目录
- 一、CPU
- 1.1 top命令--CPU性能
- 1.2 负载 —— CPU 任务排队情况
- 1.3 vmstat —— CPU 繁忙程度
- 二、内存
- 2.1 top命令
- 三、IO
- 3.1 iostat
- 3.2 零拷贝
一、CPU
首先介绍计算机中最重要的计算组件中央处理器 CPU,围绕 CPU 一般我们可以:
-
通过 top 命令,来观测 CPU 的性能;
-
通过负载,评估 CPU 任务执行的排队情况;
-
通过 vmstat,看 CPU 的繁忙程度。
1.1 top命令--CPU性能
如下图,当进入 top 命令后,按 1 键即可看到每核 CPU 的运行指标和详细性能。
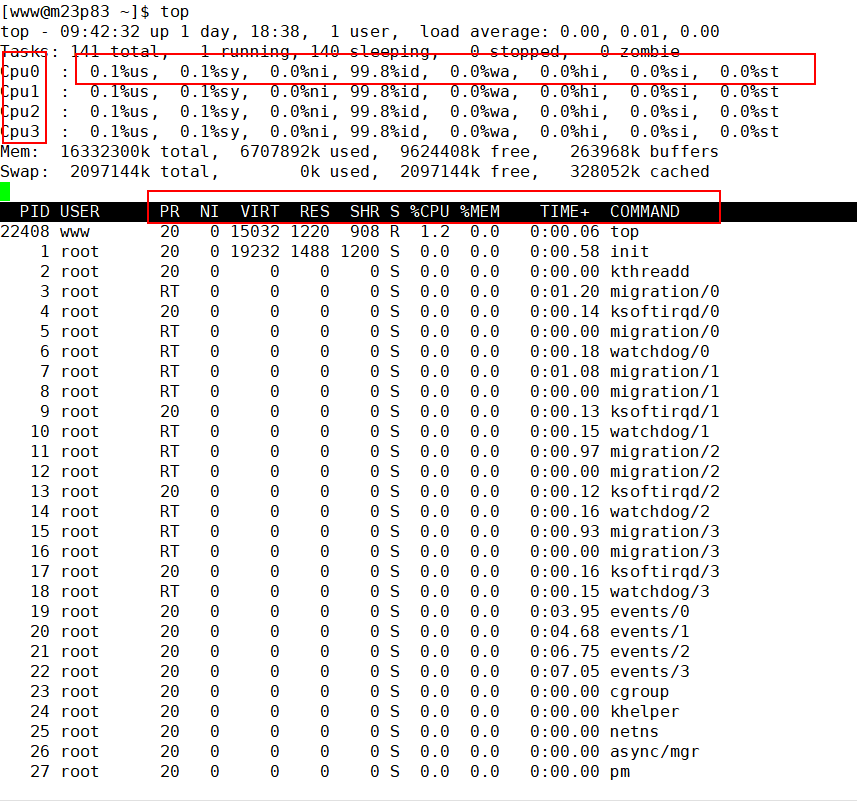
CPU 的使用有多个维度的指标,下面分别说明:
us 用户态所占用的 CPU 百分比,即引用程序所耗费的 CPU;
sy 内核态所占用的 CPU 百分比,需要配合 vmstat 命令,查看上下文切换是否频繁;
ni 高优先级应用所占用的 CPU 百分比;
wa 等待 I/O 设备所占用的 CPU 百分比,经常使用它来判断 I/O 问题,过高输入输出设备可能存在非常明显的瓶颈;
hi 硬中断所占用的 CPU 百分比;
si 软中断所占用的 CPU 百分比;
st 在平常的服务器上这个值很少发生变动,因为它测量的是宿主机对虚拟机的影响,即虚拟机等待宿主机 CPU 的时间占比,这在一些超卖的云服务器上,经常发生;
id 空闲 CPU 百分比。
一般地,我们比较关注空闲 CPU 的百分比,它可以从整体上体现 CPU 的利用情况。
那 load 为 1 代表的是啥?针对这个问题,误解还是比较多的。
1.2 负载 —— CPU 任务排队情况
如果我们评估 CPU 任务执行的排队情况,那么需要通过负载(load)来完成。除了 top 命令,使用 uptime 命令也能够查看负载情况,load 的效果是一样的,分别显示了最近 1min、5min、15min 的数值。

