1.1、Hadoop常用端口号
- dfs.namenode.http-address:50070
- dfs.datanode.http-address:50075
- SecondaryNameNode辅助名称节点端口号:50090
- dfs.datanode.address:50010
- fs.defaultFS:8020 或者9000
- yarn.resourcemanager.webapp.address:8088
- 历史服务器web访问端口:19888
1.2、Hadoop配置文件以及简单的Hadoop集群搭建
(1)配置文件:
- core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
- hadoop-env.sh、yarn-env.sh、mapred-env.sh、slaves
(2)简单的集群搭建过程:
- JDK安装
- 配置SSH免密登录
- 配置hadoop核心文件:
- 格式化namenode
1.3、HDFS读流程和写流程
这个很重要, 虽然现在Hadoop已经到了3.x, 存储也越来越多样化,但是HDFS还是主流的存储,我们需要知道HDFS的读写流程。
1.3.1、HDFS 读流程
1.3.2、HDFS 写流程
1.3.3、MapReduce流程
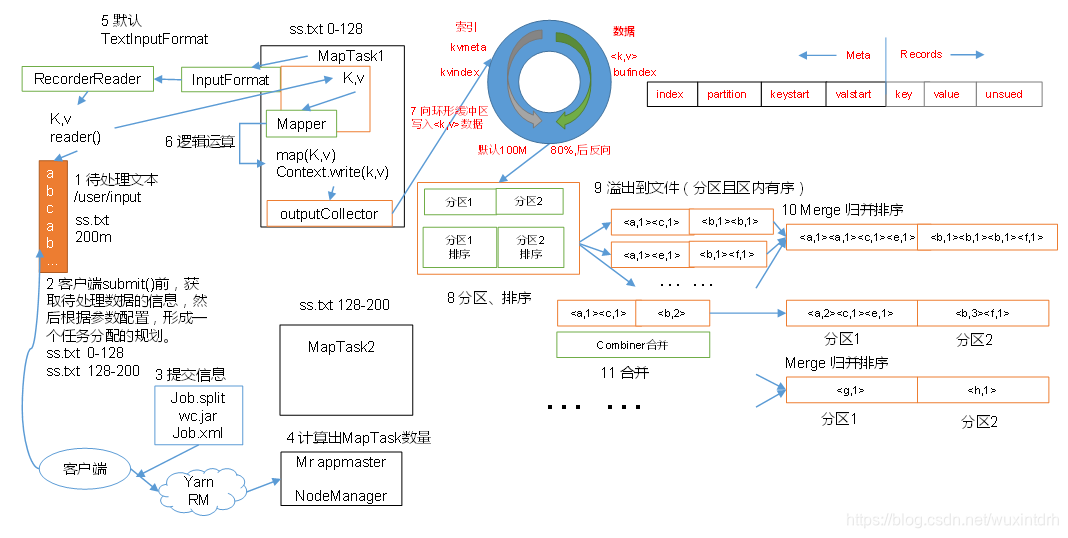
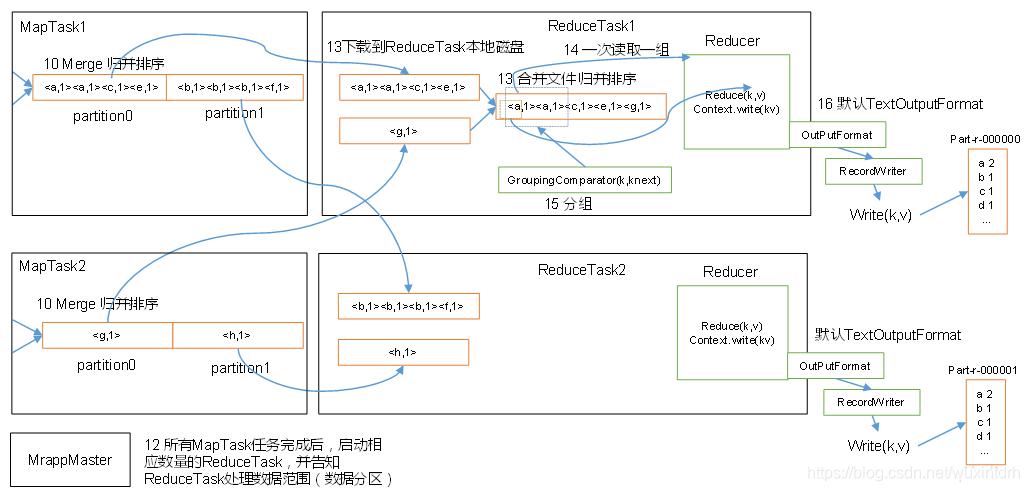
1.3.3.1、Shffule机制
1)Map方法之后Reduce方法之前这段处理过程叫Shuffle
2)Map方法之后,数据首先进入到分区方法,把数据标记好分区,然后把数据发送到环形缓冲区;环形缓冲区默认大小100m,环形缓冲区达到80%时,进行溢写;溢写前对数据进行排序,排序按照对key的索引进行字典顺序排序,排序的手段快排;溢写产生大量溢写文件,需要对溢写文件进行归并排序;对溢写的文件也可以进行Combiner操作,前提是汇总操作,求平均值不行。最后将文件按照分区存储到磁盘,等待Reduce端拉取。
