基于UVM的verilog验证
Abstract
本文介绍UVM框架,并以crc7为例进行UVM的验证,最后指出常见的UVM验证开发有哪些坑,以及怎么避免。
Introduction
本例使用环境:ModelSim 10.2c,UVM-1.1d,Quartus II 13.1(64 bit),器件库MAX V
1. UVM介绍
对UVM结构熟悉的读者可跳过本节。
叫UVM“框架”可能并不确切(只是便于理解,可类比软件界的“框架”)。UVM全称为通用验证方法论。在硬件开发过程中,验证是十分重要的环节。可以说,左手开发,右手验证。在历史上,为了实现通用化的验证,前人摸爬滚打,创造出了UVM这一套框架。UVM前身是OVM,两者都是Accellera提出,UVM在OVM的基础上有所改进。
本文旨在用一种简单的方式介绍UVM的结构。期望读者能够读完本文后,成功搭建一个完整的UVM验证系统。
Part 1:
UVM的功能
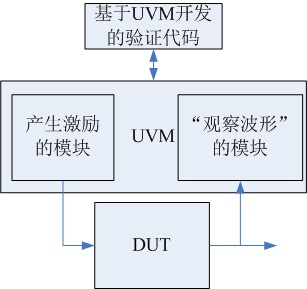
请看下图,一个典型的testbench验证过程如图所示。即,我们写testbench,将激励信号传入DUT(待验证模块),然后观察输出波形,或者查看输出结果,是否和预期的一致。通过这样的过程,我们判断我们编写的Verilog是否正确。

请看下图,UVM如同一个管家,将“输入激励”和“观察波形”的动作管理了起来。基于UVM进行开发,UVM提供了很多机制,也能够快速的产生我们想要输入的激励。
问题是,我们完全可以使用testbench解决问题,为什么还要使用UVM呢?
UVM是一个通用验证平台,基于它,我们可以产生复杂、大量、可定制化的随机激励,并可以提高大型验证工程的协作性和扩展性。举个例子,UVM框架就像软件开发的分层结构,定义好了统一的接口,那么,各个层次就可以交给各个团队来开发。验证项目也是如此,产生激励的工程如果有改动,并不会影响“观察波形”(实质是观察结果)的团队。实际上,UVM分的更细,它将各个流程都拆分开来,包括transaction、driver、sequence、sequencer、monitor、agent、test、env、top等部分。此外,UVM提供了优秀的factory机制、objection机制、reg机制,为我们简化开发过程。比如,reg机制就封装了我们在硬件开发中读写寄存器的一些操作。我们调用UVM的函数,就能够迅速的开发读写reg的过程。
Part 2:
UVM的结构
如前所述,UVM包括transaction、interface、driver、sequence、sequencer、monitor、reference model、agent、test、env、top等部分,其相互关系极其复杂。不如说,UVM牺牲简洁性换来“通用”性。
借用Pedro Araujo的结构图。
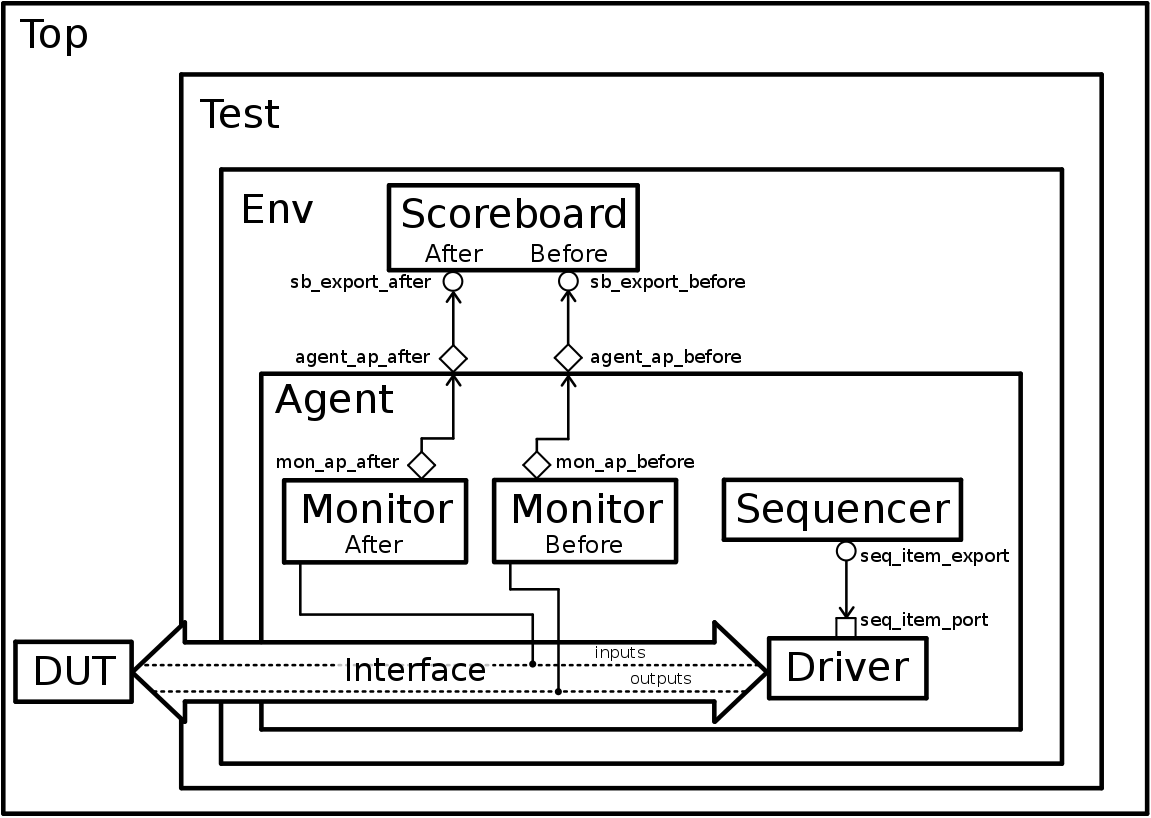
1) 正如这个图片所展示的,UVM是除了DUT(待验证模块)的其他所有部分。其中,sequencer产生sequence(图上没画),sequence产生transaction。
transaction,类似于软件中的一个package。在硬件中,以一个transaction为单位进行传输,一个完整的transaction传输结束,才拉高或拉低电平。
