8位(bit)=1字节(Byte),1024字节=1KB
【小技巧】在文档中,按住atl+数字,松开,会直接显示此数字对应的unicode码?
==================================
ASCII码:使用指定的【7 位或8 位】(1字节),二进制数组合(即0和1),来表示128 或256 种可能的字符
1.美国人发明(American Standard Code for Information Interchange)
===============================================================================
Unicode码:使用全【16位】(2字节), 表示可能的字符。
1.将所有语言统一到一个编码里(统一码、万国码、单一码)
2.因为是固定长度,对内存操作来说非常简单
===============================================================================
utf-8码:用【8到48位】(1到6个字节),表示可能的字符。
1.是一种针对Unicode的【可变长度】字符编码,又称万国码(8-bit Unicode Transformation Format)
2.用于存储,传输里节省资源。但在内存里问题会变复杂,长度不停变
3.遇英文变1字节、汉字变3字节(生字4-6字节)、有效节省空间
====================================================================================
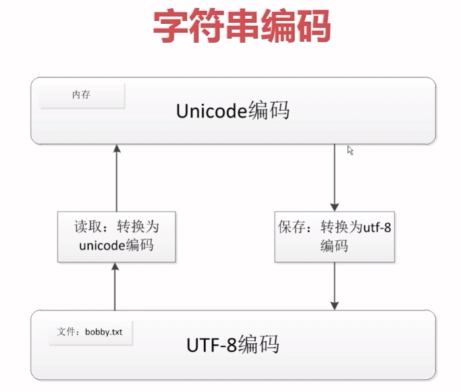
存储、传输,节省资源,但内存处理时变麻烦,解决办法:
1.存储时转换成utf-8,内存处理里转换成unicode。此过程一般会自动转化
可通过以下实现:
a.指明要保存文件的编码为utf8
b.encode(utf8)成utf8再保存
========================python中的编码问题=================================
1.python在内存中用unicode编码
2.decode()作用:将别的编码 变成 unicode
3.encode(utf8)作用:将unicode 变成 别的编码
4.python2中,windows下默认是gb2312;linux中默认是utf8 ?
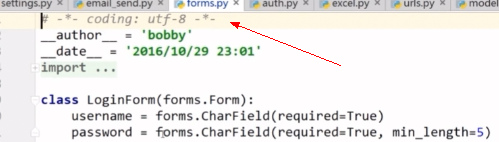
做项目时需要在头部先声明:
# -*-coding: utf-8 -*-
5.python3中,win下默认是utf-8,liunux默认是utf-8 ?
===================编码python实例===============================================
1.先用之前建立好的python虚拟环境创立一个python2的虚拟环境,详见:https://www.cnblogs.com/chenxi188/p/10700608.html
#建立虚拟环境 mkvirtualenv -p C:Pythonpython27python.exe py2 #显示拥有的环境 py2 workon #进入py2环境 workon py2
试验代码:第9行报错原因:python2在wins下默认是gbk2312,encode是用来把unicode转化成别的字符的,格式不匹配所以摄错
1 >>> s='abc' 2 >>> su=u'abc' 3 >>> s.encode('utf8') 4 'abc' 5 >>> su.encode('utf8') 6 'abc' 7 >>> s='你好' 8 >>> su=u'你好' 9 >>> s.encode('utf8') ####################### 10 Traceback (most recent call last): 11 File "<stdin>", line 1, in <module> 12 UnicodeDecodeError: 'ascii' codec can't decode byte 0xc4 in position 0: ordinal 13 not in range(128) 14 >>> su.encode('utf8') 15 'xe4xbdxa0xe5xa5xbd'
正确写法:
#含义:把s(编码为gbk2312)的字符串转化成unicode,再把unicode转化为utf8 s.decode('gbk2312').encode('utf8')
获取当前默认编码:
>>> import sys >>> sys.getdefaultencoding() 'ascii'
此时退出虚拟环境命令变为:
#此时退出虚拟环境命令变为: deactivate #进入虚拟环境命令变为: activate