1 //表示当前类 的路径 2 package com.cy; 3 //public 公共的,表示当前类在整个项目中都可以使用 4 //class 表示的是一个类 5 //Test 表示当前类的类名 (首字母大写) 6 //{ } 表示当前类的内容 7 public class Test { 8 9 //主方法: 程序执行的入口 10 public static void main(String[] args) { 11 12 //输出语句: 13 System.out.println("hello world"); 14 15 } 16 } 17 18 //Java程序的执行 19 /* 20 * 语言的执行: 21 * 22 * 编译型: 程序在执行之前必须通过编译 如果编译出错 则程序无法执行 : c语言 23 * 解释型: 由浏览器解释一行 执行一行: html / js 24 * 25 * Java: 26 * 先编译 再解释执行 27 * 28 * 1) java源文件(.java) 先通过编译 会生成一个对应的 class文件 29 * 2) class文件被我们称为 字节码文件 ( 字节码文件不依赖于任何的操作平台 ) 30 * 3) 字节码文件只由 java虚拟机(JVM) 解释执行 31 * 4) 任何的操作平台都可以安装 JVM 32 * 33 * 一次编译 到处运行 34 * 35 * 36 * 37 * 跨平台(操作系统:) 38 * 39 * 40 * 41 * 42 * */ 43 44 45 46 数据类型: 47 48 49 整型: 50 51 byte:(1字节) : -128 -- 127 52 short:(2字节): 正负3w多之间 53 int:(4字节) : 正负21亿之间 默认 54 long:(8字节) : 很大很大 55 56 57 浮点型: 58 59 float: 单精度(4字节) 60 double:双精度(8字节) 默认 61 62 63 64 字符型: 65 66 char: 单个符号: a * # 好 67 68 69 70 71 布尔型: true false 72 73 boolean 74 75 76 ==> Java 8大基本数据类型 77 78 79 分为两大类: 80 1.基本数据类型(简单数据类型):8个 81 2.引用数据类型(复杂数据类型): 除了上述8个基本数据类型之外 其他都是引用数据类型 82 83 区别: 84 基本数据类型在 内存中占据一块内存空间 85 引用数据类型在 内存中占据两块内存空间
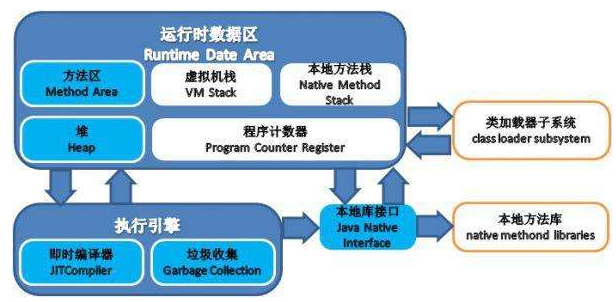
下面是栈和堆
Java堆和栈的区别和介绍以及JVM的堆和栈
java 堆 栈 jvm
发布于 2018-05-21
一、Java的堆内存和栈内存
Java把内存划分成两种:一种是堆内存,一种是栈内存。
堆:主要用于存储实例化的对象,数组。由JVM动态分配内存空间。一个JVM只有一个堆内存,线程是可以共享数据的。
栈:主要用于存储局部变量和对象的引用变量,每个线程都会有一个独立的栈空间,所以线程之间是不共享数据的。
在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配。 当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
堆内存用来存放由new创建的对象和数组。
在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。
二、栈与堆的共同点和优缺点
栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享,详见第3点。堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
Java中的数据类型有两种。
一种是基本类型(primitive types), 共有8种,即int, short, long, byte, float, double, boolean, char(注意,并没有string的基本类型)。这种类型的定义是通过诸如int a = 3; long b = 255L;的形式来定义的,称为自动变量。值得注意的是,自动变量存的是字面值,不是类的实例,即不是类的引用,这里并没有类的存在。如int a = 3; 这里的a是一个指向int类型的引用,指向3这个字面值。这些字面值的数据,由于大小可知,生存期可知(这些字面值固定定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存在于栈中。