2)通过UVM的专门的类型——port把数据给driver。driver通过interface把产生的激励(也就是transaction)输入DUT。同时,DUT的输出也是和interface相连接的。一个monitor(monitor after)监测driver吐给DUT的输入,一个monitor(monitor before)监测DUT吐出来的输出。
3) 这里,看到一个agent把整个monitor、sequencer、driver都装起来了。这个agent实现的功能是转换。因为整个UVM都是systemverilog的,并且理论上是仿真的,都不是“硬件”。DUT在这里是真正的“硬件”。两者之间不能直接通信,只能通过一个agent,来对协议进行转换。不过,我们可以不用管agent怎么实现的。在开发的时候,只要把相关的模块连接好就行了。
4)这个图还少了一个reference model。因为reference model的工作在这个例子中,实际是在monitor after里面实现的。- -不过没关系。reference model完成的工作是,把DUT做的事完全的再做一遍。reference model接入monitor采到的输入激励,按照DUT的逻辑,产生一个结果。
5)同样通过port,把reference model产生的结果同monitor before采到的数据都丢到scoreboard上。在scoreboard上,我们会对两个结果进行比较。如果两个结果一致,则为正确。如果不一致,则为错误。
UVM本身用700页来写也完全可以。因为UVM极其复杂。本文不在此赘述。
2. 以crc7为例进行UVM的验证
Part 1:
搭建环境。
本文使用的Quartus II 13.1(64 bit),器件库MAX V。写了一个Verilog的简单的crc7。
仿真环境是ModelSim 10.2c。虽说自带UVM库。但是,没找到Modelsim自带的uvm_dpi.dll,于是,还重新编译了一番。
本文在win 10下。下载uvm-1.1d(现在最新版本有1.2d了),放好。安装好ModelSim 10.2c后,在命令提示符>后,输入
编辑环境变量
|
1
2
|
set UVM_HOME c:/tool/uvm-1.1dset MODEL_TECH c:/modeltech_10.2c/win32 |
编译UCM_DPI动态链接库。编好一次就不用再编了。
|
1
|
c:/modeltech_10.2c/gcc-4.2.1-mingw32vc9/bin/g++.exe -g -DQUESTA -W -shared -Bsymbolic -I $MODEL_TECH/../include $UVM_HOME/src/dpi/uvm_dpi.cc -o $UVM_HOME/lib/uvm_dpi.dll $MODEL_TECH/mtipli.dll -lregex |
Part 2:
编写待验证模块。

module crc7(clk,
rst,
data,
crc);
input wire clk;
input wire rst;
input wire data;
output reg[6:0] crc;
reg g0;
assign g0 = data ^ crc[6];
always @(posedge rst or negedge clk)
if (rst)
begin
crc <= 7'b0000000;
end
else
begin
crc[6] <= crc[5];
crc[5] <= crc[4];
