一、预计用时
根据要求,完成词频统计的工作需要以下几个步骤:
1.用递归的方法遍历指定路径下所有的文件夹,找出所有指定类型文件的绝对路径;
2.分别打开上述路径所对应的文件,根据word definition划分单词,统计各单词的词频(大小写不敏感,按照字典序排序);
3.对各单词的词频进行排序,并将结果输出到文本文件中。
对我而言,主要时间会花在文件的递归查找以及单词的详细划分过程上,因此预计时间如下:
(1)算法设计:1小时
对文件遍历、单词划分、词频统计、排序输出等步骤所需要用到的函数以及算法实现做一个初步的计划;
(2)代码编写:3小时
在不考虑结果正确性的前提下,先保证代码能够运行;
(3)代码调试:3小时
通过测试多个文件,寻找代码中的错误点,并进行改正。
二、实际用时
(1)算法设计:2小时
a.在文件遍历的步骤中,不知道怎么在c++中执行cmd命令,在肖俊鹏同学的指导下,通过system()函数完成了这一步,将所有指定类型的文件的路径都输出到result.txt文件中;
b.用结构体来存储单词和单词对应的词频,在这个地方,对于单词的划分不够详细,影响了下面代码编写阶段的用时;
c.用冒泡排序法对词频进行排序,借助c++中的ofstream将结果输出到文本文件中。
(2)代码编写:6小时
a.由于对main(int argc,char* argv[])了解的不透彻,在用system函数执行cmd命令的时候出现了很多错误,不知道怎么讲cmd窗口输入的文件路径添加到程序执行指令中去;
dir [dictionary] /S /B > FileDir.tmp
b.词频统计阶段,主要时间花在了单词的判断,单词的比较以及处理大小写不敏感并且按照字典序输出的问题上,而且,由于开始没有考虑到simple mode和extended mode的不同,等到编写时发现两者之间在代码的编写上有着较大的差异,准备不足,浪费了较多时间;
c.排序输出:这个阶段比较简单,和预期一样,没有花过多时间。
(3)代码调试:4小时
当代码等够成功运行的时候,感觉自己成功了一半,哪知道在调试阶段发现错误百出,能运行程序却得不到正确的结果,只好自己添加测试文件,从最简单的规则开始调试。在调试过程中,遇到最多的问题就是单词的划分了,出现了诸如首字母相同的单词错误输出、大小写单词未能统计在一起等错误,开始时c++环境下通过cmd命令完成文件的输入输出也是一大障碍,但是在别人的帮助下,这一部分倒是较快的解决了。
三、代码分析
利用VS2012中的analyze功能,对调试好的代码进行了效率分析。下面是分析截图:
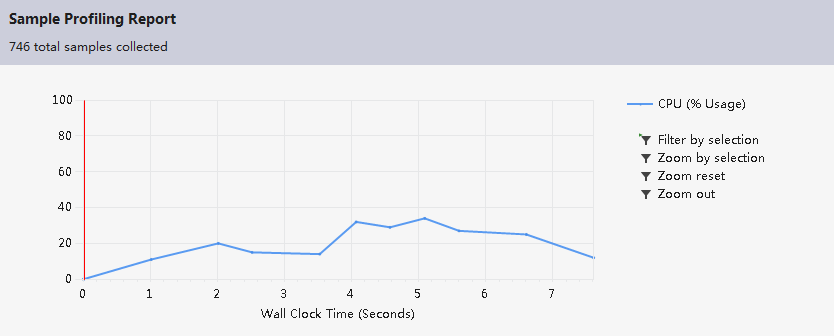

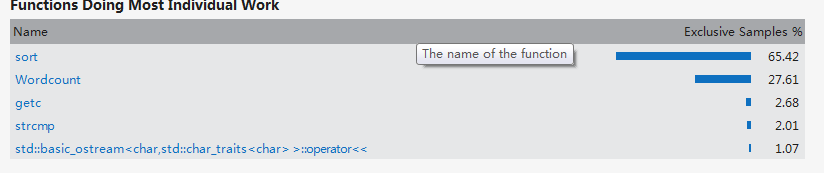
可以看出,在数据量较大时,对词频的排序占用了较大的时间,本来考虑采用快速排序法,但是由于用的是结构体保存的单词和词频,快速排序在交换词频的同时无法交换该词频对应的单词,因此还是选用了冒泡排序法。
四、测试样例
1.测试大小写敏感
测试样例及输出结果截图
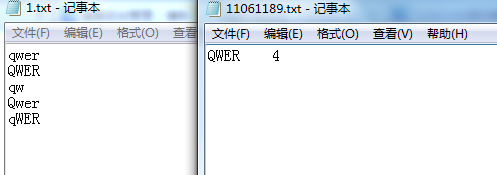
输出结果显示,代码大小写不敏感成功,并且单词能按照字典序输出。
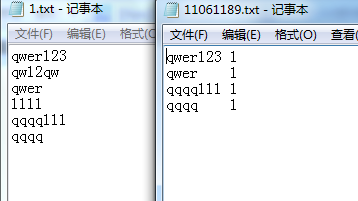
2.测试字母与数字混杂的情况
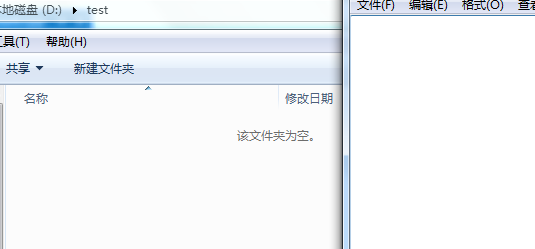
3.测试路径下为空文件
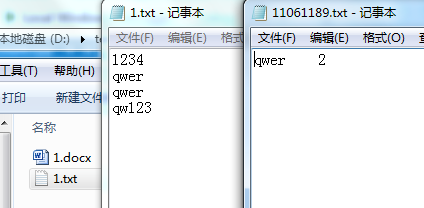
4.测试路径下有其他类型的文件
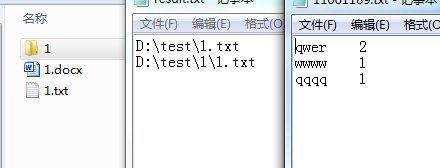
5.测试路径下包含子目录
6.首字符是数字的情况

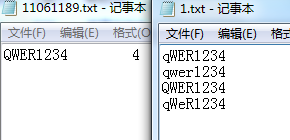
7.extended mode测试
8.综合测试:Pride and Prejudice.txt

9.其他包括字典序测试、字母数未达到4的测试等都已经在上述测试中体现,不再赘述。
五、收获
1.编写程序之前先有一个清晰的算法流程,这会给代码编写带来很大的方便;
2.代码的调试比代码的编写更复杂、更重要,也是程序正确性的保证;
3.积极地与他人交流可以收获很多。