数据规整:聚合、合并和重塑 《利用pandas进行数据分析-e2》
数据可能分散在许多文件或数据库中,存储的形式也不利于分析。
本章关注可以聚合、合并、重塑数据的方法。
- 首先,我会介绍pandas的层次化索引,它广泛用于以上操作。
- 然后,我深入介绍了 一些特殊的数据操作。merge , concat方法。
- 最后,实战应用:在第14章,你可以看到这些工具的多种应用。
8.1 层次化索引
层次化索引在数据重塑和基于分组的操作(如透视表生成)中扮演着重要的角色。
data = pd.Series(np.random.randn(9), index=[list("aaabbccdd"),[1,2,3,1,3,1,2,2,3]]) # a 1 -0.081004 2 0.849981 3 -0.140836 b 1 1.347778 3 -0.187549 c 1 1.072571 2 -1.201107 d 2 -0.605826 3 -0.542657 dtype: float64
#可以这么用,先用level0的索引进行切片提取数据,然后用level1的索引提取数据 data.loc[:, 2]
#a 0.849981 #c -1.201107 #d -0.605826 #dtype: float64
data.unstack() 和stack():
一对方法,分别是分解level1索引到columns,和把columns变成level1的index.
横轴和纵轴都可以有多重索引:
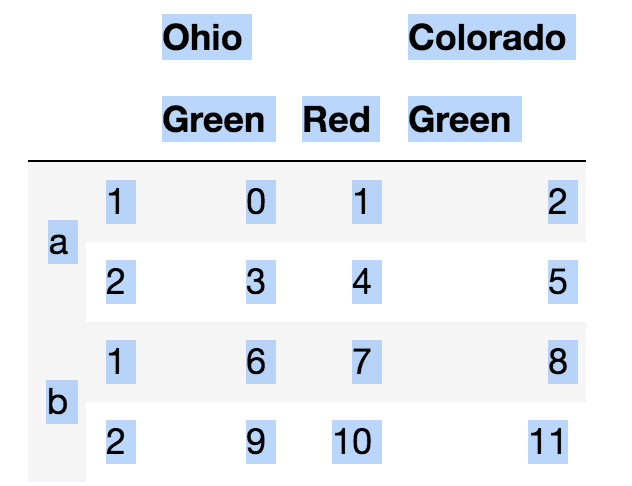
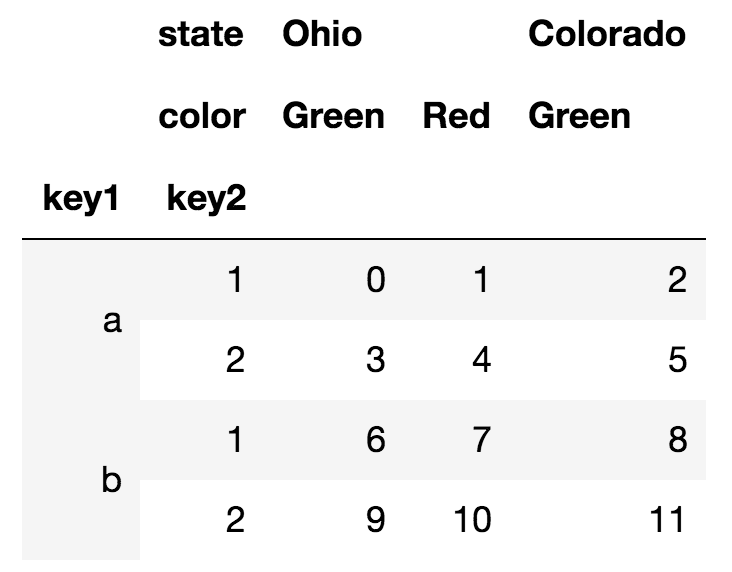
可以给行和列索引定义名字: frame.columns.names = ['state', 'color']
⚠️DataFrame结构数据 , 这种索引 frame["xxx"] , 方括号内的是列名。Series结构是一维的,所以frame["xxx"]的xxx本质也是列名。
pd.MultiIndex.from_arrays()
单独设置多重索引,以便反复使用。用法见:https://www.cnblogs.com/chentianwei/p/12267929.html
重排与分级排序:
- swaplevel(i, j) :重排列index, 把level的位置交换。
- sort_index(): 根据某个level进行排序
根据level进行汇总sum()统计:
frame.sum(level="key2") frame.sum(level="color", axis=1)
⚠️其实是使用了groupby,先分组,然后再统计。
使用DataFrame的列进行索引: set_index(keys),就是用自己的列数据当"行"索引。
例子
frame = pd.DataFrame({'a': range(7), 'b': range(7,0,-1), 'c':['one']*3+['two']*4, 'd':[0,1,2,0,1,2,3]})
frame.set_index(["c", 'd'])
 set_index()后
set_index()后  还可以反向操作:reset_index()
还可以反向操作:reset_index()
8.2 合并数据集
数据库风格的DataFrame合并
数据集的合并(merge)或连接(join)运算是通过一个或多个键将行连接起来的。 这些运算是关系型数据库(基于SQL)的核心。
pd.merge(left, right, how="inner", left_on=None, right_on=None, left_index=False, right_index=False)
之前的博客的例子:https://www.cnblogs.com/chentianwei/p/12302654.html

索引上的合并merge , join
有时候,DataFrame中的连接键位于其索引中。
在这种情况下,可以传入 left_index=True或right_index=True(或两个都传)以说明索引应该被用作连接键:
left1 = pd.DataFrame({'key': ['a', 'b', 'a', 'a', 'b','c'],'value': range(6)}) right1 = pd.DataFrame({'group_val': [3.5, 7]}, index=['a', 'b']) pd.merge(left1, right1, left_on='key', right_index=True) key value group_val 0 a 0 3.5 2 a 2 3.5 3 a 3 3.5 1 b 1 7.0 4 b 4 7.0
join方法也很方便,但功能上和merge 类似。具体见上面的链接。
轴向连接:
⚠️和pd.merge/join的区别就是设置了,轴方向: axis=0
另一种数据合并运算也被称作连接(concatenation)、绑定(binding)或堆叠 (stacking)。
np.concatenate((a1, a1, ...), axis=0)