3)每个Reduce拉取Map端对应分区的数据。拉取数据后先存储到内存中,内存不够了,再存储到磁盘。拉取完所有数据后,采用归并排序将内存和磁盘中的数据都进行排序。在进入Reduce方法前,可以对数据进行分组操作。
1.4、Hadoop优化
1.4.1、HDFS小文件影响
- (1)影响NameNode的寿命,因为文件元数据存储在NameNode的内存中
- (2)影响计算引擎的任务数量,比如每个小的文件都会生成一个Map任务
1.4.2、数据输入小文件处理:
- (1)合并小文件:对小文件进行归档(Har)、自定义Inputformat将小文件存储成SequenceFile文件。
- (2)采用ConbinFileInputFormat来作为输入,解决输入端大量小文件场景。
- (3)对于大量小文件Job,可以开启JVM重用。
1.4.3、Map阶段
- (1)增大环形缓冲区大小。由100m扩大到200m
- (2)增大环形缓冲区溢写的比例。由80%扩大到90%
- (3)减少对溢写文件的merge次数。
- (4)不影响实际业务的前提下,采用Combiner提前合并,减少 I/O。
1.4.4、Reduce阶段
- (1)合理设置Map和Reduce数:两个都不能设置太少,也不能设置太多。太少,会导致Task等待,延长处理时间;太多,会导致 Map、Reduce任务间竞争资源,造成处理超时等错误。
- (2)设置Map、Reduce共存:调整slowstart.completedmaps参数,使Map运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间。
- (3)规避使用Reduce,因为Reduce在用于连接数据集的时候将会产生大量的网络消耗。
- (4)增加每个Reduce去Map中拿数据的并行数
- (5)集群性能可以的前提下,增大Reduce端存储数据内存的大小。
1.4.5、IO传输
- (1)采用数据压缩的方式,减少网络IO的的时间。安装Snappy和LZOP压缩编码器。
- (2)使用SequenceFile二进制文件
1.4.6、整体
- (1)MapTask默认内存大小为1G,可以增加MapTask内存大小为4-5g
