 5, 8), (8, 5, 9), (8, 6, 1), (8, 6, 2), (8, 6, 3), (8, 6, 4), (8, 6, 5), (8, 6, 6), (8, 6, 7), (8, 6, 8), (8, 6, 9), (8, 7, 1), (8, 7, 2), (8, 7, 3), (8, 7, 4), (8, 7, 5), (8, 7, 6), (8, 7, 7), (8, 7, 8), (8, 7, 9), (8, 8, 1), (8, 8, 2), (8, 8, 3), (8, 8, 4), (8, 8, 5), (8, 8, 6), (8, 8, 7), (8, 8, 8), (8, 8, 9), (8, 9, 1), (8, 9, 2), (8, 9, 3), (8, 9, 4), (8, 9, 5), (8, 9, 6), (8, 9, 7), (8, 9, 8), (8, 9, 9), (9, 1, 1), (9, 1, 2), (9, 1, 3), (9, 1, 4), (9, 1, 5), (9, 1, 6), (9, 1, 7), (9, 1, 8), (9, 1, 9), (9, 2, 1), (9, 2, 2), (9, 2, 3), (9, 2, 4), (9, 2, 5), (9, 2, 6), (9, 2, 7), (9, 2, 8), (9, 2, 9), (9, 3, 1), (9, 3, 2), (9, 3, 3), (9, 3, 4), (9, 3, 5), (9, 3, 6), (9, 3, 7), (9, 3, 8), (9, 3, 9), (9, 4, 1), (9, 4, 2), (9, 4, 3), (9, 4, 4), (9, 4, 5), (9, 4, 6), (9, 4, 7), (9, 4, 8), (9, 4, 9), (9, 5, 1), (9, 5, 2), (9, 5, 3), (9, 5, 4), (9, 5, 5), (9, 5, 6), (9, 5, 7), (9, 5, 8), (9, 5, 9), (9, 6, 1), (9, 6, 2), (9, 6, 3), (9, 6, 4), (9, 6, 5), (9, 6, 6), (9, 6, 7), (9, 6, 8), (9, 6, 9), (9, 7, 1), (9, 7, 2), (9, 7, 3), (9, 7, 4), (9, 7, 5), (9, 7, 6), (9, 7, 7), (9, 7, 8), (9, 7, 9), (9, 8, 1), (9, 8, 2), (9, 8, 3), (9, 8, 4), (9, 8, 5), (9, 8, 6), (9, 8, 7), (9, 8, 8), (9, 8, 9), (9, 9, 1), (9, 9, 2), (9, 9, 3), (9, 9, 4), (9, 9, 5), (9, 9, 6), (9, 9, 7), (9, 9, 8), (9, 9, 9)]
[{1}, {1, 2}, {1, 3}, {1, 4}, {1, 5}, {1, 6}, {1, 7}, {8, 1}, {1, 9}, {1, 2}, {1, 2}, {1, 2, 3}, {1, 2, 4}, {1, 2, 5}, {1, 2, 6}, {1, 2, 7}, {8, 1, 2}, {1, 2, 9}, {1, 3}, {1, 2, 3}, {1, 3}, {1, 3, 4}, {1, 3, 5}, {1, 3, 6}, {1, 3, 7}, {8, 1, 3}, {1, 3, 9}, {1, 4}, {1, 2, 4}, {1, 3, 4}, {1, 4}, {1, 4, 5}, {1, 4, 6}, {1, 4, 7}, {8, 1, 4}, {1, 4, 9}, {1, 5}, {1, 2, 5}, {1, 3, 5}, {1, 4, 5}, {1, 5}, {1, 5, 6}, {1, 5, 7}, {8, 1, 5}, {1, 5, 9}, {1, 6}, {1, 2, 6}, {1, 3, 6}, {1, 4, 6}, {1, 5, 6}, {1, 6}, {1, 6, 7}, {8, 1, 6}, {1, 6, 9}, {1, 7}, {1, 2, 7}, {1, 3, 7}, {1, 4, 7}, {1, 5, 7}, {1, 6, 7}, {1, 7}, {8, 1, 7}, {1, 9, 7}, {8, 1}, {8, 1, 2}, {8, 1, 3}, {8, 1, 4}, {8, 1, 5}, {8, 1, 6}, {8, 1, 7}, {8, 1}, {8, 1, 9}, {1, 9}, {1, 2, 9}, {1, 3, 9}, {1, 4, 9}, {1, 5, 9}, {1, 9, 6}, {1, 9, 7}, {8, 1, 9}, {1, 9}, {1, 2}, {1, 2}, {1, 2, 3}, {1, 2, 4}, {1, 2, 5}, {1, 2, 6}, {1, 2, 7}, {8, 1, 2}, {1, 2, 9}, {1, 2}, {2}, {2, 3}, {2, 4}, {2, 5}, {2, 6}, {2, 7}, {8, 2}, {9, 2}, {1, 2, 3}, {2, 3}, {2, 3}, {2, 3, 4}, {2, 3, 5}, {2, 3, 6}, {2, 3, 7}, {8, 2, 3}, {9, 2, 3}, {1, 2, 4}, {2, 4}, {2, 3, 4}, {2, 4}, {2, 4, 5}, {2, 4, 6}, {2, 4, 7}, {8, 2, 4}, {9, 2, 4}, {1, 2, 5}, {2, 5}, {2, 3, 5}, {2, 4, 5}, {2, 5}, {2, 5, 6}, {2, 5, 7}, {8, 2, 5}, {9, 2, 5}, {1, 2, 6}, {2, 6}, {2, 3, 6}, {2, 4, 6}, {2, 5, 6}, {2, 6}, {2, 6, 7}, {8, 2, 6}, {9, 2, 6}, {1, 2, 7}, {2, 7}, {2, 3, 7}, {2, 4, 7}, {2, 5, 7}, {2, 6, 7}, {2, 7}, {8, 2, 7}, {9, 2, 7}, {8, 1, 2}, {8, 2}, {8, 2, 3}, {8, 2, 4}, {8, 2, 5}, {8, 2, 6}, {8, 2, 7}, {8, 2}, {8, 9, 2}, {9, 2, 1}, {9, 2}, {9, 2, 3}, {9, 2, 4}, {9, 2, 5}, {9, 2, 6}, {9, 2, 7}, {8, 9, 2}, {9, 2}, {1, 3}, {1, 2, 3}, {1, 3}, {1, 3, 4}, {1, 3, 5}, {1, 3, 6}, {1, 3, 7}, {8, 1, 3}, {1, 3, 9}, {1, 2, 3}, {2, 3}, {2, 3}, {2, 3, 4}, {2, 3, 5}, {2, 3, 6}, {2, 3, 7}, {8, 2, 3}, {9, 2, 3}, {1, 3}, {2, 3}, {3}, {3, 4}, {3, 5}, {3, 6}, {3, 7}, {8, 3}, {9, 3}, {1, 3, 4}, {2, 3, 4}, {3, 4}, {3, 4}, {3, 4, 5}, {3, 4, 6}, {3, 4, 7}, {8, 3, 4}, {9, 3, 4}, {1, 3, 5}, {2, 3, 5}, {3, 5}, {3, 4, 5}, {3, 5}, {3, 5, 6}, {3, 5, 7}, {8, 3, 5}, {9, 3, 5}, {1, 3, 6}, {2, 3, 6}, {3, 6}, {3, 4, 6}, {3, 5, 6}, {3, 6}, {3, 6, 7}, {8, 3, 6}, {9, 3, 6}, {1, 3, 7}, {2, 3, 7}, {3, 7}, {3, 4, 7}, {3, 5, 7}, {3, 6, 7}, {3, 7}, {8, 3, 7}, {9, 3, 7}, {8, 1, 3}, {8, 2, 3}, {8, 3}, {8, 3, 4}, {8, 3, 5}, {8, 3, 6}, {8, 3, 7}, {8, 3}, {8, 9, 3}, {9, 3, 1}, {9, 2, 3}, {9, 3}, {9, 3, 4}, {9, 3, 5}, {9, 3, 6}, {9, 3, 7}, {8, 9, 3}, {9, 3}, {1, 4}, {1, 2, 4}, {1, 3, 4}, {1, 4}, {1, 4, 5}, {1, 4, 6}, {1, 4, 7}, {8, 1, 4}, {1, 4, 9}, {1, 2, 4}, {2, 4}, {2, 3, 4}, {2, 4}, {2, 4, 5}, {2, 4, 6}, {2, 4, 7}, {8, 2, 4}, {9, 2, 4}, {1, 3, 4}, {2, 3, 4}, {3, 4}, {3, 4}, {3, 4, 5}, {3, 4, 6}, {3, 4, 7}, {8, 3, 4}, {9, 3, 4}, {1, 4}, {2, 4}, {3, 4}, {4}, {4, 5}, {4, 6}, {4, 7}, {8, 4}, {9, 4}, {1, 4, 5}, {2, 4, 5}, {3, 4, 5}, {4, 5}, {4, 5}, {4, 5, 6}, {4, 5, 7}, {8, 4, 5}, {9, 4, 5}, {1, 4, 6}, {2, 4, 6}, {3, 4, 6}, {4, 6}, {4, 5, 6}, {4, 6}, {4, 6, 7}, {8, 4, 6}, {9, 4, 6}, {1, 