hbase的安装
①cp /mnt/hgfs/xiazai/hbase-1.2.5-bin.tar.gz /data
tar -xzvf hbase-1.2.5-bin.tar.gz
②环境
sudo nano /etc/environment
HBASE_HOME=/data/hbase-1.2.5-bin
Path=”: /data/hbase-1.2.5-bin/bin”
因为hbase需要运行在集群上所以需要发送给多台机器
xsync /data/hbase-1.2.5-bin
将每台的环境配好
配置
①解压hbase-1.2.5-bin.tar.gz
找到lib/hbase-common.jar-.default
②配置本地模式:
sudo nano hbase-site.xml 添加
<property>
<name>hbase.rootdir</name>
<value>file:///home/neworigin/hbase</value>
</property>
(会自己创建hbase、文件夹,自己创建hi丢失文件)
③启动:start-hbase.sh
jps
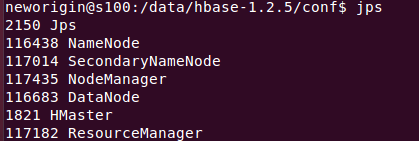
④进入hbase终端
hbase shell
通用命令:
status:查看hbase的状态

version:查看当前hbase版本
whoami:查看当前的用户信息

操作语言:
help查看命令
由001变成002(记录操作次数)
help “create”查看create的使用方法
l 创建表:create ‘test’,‘cf1’,‘cf2’
l 显示所有表:list
l 插入数据:put ‘test’,‘row1’,‘cf1:name’,’lisa’
l 描述表:describe ‘test’
l 扫描整张表:scan ‘test’
l 获取表的某一行数据:get ‘test’,’row1’
l 删除表
删表之前需要disable(禁用)
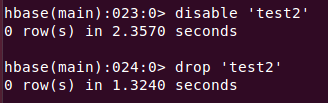
exit/quit退出hbase终端
关闭:stop-hbase.sh
访问hbase中table的行的三种方式:
- 通过单个row key访问
- 通过row key的正则
- 全表扫描
row key可以是任意字符串(最大长度是64kb)在hbase内部,row key保存为字节数组,存储时按照row key的字典序排序
列簇:hbase中的每一列都归属于某一列簇,列名以列簇作为前缀,
例如:course:math,course:chinese
hbase的运行模式:单机,伪分布,完全分布式
单机模式:hbase使用本地文件系统,服务和zookeeper都运行在一个jvm中
配置完全分布模式:
①修改hbase-site.xml文件
<property>
<name>hbase.rootdir</name>
<value>hdfs://s100:8020/hbase</value>//数据保存在hdfs上
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>//使用完全分布式
</property>
#zk conf
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value> // zk端口号
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>s100, s101, s102</value>//zk的服务器
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/neworigin/hbase/zk</value>
</property>//保存数据的目录,配置后自动创建
②修改regionservers
s100
s101
s102
③修改hbase-enc.sh:export HBASE_MANAGES_ZK=false
将配置好的文发送到其他机器上:
xsync ①②③
启动:
①启动zookeeper:zkServer.sh start
②启动集群:start-all.sh
③启动hbase:start-hbase.sh
查看:
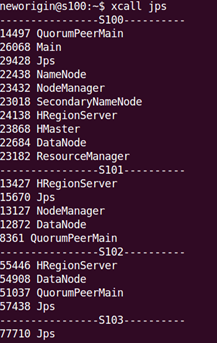
查看webui:
s100:16010 //master webui
s101:16030 //regionserver webui