pandas.concat(objs, axis=0, join="outer")
- join参数:默认outer,还有inner
- join_axes=None参数: 可以设置索引的排列顺序,这个参数已经被抛弃,可以使用.reindex()方法代替。
- keys=None参数:sequence格式,用于创建层次化索引MultiIndex levels。
- names=None参数: 为轴level设置名字。
- ignore_index= False参数:见下面的例子。
- 如果True,沿着连接轴方向使用index值,被标签为0,..., n-1。
- 用途:如果连接的对象的连接轴没有实际有用的索引信息,那么可以使用这个参数。
对于pandas对象(如Series和DataFrame),带有标签的轴使你能够进一步推广数 组的连接运算。
例子,Series数据类型使用keys参数:
s1 = pd.Series([0, 1], index=['a', 'b']) s2 = pd.Series([2,3,4], index=list('cde')) s3 = pd.Series([5,6], index=list('fg')) result = pd.concat([s1,s2,s3], keys=["one", 'two', 'three']) #### one a 0 b 1 two c 2 d 3 e 4 three f 5 g 6 dtype: int64 ####
#Series数据,使用axis=1和keys参数,keys指定的label会变为colums names pd.concat([s1, s2, s3], axis=1, keys=['one','two', 'three']) one two three a 0.0 NaN NaN b 1.0 NaN NaN c NaN 2.0 NaN d NaN 3.0 NaN e NaN 4.0 NaN f NaN NaN 5.0 g NaN NaN 6.0
例子, DataFrame数据类型使用keys参数和axis=1参数:
df1 = pd.DataFrame(np.arange(6).reshape(3,2), index=list('abc'), columns=['one', 'two']) df2 = pd.DataFrame(5 + np.arange(4).reshape(2, 2), index=['a', 'c'], columns=['three', 'four']) pd.concat([df1,df2],axis=1)
one two three four a 0 1 5.0 6.0 b 2 3 NaN NaN c 4 5 7.0 8.0
#使用keys后,DataFrame多了一层列标签.
pd.concat([df1,df2],axis=1,keys=["level1", 'level2'])
level1 level2 one two three four a 0 1 5.0 6.0 b 2 3 NaN NaN c 4 5 7.0 8.0
如果传入的是一个dict, 则dict的key键就是keys参数的值:
pd.concat({'level1': df1, 'level2': df2}, axis=1)
#和上面结果一样
例子, ignore_index参数的用法:自动生成连续整数作为行标签。因为原行标签没有意义,被忽略掉。
#还是上面例子的数据: pd.concat([df1,df2], ignore_index=True)
a b c d
0 -0.000430 0.107241 -0.722731 -0.861373
1 -0.973658 1.188648 -0.297247 -0.973776
2 1.274261 -0.450837 1.025689 -0.814874
3 -0.397184 -0.518178 NaN -1.217702
4 -0.376736 -1.705099 NaN -0.514329
合并重叠数据
还有一种数据组合问题不能用简单的合并(merge)或连接(concatenation)运算来处理。
比如说,你可能有索引全部或部分重叠的两个数据集。
举个有启发性的例 子,我们使用NumPy的where函数,它表示一种等价于面向数组的if-else:
np.where(condition, [x, y])
Series有一个combine_first方法,实现的也是一样的功能,还带有pandas的数据对齐 .
对于DataFrame,combine_first自然也会在列上做同样的事情,因此你可以将其看 做:用传递对象中的数据为调用对象的缺失数据“打补丁”
8.3 重塑和轴向旋转
重塑层次化索引
- stack(level=-1, dropna=True)把列索引转变为行索引,
- ⚠️参数level=-1,所以默认转换最内层的level。
- dropna=True参数,会默认去掉缺失值Na。因为unstack()有时会产生缺失值。
- unstack()则相反
将“长格式”旋转为“宽格式”(279)
多个时间序列数据通常是以所谓的“长格式”(long)或“堆叠格式”(stacked)存储 在数据库和CSV中的