首先 在SQL中 分组操作group by是对行记录的拆分
在pandas中 分组操作groupby可以选择对行或者列进行拆分
pandas分组之后可以根据每组的组名value(非列名)访问部分数据 因为分组后默认以组名作为索引 groupby默认参数as_index=True
如果设置as_index=False 分组后所有的列名不变
类似于SQL中 group by之后的having 分组列名=value
最后都是用聚合方法 合并计算数据
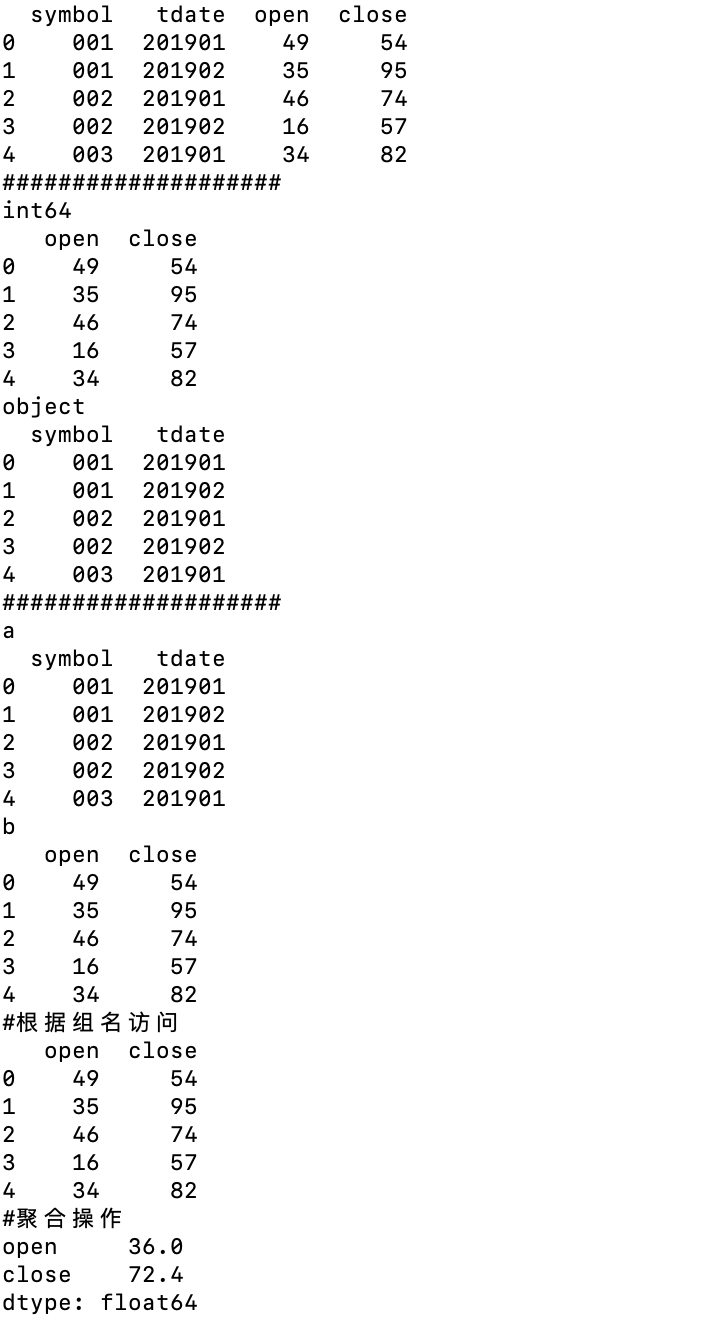
1 import numpy as np 2 import pandas as pd 3 from pandas import DataFrame,Series 4 df1=DataFrame({'symbol':['001','001','002','002','003'], 5 'tdate':['201901','201902','201901','201902','201901'], 6 'open':np.random.randint(0,50,5), 7 'close':np.random.randint(50,100,5)}) 8 9 print(df1) 10 11 grp1=df1.groupby('symbol') 12 grp2=df1.groupby(['symbol','tdate']) 13 14 print('#可用循环语句访问组名和每组的内容') 15 for name,group in grp1: 16 print(name) 17 print(group) 18 19 print('#通过组名访问数据') 20 print(grp1.get_group('001')) 21 print(grp2.get_group(('001','201901'))) 22 23 print('#计算指定列的均值 三种等价写法') 24 print(grp1.open.mean()) 25 print(grp1.open.agg('mean')) #这里函数mean要加引号 如果是自定义函数不需要 26 print(grp1.agg({'open':'mean'})) #这里指定了列名 返回DataFrame而非Series 27 28 print('#计算指定列的指定聚合方法') 29 def my_func(x): 30 return max(x)-min(x) 31 print(grp1.open.agg(my_func)) 32 print(grp1.open.agg(lambda x:max(x)-min(x))) #用匿名函数 33 34 print('#对指定列进行计算处理') 35 print(grp1.open.apply(lambda x:x+100))
结果如下图

同时 pandas可以直接对列进行拆分 设置groupby 参数axis=1即可
这个在SQL中是难以做到的
1 import numpy as np 2 import pandas as pd 3 from pandas import DataFrame,Series 4 df1=DataFrame({'symbol':['001','001','002','002','003'], 5 'tdate':['201901','201902','201901','201902','201901'], 6 'open':np.random.randint(0,50,5), 7 'close':np.random.randint(50,100,5)}) 8 9 print(df1) 10 11 print('#'*20) 12 13 grp3=df1.groupby(df1.dtypes,axis=1) 14 grp4=df1.groupby({'symbol':'a','tdate':'a','open':'b','close':'b'},axis=1) 15 16 for name,group in grp3: 17 print(name) 18 print(group) 19 20 print('#'*20) 21 22 for name,group in grp4: 23 print(name) 24 print(group) 25 if name=='b': 26 print('#根据组名访问') 27 print(grp4.get_group(name)) 28 print('#聚合操作') 29 print(grp4.get_group(name).mean())
结果如下图
谢谢!