4, 7}, {2, 4, 7}, {3, 4, 7}, {4, 7}, {4, 5, 7}, {4, 6, 7}, {4, 7}, {8, 4, 7}, {9, 4, 7}, {8, 1, 4}, {8, 2, 4}, {8, 3, 4}, {8, 4}, {8, 4, 5}, {8, 4, 6}, {8, 4, 7}, {8, 4}, {8, 9, 4}, {9, 4, 1}, {9, 2, 4}, {9, 3, 4}, {9, 4}, {9, 4, 5}, {9, 4, 6}, {9, 4, 7}, {8, 9, 4}, {9, 4}, {1, 5}, {1, 2, 5}, {1, 3, 5}, {1, 4, 5}, {1, 5}, {1, 5, 6}, {1, 5, 7}, {8, 1, 5}, {1, 5, 9}, {1, 2, 5}, {2, 5}, {2, 3, 5}, {2, 4, 5}, {2, 5}, {2, 5, 6}, {2, 5, 7}, {8, 2, 5}, {9, 2, 5}, {1, 3, 5}, {2, 3, 5}, {3, 5}, {3, 4, 5}, {3, 5}, {3, 5, 6}, {3, 5, 7}, {8, 3, 5}, {9, 3, 5}, {1, 4, 5}, {2, 4, 5}, {3, 4, 5}, {4, 5}, {4, 5}, {4, 5, 6}, {4, 5, 7}, {8, 4, 5}, {9, 4, 5}, {1, 5}, {2, 5}, {3, 5}, {4, 5}, {5}, {5, 6}, {5, 7}, {8, 5}, {9, 5}, {1, 5, 6}, {2, 5, 6}, {3, 5, 6}, {4, 5, 6}, {5, 6}, {5, 6}, {5, 6, 7}, {8, 5, 6}, {9, 5, 6}, {1, 5, 7}, {2, 5, 7}, {3, 5, 7}, {4, 5, 7}, {5, 7}, {5, 6, 7}, {5, 7}, {8, 5, 7}, {9, 5, 7}, {8, 1, 5}, {8, 2, 5}, {8, 3, 5}, {8, 4, 5}, {8, 5}, {8, 5, 6}, {8, 5, 7}, {8, 5}, {8, 9, 5}, {9, 5, 1}, {9, 2, 5}, {9, 3, 5}, {9, 4, 5}, {9, 5}, {9, 5, 6}, {9, 5, 7}, {8, 9, 5}, {9, 5}, {1, 6}, {1, 2, 6}, {1, 3, 6}, {1, 4, 6}, {1, 5, 6}, {1, 6}, {1, 6, 7}, {8, 1, 6}, {1, 6, 9}, {1, 2, 6}, {2, 6}, {2, 3, 6}, {2, 4, 6}, {2, 5, 6}, {2, 6}, {2, 6, 7}, {8, 2, 6}, {9, 2, 6}, {1, 3, 6}, {2, 3, 6}, {3, 6}, {3, 4, 6}, {3, 5, 6}, {3, 6}, {3, 6, 7}, {8, 3, 6}, {9, 3, 6}, {1, 4, 6}, {2, 4, 6}, {3, 4, 6}, {4, 6}, {4, 5, 6}, {4, 6}, {4, 6, 7}, {8, 4, 6}, {9, 4, 6}, {1, 5, 6}, {2, 5, 6}, {3, 5, 6}, {4, 5, 6}, {5, 6}, {5, 6}, {5, 6, 7}, {8, 5, 6}, {9, 5, 6}, {1, 6}, {2, 6}, {3, 6}, {4, 6}, {5, 6}, {6}, {6, 7}, {8, 6}, {9, 6}, {1, 6, 7}, {2, 6, 7}, {3, 6, 7}, {4, 6, 7}, {5, 6, 7}, {6, 7}, {6, 7}, {8, 6, 7}, {9, 6, 7}, {8, 1, 6}, {8, 2, 6}, {8, 3, 6}, {8, 4, 6}, {8, 5, 6}, {8, 6}, {8, 6, 7}, {8, 6}, {8, 9, 6}, {9, 6, 1}, {9, 2, 6}, {9, 3, 6}, {9, 4, 6}, {9, 5, 6}, {9, 6}, {9, 6, 7}, {8, 9, 6}, {9, 6}, {1, 7}, {1, 2, 7}, {1, 3, 7}, {1, 4, 7}, {1, 5, 7}, {1, 6, 7}, {1, 7}, {8, 1, 7}, {1, 9, 7}, {1, 2, 7}, {2, 7}, {2, 3, 7}, {2, 4, 7}, {2, 5, 7}, {2, 6, 7}, {2, 7}, {8, 2, 7}, {9, 2, 7}, {1, 3, 7}, {2, 3, 7}, {3, 7}, {3, 4, 7}, {3, 5, 7}, {3, 6, 7}, {3, 7}, {8, 3, 7}, {9, 3, 7}, {1, 4, 7}, {2, 4, 7}, {3, 4, 7}, {4, 7}, {4, 5, 7}, {4, 6, 7}, {4, 7}, {8, 4, 7}, {9, 4, 7}, {1, 5, 7}, {2, 5, 7}, {3, 5, 7}, {4, 5, 7}, {5, 7}, {5, 6, 7}, {5, 7}, {8, 5, 7}, {9, 5, 7}, {1, 6, 7}, {2, 6, 7}, {3, 6, 7}, {4, 6, 7}, {5, 6, 7}, {6, 7}, {6, 7}, {8, 6, 7}, {9, 6, 7}, {1, 7}, {2, 7}, {3, 7}, {4, 7}, {5, 7}, {6, 7}, {7}, {8, 7}, {9, 7}, {8, 1, 7}, {8, 2, 7}, {8, 3, 7}, {8, 4, 7}, {8, 5, 7}, {8, 6, 7}, {8, 7}, {8, 7}, {8, 9, 7}, {9, 1, 7}, {9, 2, 7}, {9, 3, 7}, {9, 4, 7}, {9, 5, 7}, {9, 6, 7}, {9, 7}, {8, 9, 7}, {9, 7}, {8, 1}, {8, 1, 2}, {8, 1, 3}, {8, 1, 4}, {8, 1, 5}, {8, 1, 6}, {8, 1, 7}, {8, 1}, {8, 1, 9}, {8, 1, 2}, {8, 2}, {8, 2, 3}, {8, 2, 4}, {8, 2, 5}, {8, 2, 6}, {8, 2, 7}, {8, 2}, {8, 9, 2}, {8, 1, 3}, {8, 2, 3}, {8, 3}, {8, 3, 4}, {8, 3, 5}, {8, 3, 6}, {8, 3, 7}, {8, 3}, {8, 9, 3}, {8, 1, 4}, {8, 2, 4}, {8, 3, 4}, {8, 4}, {8, 4, 5}, {8, 4, 6}, {8, 4, 7}, {8, 4}, {8, 9, 4}, {8, 1, 5}, {8, 2, 5}, {8, 3, 5}, {8, 4, 5}, {8, 5}, {8, 5, 6}, {8, 5, 7}, {8, 5}, {8, 9, 5}, {8, 1, 6}, {8, 2, 6}, {8, 3, 6}, {8, 4, 6}, {8, 5, 6}, {8, 6}, {8, 6, 7}, {8, 6}, {8, 9, 6}, {8, 1, 7}, {8, 2, 7}, {8, 3, 7}, {8, 4, 7}, {8, 5, 7}, {8, 6, 7}, {8, 7}, {8, 7}, {8, 9, 7}, {8, 1}, {8, 2}, {8, 3}, {8, 4}, {8, 5}, {8, 6}, {8, 7}, {8}, {8, 9}, {8, 9, 1}, {8, 9, 2}, {8, 9, 3}, {8, 9, 4}, {8, 9, 5}, {8, 9, 6}, {8, 9, 7}, {8, 9}, {8, 9}, {9, 1}, {9, 2, 1}, {9, 3, 1}, {9, 4, 1}, {9, 5, 1}, {9, 1, 6}, {9, 1, 7}, {8, 9, 1}, {9, 1}, {9, 2, 1}, {9, 2}, {9, 2, 3}, {9, 2, 4}, {9, 2, 5}, {9, 2, 6}, {9, 2, 7}, {8, 9, 2}, {9, 2}, {9, 3, 1}, {9, 2, 3}, {9, 3}, {9, 3, 4}, {9, 3, 5}, {9, 3, 6}, {9, 3, 7}, {8, 9, 3}, {9, 3}, {9, 4, 1}, {9, 2, 4}, {9, 3, 4}, {9, 4}, {9, 4, 5}, {9, 4, 6}, {9, 4, 7}, {8, 9, 4}, {9, 4}, {9, 5, 1}, {9, 2, 5}, {9, 3, 5}, {9, 4, 5}, {9, 5}, {9, 5, 6}, {9, 5, 7}, {8, 9, 5}, {9, 5}, {9, 6, 1}, {9, 2, 6}, {9, 3, 6}, {9, 4, 6}, {9, 5, 6}, {9, 6}, {9, 6, 7}, {8, 9, 6}, {9, 6}, {9, 1, 7}, {9, 2, 7}, {9, 3, 7}, {9, 4, 7}, {9, 5, 7}, {9, 6, 7}, {9, 7}, {8, 9, 7}, {9, 7}, {8, 9, 1}, {8, 9, 2}, {8, 9, 3}, {8, 9, 4}, {8, 9, 5}, {8, 9, 6}, {8, 9, 7}, {8, 9}, {8, 9}, {9, 1}, {9, 2}, {9, 3}, {9, 4}, {9, 5}, {9, 6}, {9, 7}, {8, 9}, {9}]
