1).MapReduce的概述
2).MapReduce 编程模型
3).MapReduce架构
4).MapReduce编程
Google MapReduce论文,论文发表于2004年
Hadoop MapReduce是Google MapReduce的克隆版
MapReduce优点:海量数据离线处理&易开发&易运行
Mapreduce缺点:式时流程计算
接下来是讲的是单节点
MapReduce编程模型
WordCount:统计文件中每个单词出现的次数
需求:求wc
1)文件内容小:shell
2)文件内容大:TB GB ??? 如何解决大数据量的分析
==>URL(TOP N)==>wc的衍生
工作中的很多场景都是经过wordcount改造的
关键搜索词的提醒适用于大数据量
借助于分布式计算框架来解决了
MapReduce编程模型通过wordcount词频统计案例
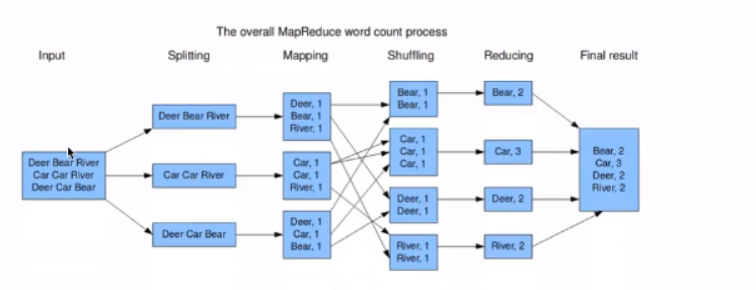
数据输入-拆分-按照指定的是分隔符进行拆分并且给每个单词出现的1的次数-Shuffing对多个计算进行合并-Reduce对每个出现的次数进行合并-最后输出出来
分而制之 Map的输出作为Reduce的输入
MapReuce 是存储在HDFS上面的
MapReduce编程模型的Map和Reduce阶段
一个MapReduce会将作业拆分成Map和Reduce阶段
Map阶段:Map Tasks
Reduce阶段:Reduce Tasks
MapReduce执行步骤
1)准备map处理的输入数据
2)Mapper处理
3)Shuffle
4)Reduce处理
5)结果输出
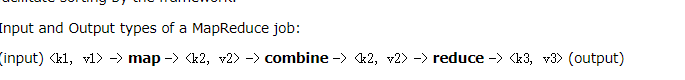
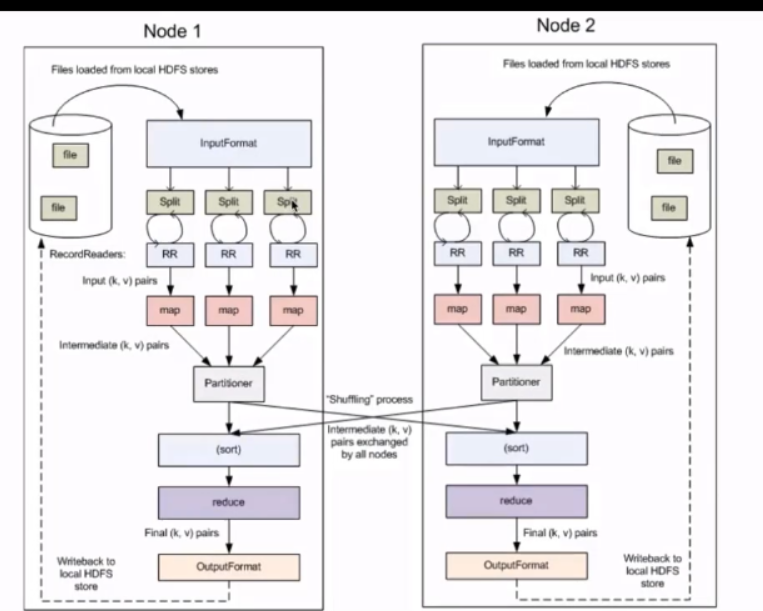
MapReduce核心概念
1)Split:交由MapReduce作业来处理的数据块