很多人看到 load 的值达到 1,就认为系统负载已经到了极限。这在单核的硬件上没有问题,但在多核硬件上,这种描述就不完全正确,它还与 CPU 的个数有关。例如: 单核的负载达到 1,总 load 的值约为 1; 双核的每核负载都达到 1,总 load 约为 2; 四核的每核负载都达到 1,总 load 约为 4。 所以,对于一个 load 到了 10,却是 16 核的机器,你的系统还远没有达到负载极限。
1.3 vmstat —— CPU 繁忙程度
要看 CPU 的繁忙程度,可以通过 vmstat 命令,下图是 vmstat 命令的一些输出信息。

比较关注的有下面几列: b 如果系统有负载问题,就可以看一下 b 列(Uninterruptible Sleep),它的意思是等待 I/O,可能是读盘或者写盘动作比较多; si/so 显示了交换分区的一些使用情况,交换分区对性能的影响比较大,需要格外关注; cs 每秒钟上下文切换(Context Switch)的数量,如果上下文切换过于频繁,就需要考虑是否是进程或者线程数开的过多。 每个进程上下文切换的具体数量,可以通过查看内存映射文件获取,如下代码所示(voluntary_ctxt_switchesh和nonvoluntary_ctxt_switches):
二、内存
逻辑地址可以映射到两个内存段上:物理内存和虚拟内存,那么整个系统可用的内存就是两者之和。比如你的物理内存是 4GB,分配了 8GB 的 SWAP 分区,那么应用可用的总内存就是 12GB。
2.1 top命令
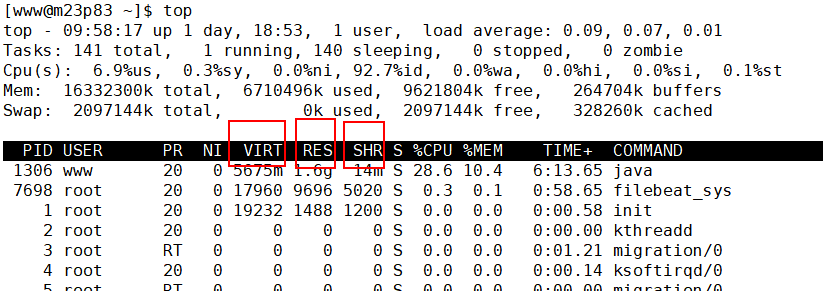
top命令打开后,按f键如下所示,按Enter退出:
Current Fields
默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。
-
通过 f 键可以选择显示的内容。按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。
-
按 o 键可以改变列的显示顺序。按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。
-
按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转。
top 运行中可以通过 top 的内部命令对进程的显示方式进行控制。内部命令如下: s – 改变画面更新频率 l – 关闭或开启第一部分第一行 top 信息的表示 t – 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示 m – 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示 N – 以 PID 的大小的顺序排列表示进程列表 P – 以 CPU 占用率大小的顺序排列进程列表 M – 以内存占用率大小的顺序排列进程列表 h – 显示帮助 n – 设置在进程列表所显示进程的数量 q – 退出 top s – 改变画面更新周期
三、IO
I/O 设备可能是计算机里速度最慢的组件了,它指的不仅仅是硬盘,还包括外围的所有设备。那硬盘有多慢呢?我们不去探究不同设备的实现细节,直接看它的写入速度(数据未经过严格测试,来自网络,仅作参考,在此只为了说明问题)。

如上图所示,可以看到普通磁盘的随机写与顺序写相差非常大,但顺序写与 CPU 内存依旧不在一个数量级上。
缓冲区依然是解决速度差异的唯一工具,但在极端情况下,比如断电时,就产生了太多的不确定性,这时这些缓冲区,都容易丢。
3.1 iostat
最能体现 I/O 繁忙程度的,就是 top 命令和 vmstat 命令中的 wa%。如果你的应用写了大量的日志,I/O wait 就可能非常高。