- (2)ReduceTask默认内存大小为1G,可以增加ReduceTask内存大小为4-5g
- (3)可以增加MapTask的cpu核数,增加ReduceTask的CPU核数
- (4)增加每个Container的CPU核数和内存大小
- (5)调整每个Map Task和Reduce Task最大重试次数
1.5、压缩
| 压缩格式 | Hadoop自带? | 算法 | 文件扩展名 | 支持切分 | 换成压缩格式后,原来的程序是否需要修改 |
|---|---|---|---|---|---|
| DEFLATE | 是,直接使用 | DEFLATE | .deflate | 否 | 和文本处理一样,不需要修改 |
| Gzip | 是,直接使用 | DEFLATE | .gz | 否 | 和文本处理一样,不需要修改 |
| bzip2 | 是,直接使用 | bzip2 | .bz2 | 是 | 和文本处理一样,不需要修改 |
| LZO | 否,需要安装 | LZO | .lzo | 是 | 需要建索引,还需要指定输入格式 |
| Snappy | 否,需要安装 | Snappy | .snappy | 否 | 和文本处理一样,不需要修改 |
提示:如果面试过程问起,我们一般回答压缩方式为Snappy,特点速度快,缺点无法切分(可以回答在链式MR中,Reduce端输出使用bzip2压缩,以便后续的map任务对数据进行split)
1.6、切片机制
1)简单地按照文件的内容长度进行切片
2)切片大小,默认等于Block大小
3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
提示:切片大小公式:max(0,min(Long_max,blockSize))
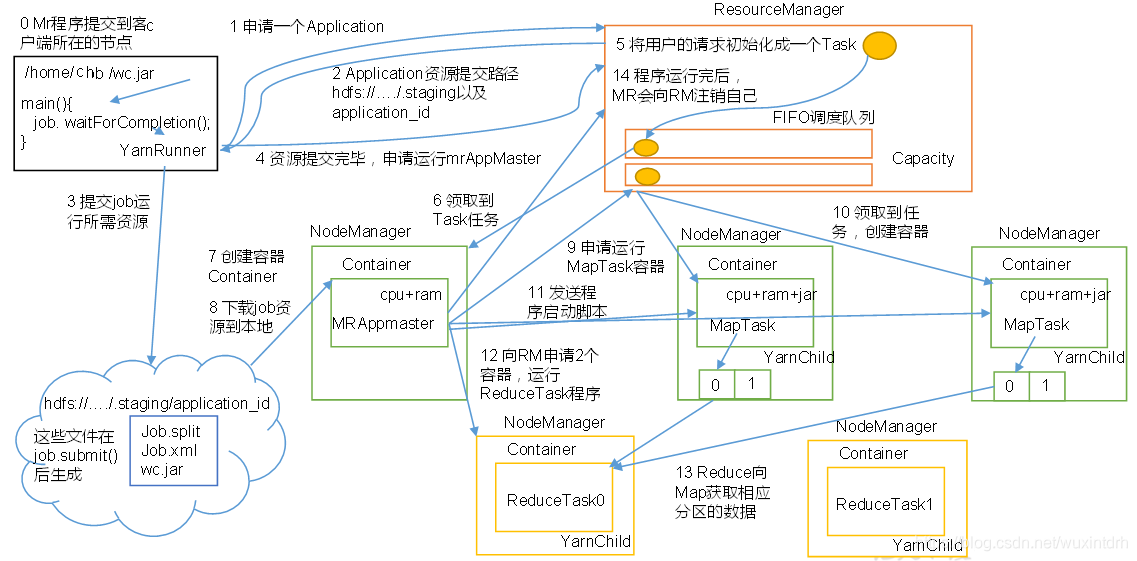
1.7、Yarn的Job提交流程
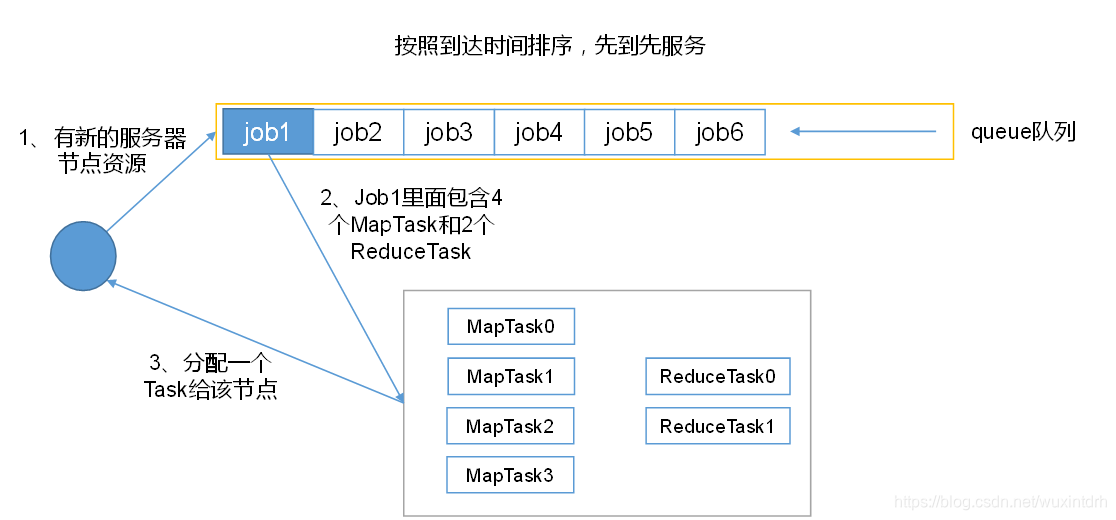
1.7.1、Yarn的默认调度器、调度器分类、以及他们之间的区别
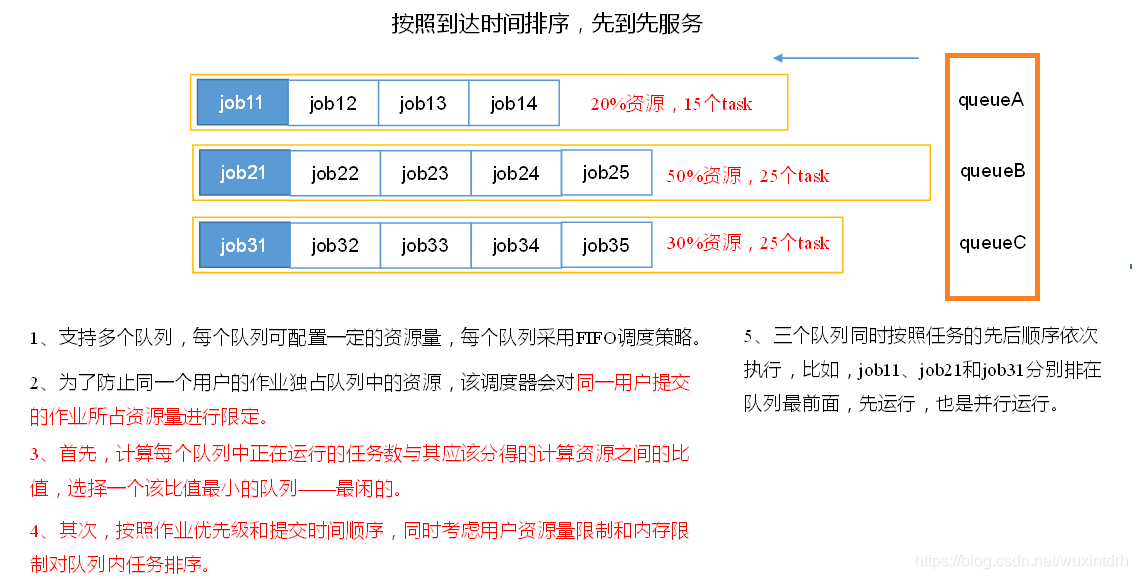
