关注公众号:Python爬虫数据分析挖掘,回复【开源源码】免费获取更多开源项目源码
变量选择
通过网络数据获取,得到游戏数据指标如下所示: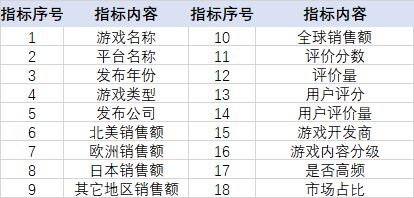
游戏数据分析的整体思路
第一步;数据文件获取(1.导入数据 2.查询结构 3.更改结构 4.汇总变量信息);
第二步;数据预处理(1.剔除缺失值2.变量转换与衍生 3.读出处理好的数据观察和可视化4.汇总变量类型);
第三步;数据挖掘(1.逻辑回归 2. 决策树 3.随机森林 4.三种模型比较验证);
第四步;展示与解读(1.描述统计分析 2.描述及模型解读)
提出问题
(1)问题:游戏app是否高频使用用户的影响因素是什么?
(2)游戏产品的高频使用用户的定义:是否游戏高频用户的定义:对游戏使用量进行中位数划分,如果大于中位数是高频用户,低于中位数是低频用户
上述数据源可用于分析的问题面有:
(0): 高频游戏用户和低频游戏用户的影响因素是什么
(1)高频用户集中的游戏平台有哪些
(2)高频用户集中的游戏类型是什么,可针对市场高频用户的喜好开发热款游戏
(3)高频用户集中的销售额主要占比市场,可考虑游戏产品的设计主要面向哪个市场
解决商务问题和业务决策的应用点有:
(1)游戏投资商可对高频用户的游戏类型进行投资
(2)游戏产品的市场面对群体的普及主要针对哪个市场
(3)游戏产品的市场面对哪类游戏受喜好的人多
分析目标:高频游戏用户的影响因素是什么?
数据选择:2010~2016年的游戏数据
变量指标选择:游戏名称、平台名称、发布年份、游戏类型、发布公司、北美销售额、欧洲销售额、日本销售额、其它地区销售额、全球销售额、评价分数、游戏评价量、用户评分、游戏使用人数、游戏开发商。
变量相关性:选择分析变量相关性主要研究以下9个变量间的相关性情况:
北美销售额
欧洲销售额
日本销售额
其它地区销售额
全球销售额
评价分数
评价量
用户评分
用户使用量
主要市场
通过分析得到,用户使用量和游戏评论量、评论分数,全球销售额存在相关。和其它地区的销售额无关,和用户的评分相关性较低。
得到相关系数图如下,其中除对角线以外,颜色越靠近深蓝色,表示相关性越强。其中用户使用量和用户得分与日本销售额相关性较低。其余都存在一定程度的相关性。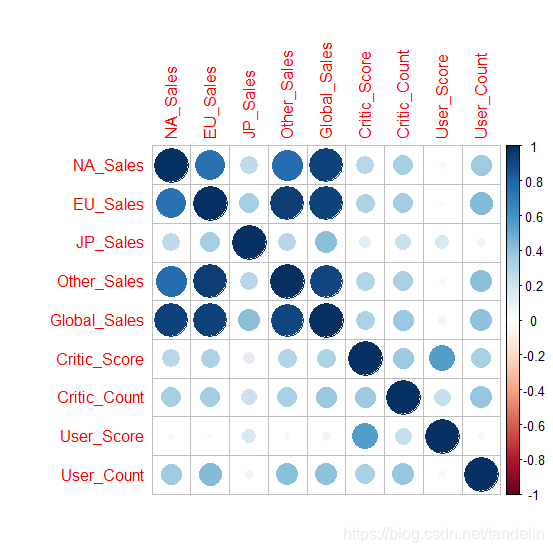
用户相关性计算,选择的是皮尔逊相关系数,主要选择的是数值型数据进行相关性分析。
str(data) xgdata=sqldf("select NA_Sales,EU_Sales,JP_Sales,Other_Sales,Global_Sales,Critic_Score,Critic_Count,User_Score ,User_Count from data") str(xgdata) mf_cor=cor(xgdata)###求得相关系数 cor.plot <- corrplot(corr = mf_cor)
通过相关系数行最后一行的图形可以看出,用户是否高频使用情况和评论量有关,其次是评论用户数有一定的影响。
数据处理
1. 在Tableau和R中分析,哪些属性值可以不分析(删除)
无关变量: 游戏名称 /用户得分,这两个变量属性属于无关变量,可进行删除。
2. 哪些属性值需要派生
研究对象为:
(1)是否高频用户, 其中高频用户属于衍生变量,其定义为:对游戏用户使用量进行中位数划分,如果大于中位数是高频用户,低于中位数是低频用户。
(2)游戏主要市场: 对北美、欧洲、日本,其它销售额进行比较判断,取最大的销售额作为主要市场,并以最大销售额的市场作为主要市场。
3. 哪些属性值需要补充缺失值
其中缺失值不需要进行补充,由于数据的业务背景了解不够,仅只对数据中的缺失值进行删除。
4. 并将数据集分为“训练”“测试”“验证(如果必要的话)”三个子集。
数据训练集和测试集划分标准以0.8和0.2进行随机抽样,保证数据的无序抽取。划分代码如下:
其中处理数据的方法有随机森林,决策树、逻辑斯蒂回归,
模型精确度用AUC进行衡量,得到混淆矩阵,得出召回率,对比进行分析发现决策树模型效果较好。
使用测试集数据对综合预测模型,评估精确度、召回率。
模型的优化方法主要可在以下几个方面进行:
1. 获取更多的游戏指标数据
2. 对游戏数据的训练集样本增加,保证模型的训练精度
glm.full=glm(High_frequency_usage~.,family=binomial(link="logit"),data_train) glm.null=glm(High_frequency_usage~1,family=binomial(link="logit"),data_train) summary(glm.full) glm.aic=step(glm.full,trace=F,test="LRT") summary(glm.aic) glm.bic=step(glm.full,k=log(n),trace=F,test="LRT") glm.bic <-step(glm.full,k=log(n),trace=F,test="LRT") n=dim(a)[1] summary(glm.bic) library(pROC) #画ROC曲线和计算AUC所用到的pROC包 pred.aic <- glm.aic$fitted.values #AIC模型预测值(出险概率) roc.aic <- roc(a$LossClass,pred.aic) #AIC模型ROC曲线取值 plot(roc.aic,print.auc=T,print.auc.x=0.9,print.auc.y=0.8,print.thres=T,print.auc.cex=2.5,print.thres.cex=1.5,col="pink",main="AIC模型的ROC曲线")# 选择AIC模型,在ROC曲线上标注AUC值和最佳阈值 ##混淆矩阵 thres <- 0.318 #最佳阈值 table(a$LossClass,1*(pred.aic>thres)) #混淆矩阵