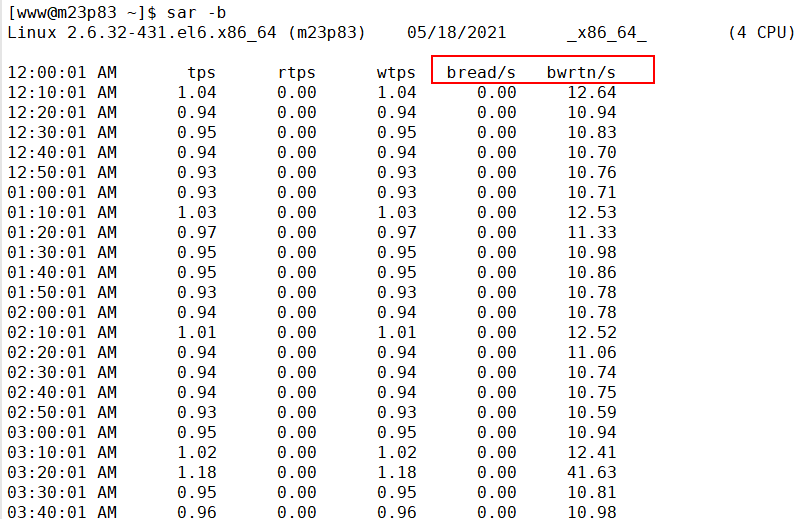
查看磁盘 I/O 的工具(iostat), 如下所示:
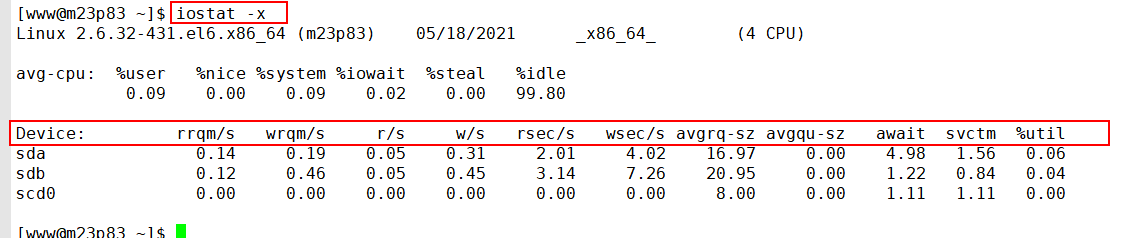
图中的指标详细介绍如下所示。 %util:我们非常关注这个数值,通常情况下,这个数字超过 80%,就证明 I/O 的负荷已经非常严重了。 Device:表示是哪块硬盘,如果你有多块磁盘,则会显示多行。 avgqu-sz:平均请求队列的长度,这和十字路口排队的汽车也非常类似。显然,这个值越小越好。 awai:响应时间包含了队列时间和服务时间,它有一个经验值。通常情况下应该是小于 5ms 的,如果这个值超过了 10ms,则证明等待的时间过长了。 svctm:表示操作 I/O 的平均服务时间,这里就是 AVG 的意思。svctm 和 await 是强相关的,如果它们比较接近,则表示 I/O 几乎没有等待,设备的性能很好;但如果 await 比 svctm 的值高出很多,则证明 I/O 的队列等待时间太长,进而系统上运行的应用程序将变慢。
3.2 零拷贝
硬盘上的数据,在发往网络之前,需要经过多次缓冲区的拷贝,以及用户空间和内核空间的多次切换。如果能减少一些拷贝的过程,效率就能提升,所以零拷贝应运而生。 零拷贝是一种非常重要的性能优化手段,比如常见的 Kafka、Nginx 等,就使用了这种技术。我们来看一下有无零拷贝之间的区别。 (1)没有采取零拷贝手段 如下图所示,传统方式中要想将一个文件的内容通过 Socket 发送出去,则需要经过以下步骤: 将文件内容拷贝到内核空间; 将内核空间内存的内容,拷贝到用户空间内存,比如 Java 应用读取 zip 文件; 用户空间将内容写入到内核空间的缓存中; Socket 读取内核缓存中的内容,发送出去。

(2)采取了零拷贝手段 零拷贝有多种模式,我们用 sendfile 来举例。如下图所示,在内核的支持下,零拷贝少了一个步骤,那就 是内核缓存向用户空间的拷贝,这样既节省了内存,也节省了 CPU 的调度时间,让效率更高。