crc[4] <= crc[3];
crc[3] <= crc[2] ^ g0;
crc[2] <= crc[1];
crc[1] <= crc[0];
crc[0] <= g0;
end
endmodule
在Quartus中编译通过。
Part 3:
编写验证代码。
在Modelsim中新建一个项目,新建如图所示多个.sv文件。
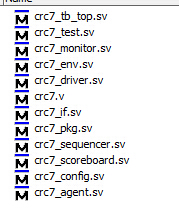
crc7_tb_top.sv如下所示
 View Code
View Codecrc7_monitor.sv如下所示
View Codecrc7_sequencer.sv如下所示
View Codecrc7_driver.sv如下所示
View Code(其余代码请在文章末尾下载。 )
其中,crc7_tb_top.sv第31行:
#5 vif.sig_clk =~ vif.sig_clk;
表示每5个时钟单位反向一次。即时钟周期为10ns。
crc7_monitor.sv中第1行和第34行,分别新建一个名为crc7_monitor_before和crc7_monitor_after的类。第26行,
c7_tx.crc = vif.sig_crc;
crc7_monitor_before类采集DUT输出的信号。本测试用例中只有一个输出信号,即计算出的crc。vif是interface类的实例。前文中说过,monitor是从interface上采集的。
第27行,
`uvm_info("monitor_before",$sformatf("c7_tx.crc is '%b'", c7_tx.crc), UVM_LOW);
使用UVM提供的宏打印格式化的数据。UVM提供的宏可类比软件中的库函数。就是无需声明,只管调用。
第28行,
mon_ap_before.write(c7_tx);
将采集到的数据写入ap中。ap是什么?ap是UVM中的port类型之一,叫analysis_port。简单说就像硬件的一个接口,协议UVM已经搞好了。我们只管读写就好了。
从第66行到第84行,都是本来应该在reference model里面实现的。就是说,从结构上来说,monitor采集到了driver发到interface上的信号,会丢给reference model来计算出一个结果(这是比较标准的结构)。本例中,由于reference model要做的事情太简单,就直接放在monitor里面做了。当monitor_after采集到了输入激励后,就在自己内部算了一把,然后把结果写出去。这就是66-84行所起的作用。由于crc7的运算结果可以查表。本例就直接查了表。也就是说,UVM完全可以实现输入激励的随机化。但是本例没用。本例使用了一对输入/输出数据。并且在第88行,直接把输出数据返回了。这对输入/输出数据为:40'b0101000100000000000000000000000000000000;7'b0101010;
同样,在第81行,
mon_ap_after.write(c7_tx);
把正确的结果写入ap。注意,ap是成对的。有写就有读。
crc7_sequencer.sv中,第26-28行,
26 start_item(c7_tx); 27 assert(c7_tx.randomize()); 28 finish_item(c7_tx)
是规定动作。有开始就有结束。随机化也是必须写的,缺一不可。
crc7_driver.sv中第33行至42行,