栈有一个很重要的特殊性,就是存在栈中的数据可以共享。
假设我们同时定义
int a = 3; int b = 3;
编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找有没有字面值为3的地址,没找到,就开辟一个存放3这个字面值的地址,然后将a指向3的地址。接着处理int b = 3;在创建完b的引用变量后,由于在栈中已经有3这个字面值,便将b直接指向3的地址。这样,就出现了a与b同时均指向3的情况。
特别注意的是,这种字面值的引用与类对象的引用不同。假定两个类对象的引用同时指向一个对象,如果一个对象引用变量修改了这个对象的内部状态,那么另一个对象引用变量也即刻反映出这个变化。相反,通过字面值的引用来修改其值,不会导致另一个指向此字面值的引用的值也跟着改变的情况。如上例,我们定义完a与 b的值后,再令a=4;那么,b不会等于4,还是等于3。在编译器内部,遇到a=4;时,它就会重新搜索栈中是否有4的字面值,如果没有,重新开辟地址存放4的值;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。
另一种是包装类数据,如Integer, String, Double等将相应的基本数据类型包装起来的类。这些类数据全部存在于堆中,Java用new()语句来显式地告诉编译器,在运行时才根据需要动态创建,因此比较灵活,但缺点是要占用更多的时间。上海尚学堂java培训。
三、Java堆和栈的区别
java中堆和栈的区别自然是面试中的常见问题,下面几点就是其具体的区别
1、各司其职
最主要的区别就是栈内存用来存储局部变量和方法调用。而堆内存用来存储Java中的对象。无论是成员变量,局部变量,还是类变量,它们指向的对象都存储在堆内存中。
2、独有还是共享
栈内存归属于单个线程,每个线程都会有一个栈内存,其存储的变量只能在其所属线程中可见,即栈内存可以理解成线程的私有内存。而堆内存中的对象对所有线程可见。堆内存中的对象可以被所有线程访问。
3、异常错误
如果栈内存没有可用的空间存储方法调用和局部变量,JVM会抛出java.lang.StackOverFlowError。
而如果是堆内存没有可用的空间存储生成的对象,JVM会抛出java.lang.OutOfMemoryError。
4、空间大小
栈的内存要远远小于堆内存,如果你使用递归的话,那么你的栈很快就会充满。如果递归没有及时跳出,很可能发生StackOverFlowError问题。
你可以通过-Xss选项设置栈内存的大小。-Xms选项可以设置堆的开始时的大小,-Xmx选项可以设置堆的最大值。
这就是Java中堆和栈的区别。理解好这个问题的话,可以对你解决开发中的问题,分析堆内存和栈内存使用,甚至性能调优都有帮助。
四、JVM中的堆和栈
JVM是基于堆栈的虚拟机.JVM为每个新创建的线程都分配一个堆栈.也就是说,对于一个Java程序来说,它的运行就是通过对堆栈的操作来完成的。堆栈以帧为单位保存线程的状态。JVM对堆栈只进行两种操作:以帧为单位的压栈和出栈操作。 我们知道,某个线程正在执行的方法称为此线程的当前方法.我们可能不知道,当前方法使用的帧称为当前帧。当线程激活一个Java方法,JVM就会在线程的 Java堆栈里新压入一个帧。这个帧自然成为了当前帧.在此方法执行期间,这个帧将用来保存参数,局部变量,中间计算过程和其他数据.这个帧在这里和编译原理中的活动纪录的概念是差不多的. 从Java的这种分配机制来看,堆栈又可以这样理解:堆栈(Stack)是操作系统在建立某个进程时或者线程(在支持多线程的操作系统中是线程)为这个线程建立的存储区域,该区域具有先进后出的特性。
每一个Java应用都唯一对应一个JVM实例,每一个实例唯一对应一个堆。应用程序在运行中所创建的所有类实例或数组都放在这个堆中,并由应用所有的线程 共享.跟C/C++不同,Java中分配堆内存是自动初始化的。Java中所有对象的存储空间都是在堆中分配的,但是这个对象的引用却是在堆栈中分配,也就是说在建立一个对象时从两个地方都分配内存,在堆中分配的内存实际建立这个对象,而在堆栈中分配的内存只是一个指向这个堆对象的指针(引用)而已。
Java 把内存划分成两种:一种是栈内存,另一种是堆内存。在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配,当在一段代码块定义一个变量时,Java 就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java 会自动释放掉为该变量分配的内存空间,该内存空间可以立即被另作它用。
图片描述