十二,python数据库操作
from pymysql import *
conn = connect("localhost", "root", "123456", "demo", 3306) # 建立连接
cur = conn.cursor() # 游标
# 查询
# count = cur.execute("select * from emp") # 执行sql 返回影响的行数
# print(count)
# result = cur.fetchall() # 抓取所有查询结果
# for i in result:
# print(i)
# result2 = cur.fetchone() # 抓取一条查询结果
# print(result2)
# result2 = cur.fetchmany(5) # 抓取指定个数的查询结果
# print(result2)
# 添加记录
# count = cur.execute("insert into emp(empno,ename) values(1111,'abcd')")
count = cur.execute("insert into emp(empno,ename) values(%d,%s)"%(2222,"'aaaa'"))
print(count)
conn.commit()# 不写这一行则数据库不会修改
conn.close()

十三,Python科学计算类库:Numpy
13.1 Numpy介绍
在使用numpy之前,要先在cmd 中进行安装:pip install numpy
1.Numpy是什么
NumPy(Numerical Python的缩写)是一个开源的Python科学计算库。使用NumPy,就可以很自然地使用数组和矩阵。 NumPy包含很多实用的数学函数,涵盖线性代数运算、傅里叶变换和随机数生成等功能。
这个库的前身是1995年就开始开发的一个用于数组运算的库。经过了长时间的发展,基本上成了绝大部分Python科学计算的基础包,当然也包括所有提供Python接口的深度学习框架。
2.为什么使用Numpy
a) 便捷:
对于同样的数值计算任务,使用NumPy要比直接编写Python代码便捷得多。这是因为NumPy能够直接对数组和矩阵进行操作,可以省略很多循环语句,其众多的数学函数也会让编写代码的工作轻松许多。
b) 性能:
NumPy中数组的存储效率和输入输出性能均远远优于Python中等价的基本数据结构(如嵌套的list容器)。其能够提升的性能是与数组中元素的数目成比例的。对于大型数组的运算,使用NumPy的确很有优势。对于TB级的大文件,NumPy使用内存映射文件来处理,以达到最优的数据读写性能。
c) 高效:
NumPy的大部分代码都是用C语言写成的,这使得NumPy比纯Python代码高效得多。
当然,NumPy也有其不足之处,由于NumPy使用内存映射文件以达到最优的数据读写性能,而内存的大小限制了其对TB级大文件的处理;此外,NumPy数组的通用性不及Python提供的list容器。因此,在科学计算之外的领域,NumPy的优势也就不那么明显。
13.2 Numpy的安装
(1)官网安装。http://www.numpy.org/。
(2)pip 安装。pip install numpy。
(3)LFD安装,针对windows用户http://www.lfd.uci.edu/~gohlke/pythonlibs/。
(4)Anaconda安装(推荐),Anaconda里面集成了很多关于python科学计算的第三方库,主要是安装方便。下载地址:https://www.anaconda.com/download/。
13.3 numpy 基础
NumPy的主要对象是同种元素的多维数组。这是一个所有的元素都是一种类型。
在NumPy中维度(dimensions)叫做轴(axes),轴的个数叫做秩(rank)。
NumPy的数组类被称作 ndarray(矩阵也叫数组) 。通常被称作数组。
常用的ndarray对象属性有:
ndarray.ndim(数组轴的个数,轴的个数被称作秩),
ndarray.shape(数组的维度。这是一个指示数组在每个维度上大小的整数元组。
例如一个n行m列的矩阵,它的shape属性将是(2,3),这个元组的长度显然是秩,即维度或者ndim属性),ndarray.size(数组元素的总个数,等于shape属性中元组元素的乘积),ndarray.dtype(一个用来描述数组中元素类型的对象,可以通过创造或指定dtype使用标准Python类型。另外NumPy提供它自己的数据类型)。
Numpy的数据类型


例1
import numpy as np
a = np.dtype(np.int_) # np.int64, np.float32 …
print(a)
a = np.dtype(np.int64) # np.int64, np.float32 …
print(a)
int32
int64
Numpy内置的特征码

int8, int16, int32,int64 可以由字符串’i1’, ‘i2’,’i4’, ‘i8’代替,其余的以此类推。
import numpy as np
a = np.dtype("i8") # ’f8’, ‘i4’’c16’,’a30’(30个字符的字符串), ‘>i4’…
print(a)
----------------------------
int64
可以指明数据类型在内存中的字节序,’>’表示按大端的方式存储,’<’表示按小端的方式存储,’=’表示数据按硬件默认方式存储。大端或小端存储只影响数据在底层内存中存储时字节的存储顺序,在我们实际使用python进行科学计算时,一般不需要考虑该存储顺序。
13.4 创建数组并查看其属性
1.用np.array从python列表和元组创建数组
import numpy as np
# 创建矩阵
array = np.array([1, 2, 3])
print(array.ndim) # 1 轴的个数
print(array.shape) #(3,) 轴上元素的个数
print(array.size) # 3
print(array.dtype)
array = np.array([[1, 2, 3], [4, 5, 6]])
print(array.ndim) # 2
print(array.shape) # (2,3)
print(array.size) # 2*3=6
print(array.dtype)
array = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]], [[9, 10], [11, 12]]])
print(array)
print(array.ndim) # 看中括号的层次关系,层次最深的就是维度 如[[]]即为二维 [[[[]]]]为四维
print(array.shape) # 先去掉最外层括号,有3个,再去掉次层括号,有2个,最后去掉最内层括号 有2个 所以shape为 (3,2,2)
print(array.size) # 3*2*2=12
print(array.dtype)
-----------------------------------------
1
(3,)
3
int32
2
(2, 3)
6
int32
[[[ 1 2]
[ 3 4]]
[[ 5 6]
[ 7 8]]
[[ 9 10]
[11 12]]]
3
(3, 2, 2)
12
int32
2.用np.arange().reshape()创建数组
import numpy as np
# 使用range创建数组
array = np.arange(1, 10).reshape(3, 3)# 创建3行3列的二维数组
print(array)
print(array.ndim)
print(array.shape)
# reshape中三个值的乘积必须精确等于arange中表示的范围 如下 2*2*3=12
array = np.arange(1, 13).reshape(2, 2, 3)# 最外层[]两个元素 次层2个元素 内层3个元素
print(array)
print(array.ndim)
print(array.shape)
-----------------------------------
[[1 2 3]
[4 5 6]
[7 8 9]]
2
(3, 3)
[[[ 1 2 3]
[ 4 5 6]]
[[ 7 8 9]
[10 11 12]]]
3
(2, 2, 3)
3.通过随机数生成多维数组
# 使用随机数生成矩阵
array = np.random.randint(1, 10, 12).reshape(2, 3, 2) # randint(low, high, size, dtype='l')
print(array)
array = np.random.rand(9).reshape(3, 3) # rand()生成均匀分布的伪随机数。分布在(0~1)之间
print(array)
array = np.random.randn(9).reshape(3, 3) # randn()生成标准正态分布的伪随机数(均值为0,方差为1)
print(array)
-------------------------------
[[[6 9]
[4 7]
[5 5]]
[[2 9]
[6 4]
[5 2]]]
[[0.63475604 0.05673834 0.32402837]
[0.76103155 0.74267171 0.80222977]
[0.22673878 0.15828813 0.54700497]]
[[ 0.45916843 1.00521985 0.59412181]
[ 0.38550176 0.95307819 -0.25702815]