33 @(negedge vif.sig_clk) 34 begin 35 vif.sig_rst = 1'b0; 36 vif.sig_data = data[counter - 1]; 37 counter = counter - 1; 38 if(counter == 0) begin 39 #28 counter = 40; 40 vif.sig_rst = 1'b1; 41 end 42 end
完成的工作是,每一个时钟节拍打出data的1位。data见第24行。本来应该由sequence产生随机激励的,由于本例使用的是查表验证,因此,并没有使用UVM的随机功能。因此,要随机的数据没有在sequence里面写进去,要打入的数据在driver模块中写入了vif。这样完成了设定数据的输入。
Part 4:
编译仿真。
编译crc7_tb_top.sv,
vlog +incdir+C:/modeltech_10.2c/verilog_src/uvm-1.1d/src -L mtiAvm -L mtiOvm -L mtiUvm -L mtiUPF crc7_tb_top.sv
crc7_tb_top是整个工程的入口。
仿真crc7_tb_top,
vsim -ldflags "-lregex" -t 1ns -c -sv_lib c:/modeltech_10.2c/uvm-1.1d/win32/uvm_dpi work.crc7_tb_top
vsim的-ldflags参数是将后面的字符串“-lregex”作为参数传入到mingw里面。mingw会原封不动的传入给其调用的g++。至于为什么要这么做?因为按照命令,
vsim -c -sv_lib $UVM_HOME/lib/uvm_dpi work.hello_world_example
编译的时候报错了,提示找不到uvm_dpi。明明编译了放在对的地方,可是就是找不到。于是,将路径写死在命令里。成功仿真。
添加波形,得到波形如图(截取部分):

查看打印结果。仿真结果和正确值相比,如图所示:
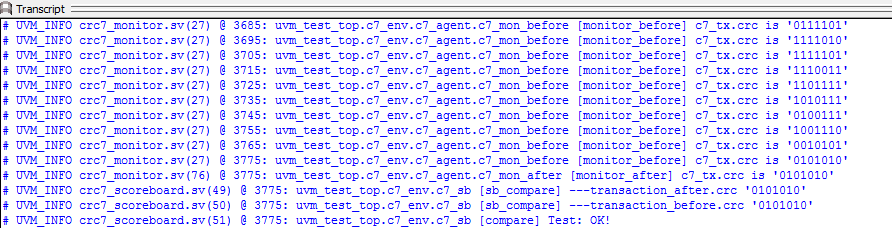
其中,每一个时钟周期打印的是,当前时刻移位后的crc7值。在40个bit结束后,移位结果为0101010,正确结果也是0101010,因此,compare OK。
3. UVM验证开发常见有哪些坑?怎样避免。
Q1:为什么状态机走入了未预料的分支?
在时钟边沿采集与时钟同样跳变的信号时,这一瞬间采集到的信号可能是高,也可能是低。此时,若做逻辑判断,可能出现无法预料的情况。
解决的方法是,加入其它逻辑判断条件,确保程序逻辑正确。
Q2:为什么reference model和DUT的结果计算时序不一致?
一般来说,一组数据经过DUT的处理,会有一定的时延。而reference model没有时延。我们希望在同一时刻,对reference model和DUT计算的结果在scoreboard中比较,则须考虑两者运行的时间差。
有两种方法解决:一是手动添加时延,比较简单,但是有可能出错;二是使用UVM的FIFO机制,把先到达的reference model输出的数据放入到一个队列中。确保仿真时间结束后,用来比较的两个结果都是基于同样的激励输入。
本文用例完整代码下载:uvm-crc-test.zip
转载自:http://www.cnblogs.com/bettty/p/5285785.html