HDFS:blocksize 是HDFS中最小的存储单元 128m
split 是mapredece最小的计算单元
这两个是一一对应的
InputFormat:将我们的输入数据进行分片(split): InputSplit[] getSplits(jobConf job,in TextInputFormat):处理文本格式的数据
OutputFormat:输出
Combiner
Partitioner
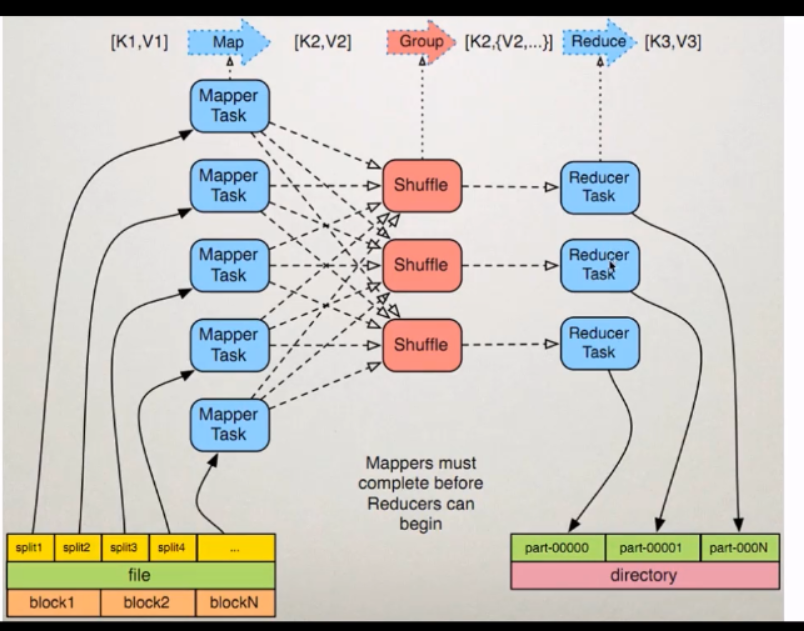
MapReduce1.x的架构图
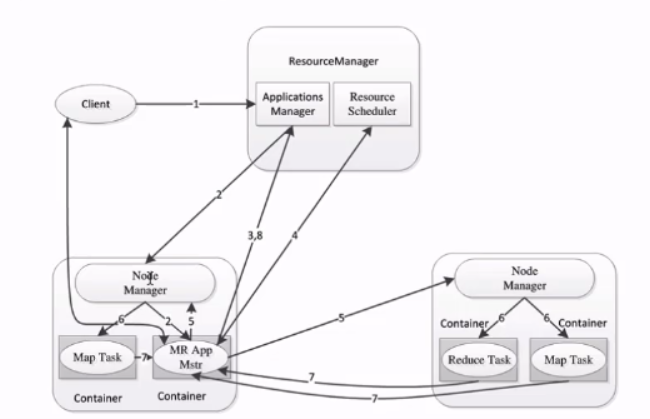
MapReduce2.x架构

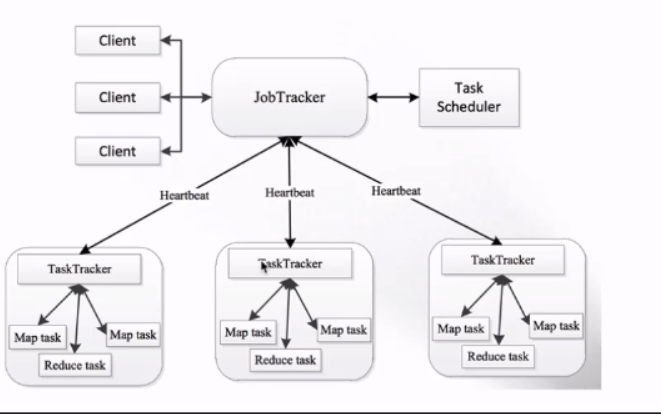
MapReduce1.x的架构
1)JobTracker:JT
作业的管理者
将作业分解成一堆的任务:Task (MapTask和ReduceTask)
将任务分派给TaskTracker运行
作业的监控,容错处理(task作业挂了,重启task的机制)
在一定的时间间隔内,JT没有收到TT的心跳信息,,TT可能是挂了 ,TT上运行的任务会被只拍到其他TT上去执行
2)TaskTracker:TT
任务的执行者 干活的
在TT上执行的我们的Task(MapTask和ReduceTask)
会与JT进行交互:执行/启动/停止作业,发送心跳信息给JT
3)MapTask
自己开发的map任务交由TASK出来
解析每条记录的数据 交给自己的map方法处理
将map的输出结果写到本地磁盘(有的作业只有map没有Reduce==>HDFS)
ReduceTask
将Map Task输出的数据进行读取
按照数据进行分组传给我们自己编写的reduce方法处理
输出结果写到HDFS
MapReduce2.x的架构
java版本wordcount功能的实现