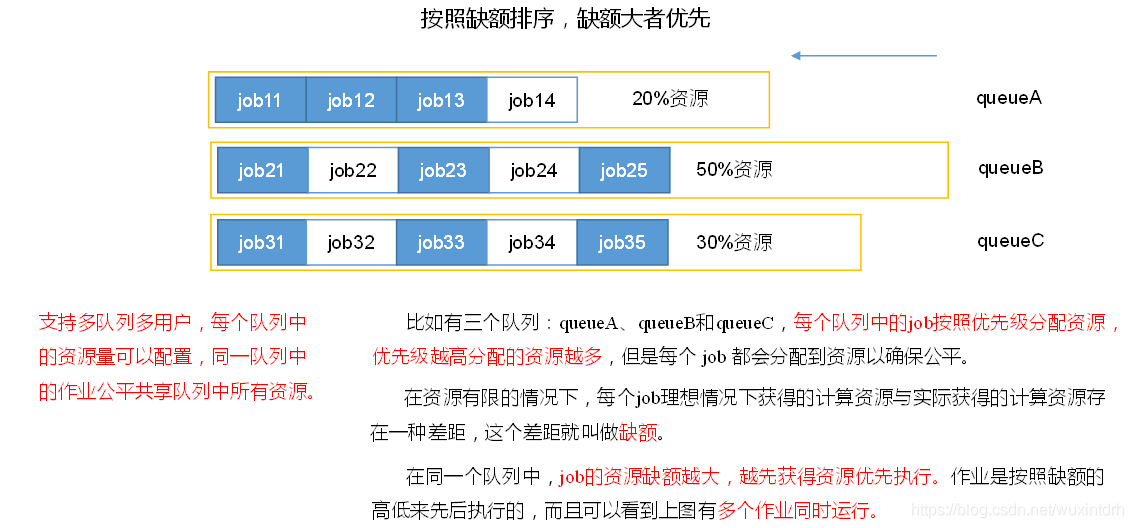
1)Hadoop调度器重要分为三类:
- FIFO 、Capacity Scheduler(容量调度器)和Fair Sceduler(公平调度器)。
- Hadoop2.7.2默认的资源调度器是 容量调度器
2)区别:
-
FIFO调度器:先进先出,同一时间队列中只有一个任务在执行。
-
容量调度器:多队列;每个队列内部先进先出,同一时间队列中只有一个任务在执行。队列的并行度为队列的个数。
-
公平调度器:多队列;每个队列内部按照缺额大小分配资源启动任务,同一时间队列中有多个任务执行。队列的并行度大于等于队列的个数。
1.8、Hadoop参数调优
1)在hdfs-site.xml文件中配置多目录,最好提前配置好,否则更改目录需要重新启动集群
2)NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
dfs.namenode.handler.count=20 * log2(Cluster Size),比如集群规模为10台时,此参数设置为60
3)编辑日志存储路径dfs.namenode.edits.dir设置与镜像文件存储路径dfs.namenode.name.dir尽量分开,达到最低写入延迟
4)服务器节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。yarn.nodemanager.resource.memory-mb
5)单个任务可申请的最多物理内存量,默认是8192(MB)。yarn.scheduler.maximum-allocation-mb
1.9、Hadoop宕机
1)如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)
2)如果写入文件过量造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。高峰期的时候用Kafka进行缓存,高峰期过去数据sync会自动跟上。
关注我的公众号 【宝哥大数据】