[ 1.12107842 0.17128489 -1.16217769]]
4.通过固定值生成数组
import numpy as np
# 通过固定值生成数组
array = np.empty(9).reshape(3, 3)
print(array)
array = np.ones(9).reshape(3, 3)# 生成元素都是1的列表
print(array)
array = np.zeros(9).reshape(3, 3)# 生成元素都是0的列表
print(array)
-------------------------------------
[[1.69122046e-306 4.00550303e-307 5.84131119e-308]
[1.69122046e-306 1.05700260e-307 1.69121096e-306]
[1.06811015e-306 1.24611470e-306 2.64123653e-313]]
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
13.5 常用函数
import numpy as np
array = np.random.randint(1, 10, 9).reshape(3, 3)
print(array)
print(np.where(array > 5, array, 0))# 将大于5的值留下来,小于5的用0代替
print(array[2][2])
------------------------------------------
[[6 7 2]
[7 8 7]
[4 6 4]]
[[6 7 0]
[7 8 7]
[0 6 0]]
4
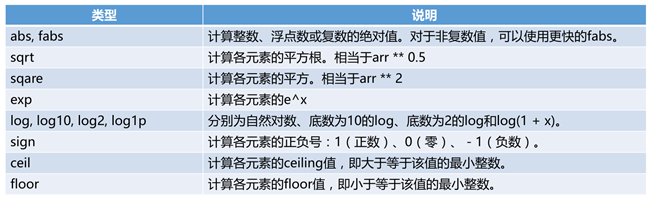
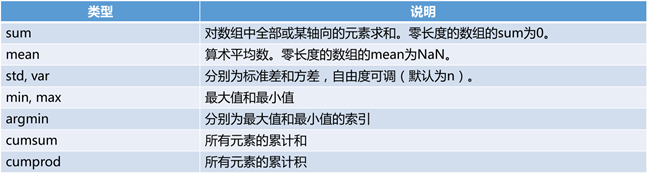

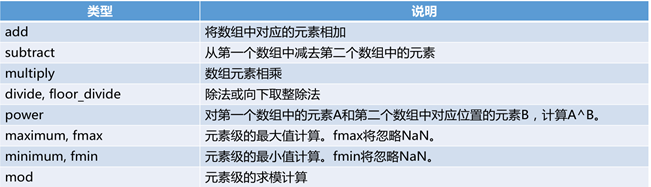


13.6 索引,切片和迭代
1.可切片对象的索引方式
包括:正索引和负索引两部分,如下图所示,以a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]为例:

2.Python切片操作的一般方式
一个完整的切片表达式包含两个“:”,用于分隔三个参数(start_index、end_index、step),当只有一个“:”时,默认第三个参数step=1。
切片操作基本表达式:object[start_index:end_index:step]
-
step:正负数均可,其绝对值大小决定了切取数据时的‘‘步长”,而正负号决定了“切取方向”,正表示“从左往右”取值,负表示“从右往左”取值。当step省略时,默认为1,即从左往右以增量1取值。“切取方向非常重要!”“切取方向非常重要!”“切取方向非常重要!”,重要的事情说三遍!
-
start_index:表示起始索引(包含该索引本身);该参数省略时,表示从对象“端点”开始取值,至于是从“起点”还是从“终点”开始,则由step参数的正负决定,step为正从“起点”开始,为负从“终点”开始。
-
end_index:表示终止索引(不包含该索引本身);该参数省略时,表示一直取到数据“端点”,至于是到“起点”还是到“终点”,同样由step参数的正负决定,step为正时直到“终点”,为负时直到“起点”。
3.Python切片操作详细例子
以下示例均以列表a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]为例:
1. 切取单个值
>>>a[0]
>>>0
>>>a[-4]
>>>6
2. 切取完整对象
>>>a[:] #从左往右
>>> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>>a[::]#从左往右
>>> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>>a[::-1]#从右往左
>>> [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
3. start_index和end_index全为正(+)索引的情况
>>>a[1:6]
>>> [1, 2, 3, 4, 5]
step=1,从左往右取值,start_index=1到end_index=6同样表示从左往右取值。
>>>a[1:6:-1]
>>> []
输出为空列表,说明没取到数据。
step=-1,决定了从右往左取值,而start_index=1到end_index=6决定了从左往右取值,两者矛盾,所以为空。
>>>a[6:1]
>>> []
同样输出为空列表。
step=1,决定了从左往右取值,而start_index=6到end_index=1决定了从右往左取值,两者矛盾,所以为空。
>>>a[:6]
>>> [0, 1, 2, 3, 4, 5]
step=1,从左往右取值,从“起点”开始一直取到end_index=6。
>>>a[:6:-1]
>>> [9, 8, 7]
step=-1,从右往左取值,从“终点”开始一直取到end_index=6。
>>>a[6:]
>>> [6, 7, 8, 9]
step=1,从左往右取值,从start_index=6开始,一直取到“终点”。
>>>a[6::-1]
>>> [6, 5, 4, 3, 2, 1, 0]
step=-1,从右往左取值,从start_index=6开始,一直取到“起点”。
4. start_index和end_index全为负(-)索引的情况
>>>a[-1:-6]
>>> []
step=1,从左往右取值,而start_index=-1到end_index=-6决定了从右往左取值,两者矛盾,所以为空。
索引-1在-6的右边(如上图)
>>>a[-1:-6:-1]
>>> [9, 8, 7, 6, 5]
step=-1,从右往左取值,start_index=-1到end_index=-6同样是从右往左取值。
索引-1在6的右边(如上图)
>>>a[-6:-1]
>>> [4, 5, 6, 7, 8]
step=1,从左往右取值,而start_index=-6到end_index=-1同样是从左往右取值。
索引-6在-1的左边(如上图)
>>>a[:-6]
>>> [0, 1, 2, 3]
step=1,从左往右取值,从“起点”开始一直取到end_index=-6。
>>>a[:-6:-1]
>>> [9, 8, 7, 6, 5]
step=-1,从右往左取值,从“终点”开始一直取到end_index=-6。
>>>a[-6:]
>>> [4, 5, 6, 7, 8, 9]
step=1,从左往右取值,从start_index=-6开始,一直取到“终点”。
>>>a[-6::-1]
>>> [4, 3, 2, 1, 0]
step=-1,从右往左取值,从start_index=-6开始,一直取到“起点”。
5. start_index和end_index正(+)负(-)混合索引的情况
>>>a[1:-6]
>>> [1, 2, 3]
start_index=1在end_index=-6的左边,因此从左往右取值,而step=1同样决定了从左往右取值,因此结果正确
>>>a[1:-6:-1]
>>> []
start_index=1在end_index=-6的左边,因此从左往右取值,但step=-则决定了从右往左取值,两者矛盾,因此为空。
>>>a[-1:6]
>>> []
start_index=-1在end_index=6的右边,因此从右往左取值,但step=1则决定了从左往右取值,两者矛盾,因此为空。
>>>a[-1:6:-1]
>>> [9, 8, 7]
start_index=-1在end_index=6的右边,因此从右往左取值,而step=-1同样决定了从右往左取值,因此结果正确。
6. 连续切片操作
>>>a[:8][2:5][-1:]
>>> [4]
相当于:
a[:8]=[0, 1, 2, 3, 4, 5, 6, 7]
a[:8][2:5]= [2, 3, 4]
a[:8][2:5][-1:] = 4
理论上可无限次连续切片操作,只要上一次返回的依然是非空可切片对象。
7. 切片操作的三个参数可以用表达式
>>>a[2+1:3*2:7%3]
>>> [3, 4, 5]
即:a[2+1:3*2:7%3] = a[3:6:1]
8. 其他对象的切片操作
前面的切片操作说明都以list为例进行说明,但实际上可进行的切片操作的数据类型还有很多,包括元组、字符串等等。
>>> (0, 1, 2, 3, 4, 5)[:3]
>>> (0, 1, 2)
元组的切片操作
>>>'ABCDEFG'[::2]
>>>'ACEG'
字符串的切片操作
>>>for i in range(1,100)[2::3][-10:]:
print(i)
就是利用range函数生成1-99的整数,然后取3的倍数,再取最后十个。
4.常用切片操作
以列表:a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 为说明对象
1.取偶数位置
>>>b = a[::2]
[0, 2, 4, 6, 8]
2.取奇数位置
>>>b = a[1::2]
[1, 3, 5, 7, 9]
3.拷贝整个对象
>>>b = a[:] #★★★★★
>>>print(b) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>>print(id(a)) #41946376
>>>print(id(b)) #41921864
或
>>>b = a.copy()
