xlrd模块的使用,直接上列子,如下:
有如下excel数据

我们需要对该表中的数据进行读取,首先要导入xlrd模块
1 import xlrd
打开文件操作,testExcel.xlsx为文件加路径
1 data = xlrd.open_workbook('testExcel.xlsx')
代码示例,一次性读取所有数据:
import xlrd def read_xlrd(excelTestFile): data = xlrd.open_workbook(excelTestFile) # 打开路径下的文件,并读取 table = data.sheet_by_index(0) # 根据sheet的索引,确定表格;也可以根据sheet名称确定,如:table = data.sheet_by_name('用户表') for rowNum in range(table.nrows): # excel表格中的有效行数,从0开始 rowVale = table.row_values(rowNum) # row_values返回该行中所有数据组成的一个列表 for colNum in range(table.ncols): # excel表格中的有效列数,从0开始 if rowNum > 0 and colNum == 0: print(int(rowVale[0])) else: print(rowVale[colNum]) print("#############################") if __name__ == '__main__': excelFile = 'testExcel.xlsx' read_xlrd(excelTestFile=excelFile)
效果如下所示:

其他的函数使用:
获取book中的一个工作表
table = data.sheets()[0] #通过索引顺序获取 table = data.sheet_by_index(sheet_indx)) #通过索引顺序获取 table = data.sheet_by_name(sheet_name)#通过名称获取 以上三个函数都会返回一个xlrd.sheet.Sheet()对象 names = data.sheet_names() #返回book中所有工作表的名字 data.sheet_loaded(sheet_name or indx) # 检查某个sheet是否导入完毕
行操作:
nrows = table.nrows #获取该sheet中的有效行数 table.row(rowx) #返回由该行中所有的单元格对象组成的列表 table.row_slice(rowx) #返回由该列中所有的单元格对象组成的列表 table.row_types(rowx, start_colx=0, end_colx=None) #返回由该行中所有单元格的数据类型组成的列表 table.row_values(rowx, start_colx=0, end_colx=None) #返回由该行中所有单元格的数据组成的列表 table.row_len(rowx) #返回该列的有效单元格长度
列操作:
ncols = table.ncols #获取列表的有效列数 table.col(colx, start_rowx=0, end_rowx=None) #返回由该列中所有的单元格对象组成的列表 table.col_slice(colx, start_rowx=0, end_rowx=None) #返回由该列中所有的单元格对象组成的列表 table.col_types(colx, start_rowx=0, end_rowx=None) #返回由该列中所有单元格的数据类型组成的列表 table.col_values(colx, start_rowx=0, end_rowx=None) #返回由该列中所有单元格的数据组成的列表
单元格操作:
table.cell(rowx,colx) #返回单元格对象,返回值的格式为“单元类型:单元值” table.cell_type(rowx,colx) #返回单元格中的数据类型,单元类型ctype:empty为0,string为1,number为2,date为3,boolean为4, error为5 table.cell_value(rowx,colx) #返回单元格中的数据,返回值为当前值的类型(如float、int、string...)
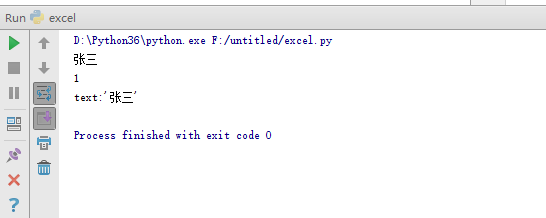
单元格操作举例说明:
def read_xlrd(excelTestFile): data = xlrd.open_workbook(excelTestFile) # 打开路径下的文件,并读取 table = data.sheet_by_index(0) # 根据sheet的索引,确定表格;也可以根据sheet名称确定,如:table = data.sheet_by_name('用户表')
print(table.cell_value(1,1)) #返回单元格中的数据,返回值为当前值的类型(如float、int、string...) print(table.cell_type(1,1)) #返回单元格中的数据类型,单元类型ctype:empty为0,string为1,number为2,date为3,boolean为4, error为5 print(table.cell(1,1)) #返回单元格对象,返回值的格式为“单元类型:单元值
if __name__ == '__main__': excelFile = 'testExcel.xlsx' read_xlrd(excelTestFile=excelFile)
运行结果: