在zeppelin跑spark sql 时抛了空引用的异常:
Job 20150210-015259_1403135953 is finished, status: ERROR, exception: null, result: %text java.lang.NullPointerException at org.apache.zeppelin.spark.Utils.invokeMethod(Utils.java:38) at org.apache.zeppelin.spark.Utils.invokeMethod(Utils.java:33) at org.apache.zeppelin.spark.SparkInterpreter.createSparkContext_2(SparkInterpreter.java:398) at org.apache.zeppelin.spark.SparkInterpreter.createSparkContext(SparkInterpreter.java:387) at org.apache.zeppelin.spark.SparkInterpreter.getSparkContext(SparkInterpreter.java:146) at org.apache.zeppelin.spark.SparkInterpreter.open(SparkInterpreter.java:843) at org.apache.zeppelin.interpreter.LazyOpenInterpreter.open(LazyOpenInterpreter.java:70) at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:491) at org.apache.zeppelin.scheduler.Job.run(Job.java:175) at org.apache.zeppelin.scheduler.FIFOScheduler$1.run(FIFOScheduler.java:139) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
上stackoverflow查了一下,有人也遇到这个问题。其中的一个原因是自己的环境没有安装hive,却启用了hiveContext,导致出异常。
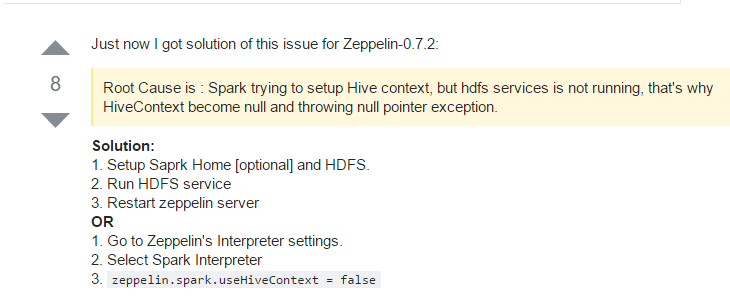
设置zeppelin.spark.useHiveContext = false 后问题不再出现。