>>>print(b) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>>print(id(a)) #39783752
>>>print(id(b)) #39759176
需要注意的是:[:]和.copy()都属于“浅拷贝”,只拷贝最外层元素,内层嵌套元素则通过引用,而不是独立分配内存。
>>>a = [1,2,['A','B']]
>>>print('a={}'.format(a))
>>>b = a[:]
>>>b[0] = 9 #修改b的最外层元素,将1变成9
>>>b[2][0] = 'D' #修改b的内嵌层元素
>>>print('a={}'.format(a))
>>>print('b={}'.format(b))
>>>print('id(a)={}'.format(id(a)))
>>>print('id(b)={}'.format(id(b)))
a=[1, 2, ['A', 'B']] #原始a
a=[1, 2, ['D', 'B']] #b修改内部元素A为D后,a中的A也变成了D,说明共享内部嵌套元素,但外部元素1没变。
b=[9, 2, ['D', 'B']] #修改后的b
id(a)=38669128
id(b)=38669192
4.修改单个元素
>>>a[3] = ['A','B']
[0, 1, 2, ['A', 'B'], 4, 5, 6, 7, 8, 9]
5.在某个位置插入元素
>>>a[3:3] = ['A','B','C']
[0, 1, 2, 'A', 'B', 'C', 3, 4, 5, 6, 7, 8, 9]
>>>a[0:0] = ['A','B']
['A', 'B', 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
6.替换一部分元素
>>>a[3:6] = ['A','B']
[0, 1, 2, 'A', 'B', 6, 7, 8, 9]
总结
-
start_index、end_index、step可同为正、同为负,也可正负混合使用。但必须遵循一个原则,否则无法正确切取到数据:当start_index的位置在end_index的左边时,表示从左往右取值,此时step必须是正数(同样表示从左往右);当start_index的位置在end_index的右边时,表示从右往左取值,此时step必须是负数(同样表示从右往左),即两者的取值顺序必须是相同的。对于特殊情况,当start_index或end_index省略时,起始索引和终止索引由step的正负来决定,不会存在取值方向出现矛盾的情况(即不会返回空列表[]),但正和负取到的结果是完全不同的,因为一个向左一个向右。
-
在利用切片时,step的正负是必须要考虑的,尤其是当step省略时。比如a[-1:],很容易就误认为是从“终点”开始一直取到“起点”,即a[-1:]= [0, 1, 2, 3, 4, 5, 6, 7, 8, 9],但实际上a[-1:]=a[-1]=9,原因在于step=1表示从左往右取值,而起始索引start_index=-1本身就是对象的最右边的元素了,再往右已经没数据了,因此只有a[-1]一个元素。
相关代码
import numpy as np
a = arange(10)**3
a[2]
a[2:5]
a[:6:2] = -1000
a[ : :-1]
for i in a:
print i**(1/3.)
# 多维数组的索引
b = np.arange(20).reshape(5,4)
b[2,3]
b[0:5, 1]
b[ : ,1]
b[1:3, : ]
#当少于轴数的索引被提供时,确失的索引被认为是整个切片
b[-1] #相当于b[-1,:]
# b[i] 中括号中的表达式被当作 i 和一系列 : ,来代表剩下的轴。NumPy也允许你使用“点”像 b[i,...] 。
#点 (…)代表许多产生一个完整的索引元组必要的分号。如果x是
#秩为5的数组(即它有5个轴),那么:x[1,2,…] 等同于 x[1,2,:,:,:],x[…,3] 等同于 x[:,:,:,:,3],x[4,…,5,:] 等同 x[4,:,:,5,:].
三维数组的索引:
c = np.arange(12).reshape(2,3,2)
c[1]
c[2,1] # 等价于c[2][1]
c[2,1,1] # 等价于c[2][1][1]
# 通过数组索引
d = np.arange(10)**2
e = np.array ([3, 5, 6])
d[e] = ?
#练习, 用同样的方法在二维数组中操作。
# 通过布尔数组索引
f = np.arange(12).reshape(3, 4)
g = f>4
print(g)
f [g]
迭代多维数组是就第一个轴而言的:
h = np.arange(12).reshape(3,4)
for i in h:
print(i)
如果想对每个数组中元素进行运算,我们可以使用flat属性,该属性是数组元素的一个迭代器:
for i in h.flat:
print(i)
补充:flatten()的用法:
np.flatten()返回一个折叠成一维的数组。但是该函数只能适用于numpy对象,即array或者mat,普通的list列表是不行的。
具体代码
import numpy as np
# 切片
array = np.random.randint(1, 10, 16).reshape(4, 4)
print(array)
print("-------分割线---------")
# 取出第一行的所有值
print(array[0]) # 相当于 array[0,:]
print("-------分割线---------")
# 取第一列
print(array[:, 0])# 只有一个:代表步长默认为1
print("-------分割线---------")
# 取第一行和第三行
print(array[0::2, :]) #起始索引为0,步长为2 object[start_index:end_index:step]
print("-------分割线---------")
# 取第二列和第四列
print(array[::, 1::2])#起始索引为1,步长为2 为第二列和第四列
# 如果此处改为array[::,1:2] 就代表起始索引为1,结束索引为2, 步长为1
print("-------分割线---------")
# 取第一行和第三行的第二列和第四列
print(array[0::2, 1::2])
print("-------分割线---------")
# 遍历多维数组
for i in range(0, array.shape[0]):
for j in range(0, array.shape[1]):
print(array[i][j], end=" ")
print()
----------------------------------------------------------
[[9 5 4 3]
[2 9 5 6]
[6 1 6 6]
[9 6 9 3]]
-------分割线---------
[9 5 4 3]
-------分割线---------
[9 2 6 9]
-------分割线---------
[[9 5 4 3]
[6 1 6 6]]
-------分割线---------
[[5 3]
[9 6]
[1 6]
[6 3]]
-------分割线---------
[[5 3]
[1 6]]
-------分割线---------
9 5 4 3
2 9 5 6
6 1 6 6
9 6 9 3
----------------------------------------------------------
[[9 5 4 3]
[2 9 5 6]
[6 1 6 6]
[9 6 9 3]]
-------分割线---------
[9 5 4 3]
-------分割线---------
[9 2 6 9]
-------分割线---------
[[9 5 4 3]
[6 1 6 6]]
-------分割线---------
[[5 3]
[9 6]
[1 6]
[6 3]]
-------分割线---------
[[5 3]
[1 6]]
-------分割线---------
9 5 4 3
2 9 5 6
6 1 6 6
9 6 9 3
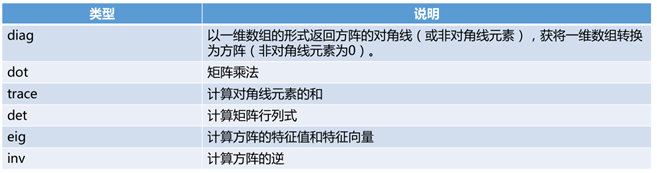
13.7 矩阵的操作
import numpy as np
# 切片
# array = np.random.randint(1, 10, 20).reshape(4, 5)
# # array2 = np.ones(20).reshape(4, 5)# 加减时 reshape中数字与array中一样
# array2 = np.ones(20).reshape(5, 4)# 矩阵乘法a*b时,要保证a的列数等于b的行数 a:m*p b:p*n
#
# print(array)
# 基本运算
# print(array.sum()) # 所有元素的和
# print(array.sum(0)) # 每一列的求和
# print(array.sum(1)) # 每一行的求和
# 矩阵加减
# print(array + array2)
# print(array - array2)
# 矩阵相乘
# array3 = np.dot(array, array2)
# print(array3)
# 矩阵转置
# print(array.T)
# 矩阵的逆
array = np.random.randint(1, 10, 9).reshape(3, 3) # n*n的矩阵一定会有逆矩阵
# print(array)
# array2 = np.linalg.inv(array)# 生成矩阵的逆
# print(array2)
# array3 = np.dot(array2, array)# 矩阵*逆矩阵=单位矩阵
# print(array3)# 单位矩阵:对角线元素为1
# 矩阵的乘除
print(array)
print(2*array)
print(array/2)
**********************************************
[[4 5 6]
[5 9 6]
[5 1 2]]
[[ 8 10 12]
[10 18 12]
[10 2 4]]
[[2. 2.5 3. ]
[2.5 4.5 3. ]
[2.5 0.5 1. ]]
13.8 形状操作
ravel(), vstack(),hstack(),column_stack,row_stack, stack, split, hsplit, vsplit
import numpy as np
array = np.random.randint(1, 10, 9).reshape(3, 3)
array2 = np.ones(9).reshape(3, 3)
print(array)
print("-------分割线---------")
print(array.ravel()) # 扁平化操作:将所有的值变成一个列表
# # 合并
print("-------分割线---------")
print(np.vstack((array, array2))) # 将两个数组纵向拼接 vertical
print("-------分割线---------")
print(np.hstack((array, array2))) # 将两个数组横向拼接
print("-------分割线---------")
print(np.row_stack((array2, array))) # 将两个数组纵向拼接
print("-------分割线---------")
print(np.column_stack((array2, array))) # 将两个数组横向拼接
print("-------分割线---------")
print(np.stack((array,array2),2))# stack(arrays, axis=0, out=None) arrays相同形状的数组序列 axis:返回数组中的轴,输入数组沿着它来堆叠 维度等于axis+1
print("-------分割线---------")
# 拆分
print(np.split(array, 1)) # split(ary,indices_or_sections,axis=0): 默认axis为0
print("-------分割线---------")
print(np.split(array, 3)) # split(ary,indices_or_sections,axis=0):
print("-------分割线---------")
print(np.split(array, 3, 1)) # 设置axis为1,所以为二维
print("-------分割线---------")
print(np.vsplit(array, 1)) # vsplit和split不指定axis时是一样
print("-------分割线---------")
print(np.vsplit(array, 3))
print("-------分割线---------")
print(np.hsplit(array, 3))
print("-------分割线---------")
o = np.array_split(np.arange(10), 3) # 不等量分割
print(o)
运行结果:
[[2 7 3]
[8 6 1]
[8 2 9]]
-------分割线---------
[2 7 3 8 6 1 8 2 9]
-------分割线---------
[[2. 7. 3.]
[8. 6. 1.]
[8. 2. 9.]
[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
-------分割线---------
[[2. 7. 3. 1. 1. 1.]
[8. 6. 1. 1. 1. 1.]
[8. 2. 9. 1. 1. 1.]]
-------分割线---------
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]
[2. 7. 3.]
[8. 6. 1.]
[8. 2. 9.]]
-------分割线---------
[[1. 1. 1. 2. 7. 3.]
[1. 1. 1. 8. 6. 1.]
[1. 1. 1. 8. 2. 9.]]
-------分割线---------
[[[2. 1.]
[7. 1.]
[3. 1.]]
[[8. 1.]
[6. 1.]
[1. 1.]]
[[8. 1.]
[2. 1.]
[9. 1.]]]
-------分割线---------
[array([[2, 7, 3],
[8, 6, 1],
[8, 2, 9]])]
-------分割线---------
[array([[2, 7, 3]]), array([[8, 6, 1]]), array([[8, 2, 9]])]
-------分割线---------
[array([[2],
[8],
[8]]), array([[7],
[6],
[2]]), array([[3],
[1],
[9]])]
-------分割线---------
[array([[2, 7, 3],
[8, 6, 1],
[8, 2, 9]])]
-------分割线---------
[array([[2, 7, 3]]), array([[8, 6, 1]]), array([[8, 2, 9]])]
-------分割线---------
[array([[2],
[8],
[8]]), array([[7],
[6],
[2]]), array([[3],
[1],
[9]])]
-------分割线---------
[array([0, 1, 2, 3]), array([4, 5, 6]), array([7, 8, 9])]
总结

总结

作业
-
列表和元组之间的区别是?
-
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
列表用[ ]标识,用len()函数可以获取list元素个数,可以用下标索引来获取指定位置的元素。
列表中的数据是可以进行修改的。
-
Python的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。
元组的元素不可修改,用()用作标识。
元素不可变指的是元素的指向不可变,当某个位置的元素指向一个list列表时,不可再指向其他列表,但是这个列表内的元素是可以被改变的。
-
-
解释一下Python中的继承
-
在程序中,继承描述的是事物之间的所属关系,例如猫和狗都属于动物,程序中便可以描述为猫和狗继承自动物
同理,波斯猫和巴厘猫都继承自猫,而沙皮狗和斑点狗都继承自狗
-
定义子类的时候在类名后加(父类类名)
-
Python中支持多继承 子类有多个父类,父类的属性和方法(非私有)子类都会继承
-
多继承中,如果多个父类中有同名的方法,那么通过子类调用此方法时,会调用哪一个?
会调用父类类名列表中的第一个父类的方法。
-
用子类类名.mro 可以查看子类对象查找类时的先后顺序
-
类的继承关系和生活中父亲、儿子、孙子之间的关系一样,Python中若A类继承B类,则A类称之为子类,B类称之为父类(也称为基类)。
-
-
Python中的字典是什么?
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。
字典中的key不可以重复,如果有重复,覆盖之前的值
value可以重复
value可以为空
set集合相当于没有值的dictdict是一个可变类型
- 字典和列表一样,也能够存储多个数据
- 列表中找某个元素时,是根据下标进行的
- 字典中找某个元素时,是根据’名字’(就是冒号:前面的那个值,例如上面代码中的’name’、‘id’、‘sex’)
- 字典的每个元素由2部分组成,键:值。例如 ‘name’:‘班长’ ,'name’为键,'班长’为值
若访问不存在的键,则会报错
在我们不确定字典中是否存在某个键而又想获取其值时,可以使用get方法,还可以设置默认值
-
请解释使用*args和**kwargs的含义
- 加了星号(*)的变量args会存放所有未命名的变量参数,args为元组;
- 加**的变量kwargs会存放命名参数,即形如key=value的参数, kwargs为字典。
- *args:表示一组值的集合,普通数据
- **kwargs:表示k-v格式的数据
-
请写一个Python逻辑,计算一个文件中的大写字母数量
f = open("words.txt", 'r', True) count = 0 # 存储大写字母的个数 while True: # 每次读取一个字符 ch = f.read(1) # 如果没有读到数据,跳出循环 if not ch: break # 判断是否为大写字母 if ch.isupper(): count += 1; print("大写字母个数为:%d" % count) f.close() -
什么是负索引?
对Python来说,负数索引表示从右边往左数,最右边的元素的索引为-1,倒数第二个元素为-2
-
Python区分大小写吗?
python区分大小写,如myName和MyName就是两个不同的变量名
-
怎么移除一个字符串中的前导空格?
可以使用lstrip里删除字符串的前导空格,如mystr.lstrip()
-
怎样将字符串转换为小写?
转换 mystr 中所有大写字符为小写:mystr.lower()
-
Python中的pass语句是什么?
Python pass 是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句。
在 Python 中有时候会看到一个 def 函数:
def sample(n_samples): pass该处的 pass 便是占据一个位置,因为如果定义一个空函数程序会报错,当你没有想好函数的内容是可以用 pass 填充,使程序可以正常运行。
-
解释一下Python中的//,%和 ** 运算符
运算符 描述 实例 // 取整除 返回商的整数部分 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 % 取余(取模) 返回除法的余数 b % a 输出结果 0 ** 幂 返回x的y次幂 a**b 为10的20次方, 输出结果 100000000000000000000 -
在Python中有多少种运算符?解释一下算数运算符。
python中主要有7种运算符,分别为 算术运算符,赋值运算符,关系运算符,逻辑运算符,位运算符,成员运算符,身份运算符等等
运算符 描述 实例 + 加 两个对象相加 a + b 输出结果 30 - 减 得到负数或是一个数减去另一个数 a - b 输出结果 -10 * 乘 两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 200 / 除 x除以y b / a 输出结果 2 // 取整除 返回商的整数部分 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 % 取余(取模) 返回除法的余数 b % a 输出结果 0 ** 幂 返回x的y次幂 a**b 为10的20次方, 输出结果 100000000000000000000 -
解释一下Python中的关系运算符
运算符 描述 示例 == 检查两个操作数的值是否相等,如果是则条件变为真。 如a=3,b=3则(a == b) 为 true. != 检查两个操作数的值是否相等,如果值不相等,则条件变为真。 如a=1,b=3则(a != b) 为 true. <> 检查两个操作数的值是否相等,如果值不相等,则条件变为真。 如a=1,b=3则(a <> b) 为 true。这个类似于 != 运算符 > 检查左操作数的值是否大于右操作数的值,如果是,则条件成立。 如a=7,b=3则(a > b) 为 true. < 检查左操作数的值是否小于右操作数的值,如果是,则条件成立。 如a=7,b=3则(a < b) 为 false. >= 检查左操作数的值是否大于或等于右操作数的值,如果是,则条件成立。 如a=3,b=3则(a >= b) 为 true. <= 检查左操作数的值是否小于或等于右操作数的值,如果是,则条件成立。 如a=3,b=3则(a <= b) 为 true. -
解释一下Python中的赋值运算符
运算符 描述 实例 = 赋值运算符 把=号右边的结果给左边的变量 num=1+2*3 结果num的值为7 运算符 描述 实例 += 加法赋值运算符 c += a 等效于 c = c + a -= 减法赋值运算符 c -= a 等效于 c = c - a *= 乘法赋值运算符 c *= a 等效于 c = c * a /= 除法赋值运算符 c /= a 等效于 c = c / a %= 取模赋值运算符 c %= a 等效于 c = c % a **= 幂赋值运算符 c = a 等效于 c = c a //= 取整除赋值运算符 c //= a 等效于 c = c // a -
解释一下Python中的逻辑运算符
运算符 逻辑表达式 描述 实例 and x and y 布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 (a and b) 返回 20。 or x or y 布尔"或" - 如果 x 是 True,它返回 True,否则它返回 y 的计算值。 (a or b) 返回 10。 not not x 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 not(a and b) 返回 False -
解释一下Python中的成员运算符
运算符 描述 实例 in 如果在指定的序列中找到值返回 True,否则返回 False。 x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 not in 如果在指定的序列中没有找到值返回 True,否则返回 False。 x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 -
讲讲Python中的位运算符
运算符 描述 实例 & 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 (a & b) 输出结果 12 ,二进制解释: 0000 1100 | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1。 (a | b) 输出结果 61 ,二进制解释: 0011 1101 ^ 按位异或运算符:当两对应的二进位相异时,结果为1 (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 ~ 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1 。~x 类似于 -x-1 (~a ) 输出结果 -61 ,二进制解释: 1100 0011,在一个有符号二进制数的补码形式。 << 左移动运算符:运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0。 a << 2 输出结果 240 ,二进制解释: 1111 0000 >> 右移动运算符:把">>"左边的运算数的各二进位全部右移若干位,>> 右边的数字指定了移动的位数 a >> 2 输出结果 15 ,二进制解释: 0000 1111 -
怎样获取字典中所有键的列表?
使用dict.keys()即可获取
如:
dict = {"a": 100, "b": 200, "c": 300} # 遍历字典的key(键) for i in dict.keys(): print(i,dict[i]) -
怎样声明多个变量并赋值?
a = b = c = 1 print(a) print(b) print(c) a, b = 45, 54 print(a) print(b) # 使用元组为多个变量赋值 data = ("zhangsan", "China", "Python") name, country, language = data print(name) print(country) print(language) # 为多个列表同时赋值 list1, list2 = ["hello", "world"], ["word", "count"] print(list1) print(list2) 运行结果: 1 1 1 45 54 zhangsan China Python ['hello', 'world'] ['word', 'count'] -
为何不建议以下划线作为标识符的开头
因为 Python 并没有私有变量的概念,所以约定速成以下划线__为开头来声明一个变量为私有。所以如果你不想让变量私有,就不要使用下划线开头。
-
一行代码实现1到100的求和
print(sum([i for i in range(1, 101)])) -
详细描述单例模式的实现
举个常见的单例模式例子,我们日常使用的电脑上都有一个回收站,在整个操作系统中,回收站只能有一个实例,整个系统都使用这个唯一的实例,而且回收站自行提供自己的实例。因此回收站是单例模式的应用。
确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个类称为单例类,单例模式是一种对象创建型模式。
# 实例化一个单例 class Singleton: __instance = None __First_init = True def __init__(self, name): # 保证创建单例时,只执行一次__init__方法 if self.__First_init: self.__First_init = False self.name = name print("init...") def __new__(cls,name): print("new...") # 保证只有一个对象 if not cls.__instance: cls.__instance = object.__new__(cls) return cls.__instance def run(self): print("running...") s = Singleton("zhangsan") s1 = Singleton("lisi")# 不能赋值 print(id(s)) print(id(s1)) print(s.name) print(s1.name) ------------------------------- new... init... new... 3193738032464 3193738032464 zhangsan zhangsan -
详细描述工厂模式的实现
工厂模式是我们最常用的实例化对象模式了,是用工厂方法代替new操作的一种模式。虽然这样做,可能多做一些工作,但会给你系统带来更大的可扩展性和尽量少的修改量(可维护性)。
1.简单工厂模式
Simple Factory模式不是独立的设计模式,他是Factory Method模式的一种简单的、特殊的实现。他也被称为静态工厂模式,通常创建者的创建方法被设计为static方便调用。
1、静态的工厂类
2、用全局函数改写工厂类
class Person(object): def __init__(self, name): self.name = name def work(self, type): print(self.name, "开始工作了") # person完成work,需要使用一把斧头 # axe = StoneAxe() # axe = SteelAxe() axe = Factory.getAxe(type) axe.cut_tree() class Axe(object): def __init__(self, name): self.name = name def cut_tree(self): print("使用", self.name, "砍树") class StoneAxe(Axe): def __init__(self): pass def cut_tree(self): print("使用石斧开始砍树") class SteelAxe(Axe): def __init__(self): pass def cut_tree(self): print("使用钢斧开始砍树") class DianJu(Axe): def __init__(self): pass def cut_tree(self): print("使用电锯开始砍树") # 工厂类 class Factory(object): @staticmethod def getAxe(type): if "stone" == type: return StoneAxe() elif "steel" == type: return SteelAxe() elif "dianju" == type: return DianJu() else: print("参数有问题") p = Person("zhangsan") p.work("stone") p = Person("lisi") p.work("steel") p = Person("wangwu") p.work("dianju") ------------------------------------ zhangsan 开始工作了 使用石斧开始砍树 lisi 开始工作了 使用钢斧开始砍树 wangwu 开始工作了 使用电锯开始砍树2.工厂方法模式
工厂方法模式去掉了简单工厂模式中工厂方法的静态方法,使得它可以被子类继承。对于python来说,就是工厂类被具体工厂继承。这样在简单工厂模式里集中在工厂方法上的压力可以由工厂方法模式里不同的工厂子类来分担。
抽象的工厂类提供了一个创建对象的方法,也叫作工厂方法。
-
抽象工厂角色(Factory): 这是工厂方法模式的核心,它与应用程序无关。是具体工厂角色必须实现的接口或者必须继承的父类。
-
具体工厂角色(Stone_Axe_Factory,Steel_Axe_Factory):它含有和具体业务逻辑有关的代码。由应用程序调用以创建对应的具体产品的对象。
-
抽象产品角色(Axe):它是具体产品继承的父类或者是实现的接口。在python中抽象产品一般为父类。
-
具体产品角色(Stone_Axe,Steel_Axe):具体工厂角色所创建的对象就是此角色的实例。由一个具体类实现。
class Person(object): def __init__(self, name): self.name = name def work(self, axe): print(self.name, "开始工作了") axe.cut_tree() # 抽象产品角色 class Axe(object): def __init__(self, name): self.name = name def cut_tree(self): print("使用", self.name, "砍树") # 具体产品角色 class StoneAxe(Axe): def __init__(self): pass def cut_tree(self): print("使用石斧开始砍树") # 具体产品角色 class SteelAxe(Axe): def __init__(self): pass def cut_tree(self): print("使用钢斧开始砍树") # 工厂类 class Factory: def create_Axe(self): pass # 具体工厂角色 class Stone_Axe_Factory(Factory): def create_Axe(self): return StoneAxe() # 具体工厂角色 class Steel_Axe_Factory(Factory): def create_Axe(self): return SteelAxe() p = Person("zhangsan") p.work(Stone_Axe_Factory().create_Axe()) p = Person("lisi") p.work(Steel_Axe_Factory().create_Axe()) ------------------------------------------- zhangsan 开始工作了 使用石斧开始砍树 lisi 开始工作了 使用钢斧开始砍树 -
-
python操作数据库的步骤
from pymysql import * conn = connect("localhost", "root", "123456", "demo", 3306) # 建立连接 cur = conn.cursor() # 游标 # 查询 # count = cur.execute("select * from emp") # 执行sql 返回影响的行数 # print(count) # result = cur.fetchall() # 抓取所有查询结果 # for i in result: # print(i) # result2 = cur.fetchone() # 抓取一条查询结果 # print(result2) # result2 = cur.fetchmany(5) # 抓取指定个数的查询结果 # print(result2) # 添加记录 # count = cur.execute("insert into emp(empno,ename) values(1111,'abcd')") count = cur.execute("insert into emp(empno,ename) values(%d,%s)"%(2222,"'aaaa'")) print(count) conn.commit()# 不写这一行则数据库不会修改 conn.close() -
NumPy中几个熟悉的函数的使用
基础函数
import numpy as np print(np.abs(-1)) # 绝对值 print(np.sqrt(9)) # 平方根 print(np.square(3)) # 平方np ** 2 print(np.exp(2)) # e^x print(np.log2(2)) # log2^2 底数为2的对数 print(np.log10(10)) # log10^10 底数为10的对数 print(np.log(np.e)) # loge^e 自然对数 print(np.sign(-165), ":", np.sign(321), ":", np.sign(0)) # 返回各元素的正负号 1正 0零 -1负 print(np.ceil(3.65)) # 大于等于该值的最小整数 print(np.ceil(-3.65)) print(np.floor(3.65)) # 小于等于该值的最小整数 print(np.floor(-3.65)) array = np.random.randint(1, 10, 9).reshape(3, 3) print(array.sum()) # 所有元素的和 零长度的数组的sum为0 print(array.sum(0)) # 每一列的求和 print(array.sum(1)) # 每一行的求和 list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] print(np.mean(list)) # 算术平均数 (1+2+3+...+10)/10 # list = [] # print(np.mean(list))# NaN 零长度的数组的mean为NaN print(np.max(list)) print(np.min(list)) print(np.argmax(list)) # 数组最大值的索引 print(np.argmin(list)) print(np.cumsum(list)) # 所有元素的累计和 print(np.cumprod(list)) # 所有元素的累计积 print("np.modf(100.12) : ", np.modf(100.12)) # 将数组中的小数部分和整数部分以两个独立数组的形式返回 print("np.modf(100.72) : ", np.modf(100.72)) print("np.modf(math.pi) : ", np.modf(np.pi)) list2 = [112, 113.65, 125, 365.56, 788.98] print("np.modf(list2) : ", np.modf( list2)) # np.modf(list2) : (array([0. , 0.65, 0. , 0.56, 0.98]), array([112., 113., 125., 365., 788.])) # subtract:从第一个数组中减去第二个数组中的元素 list3 = [3, 4, 5] list4 = [1, 1, 1] print(np.subtract(list3, list4)) # add:将数组中对应的元素相加 array1 = np.random.randint(1, 10, 9).reshape(3, 3) array2 = np.random.randint(1, 10, 9).reshape(3, 3) print(array1) print(array2) print(np.add(array1, array2)) # multiply:数组元素相乘(对应元素相乘) 区别于矩阵乘法 print(np.multiply(array1, array2)) # diag以一维数组的形式返回方阵的对角线元素 print(np.diag(array1)) print(np.diag(array2)) # dot矩阵乘法 print(np.dot(array1, array2)) # trace计算对角线元素的和 print(np.trace(array1)) print(np.trace(array2)) # det 计算矩阵行列式 print(np.linalg.det(array1)) print(np.linalg.det(array2)) # eig 计算方阵的特征值和特征向量 a2 = np.array([[1, 2, 3], [2, 3, 4]]) # 建立一个二维数组 b2 = np.array([[1, 2, 3], [2, 3, 4]], dtype=int) # 可以输出指定数据类型 # print(np.linalg.eig(a2)) # 返回矩阵a2的特征值与特征向量运行结果
1 3.0 9 7.38905609893065 1.0 1.0 1.0 -1 : 1 : 0 4.0 -3.0 3.0 -4.0 37 [12 12 13] [ 8 11 18] 5.5 10 1 9 0 [ 1 3 6 10 15 21 28 36 45 55] [ 1 2 6 24 120 720 5040 40320 362880 3628800] np.modf(100.12) : (0.12000000000000455, 100.0) np.modf(100.72) : (0.7199999999999989, 100.0) np.modf(math.pi) : (0.14159265358979312, 3.0) np.modf(list2) : (array([0. , 0.65, 0. , 0.56, 0.98]), array([112., 113., 125., 365., 788.])) [2 3 4] [[6 2 1] [3 5 5] [4 7 9]] [[6 3 6] [6 3 5] [7 1 3]] [[12 5 7] [ 9 8 10] [11 8 12]] [[36 6 6] [18 15 25] [28 7 27]] [6 5 9] [6 3 3] [[ 55 25 49] [ 83 29 58] [129 42 86]] 20 12 47.000000000000014 -15.0矩阵相关操作和切片
# 矩阵的逆 array = np.random.randint(1, 10, 9).reshape(3, 3) # n*n的矩阵一定会有逆矩阵 # print(array) # array2 = np.linalg.inv(array)# 生成矩阵的逆 # print(array2) # 矩阵的乘法 # array3 = np.dot(array2, array)# 矩阵*逆矩阵=单位矩阵 # print(array3)# 单位矩阵:对角线元素为1 # 矩阵转置 # print(array.T) # 基本运算 # print(array.sum()) # 所有元素的和 # print(array.sum(0)) # 每一列的求和 # print(array.sum(1)) # 每一行的求和 # 切片 # array = np.random.randint(1, 10, 20).reshape(4, 5) # # array2 = np.ones(20).reshape(4, 5)# 加减时 reshape中数字与array中一样 # array2 = np.ones(20).reshape(5, 4)# 矩阵乘法a*b时,要保证a的列数等于b的行数 a:m*p b:p*n # 切片 array = np.random.randint(1, 10, 16).reshape(4, 4) print(array) print("-------分割线---------") # 取出第一行的所有值 print(array[0]) # 相当于 array[0,:] print("-------分割线---------") # 取第一列 print(array[:, 0]) print("-------分割线---------") # 取第一行和第三行 print(array[0::2, :]) print("-------分割线---------") # 取第二列和第四列 print(array[::, 1::2]) print("-------分割线---------") # 取第一行和第三行的第二列和第四列 print(array[0::2, 1::2]) print("-------分割线---------") # 遍历多维数组 for i in range(0, array.shape[0]): for j in range(0, array.shape[1]): print(array[i][j], end=" ") print() array = np.random.randint(1, 10, 9).reshape(3, 3) print(array) print(np.where(array > 5, array, 0))# 将大于5的值留下来,小于5的用0代替 print(array[2][2])