AttentiveNAS
2021-CVPR-AttentiveNAS Improving Neural Architecture Search via Attentive Sampling
来源:ChenBong 博客园
- Institute:Facebook,University of Texas
- Author:Dilin Wang,Meng Li,Chengyue Gong,Vikas Chandra1
- GitHub:https://github.com/facebookresearch/AttentiveNAS 26+
- Citation: /
Introduction
基于共享参数的超网训练的one-shot nas方法,每个batch采样的时候不是随机采样,而是采样pareto最优和最差的子网进行训练。超网训练完毕后,无需重训可以同时获得多个flops规模下的高性能模型。
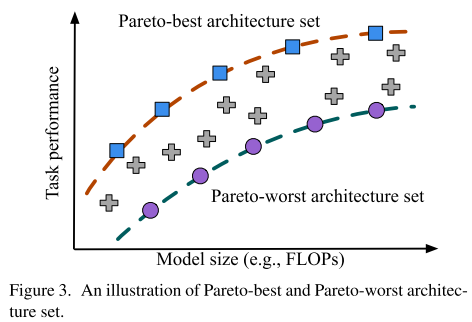
Motivation
传统的基于超网的nas,训练超网阶段:随机采样;搜索子网阶段:搜索pareto最优的子网;训练阶段和超网阶段的目标存在gap,即训练超网阶段没有把大部分训练资源集中在pareto最优的子网上,导致搜索阶段搜索到子网后还需要retrain。
本文就是在训练超网阶段就识别出pareto最优和最差的子网进行训练,对pareto最差的子网也训练的动机是:pareto最差网络,可以视为性能下限 / 训练最不充分的样本 / 困难样本,提高下限对所有子网的性能提升都有帮助。
Contribution
- 提出了一种新的采样策略,重点采样pareto最优和最差的子网
- 提出高效的采样方法
- sota
Method
传统超网nas
训练超网阶段
优化目标:
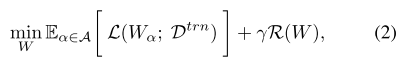
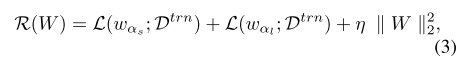
搜索子网阶段
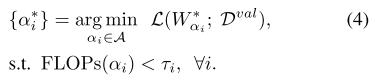
AttentiveNAS
训练超网阶段
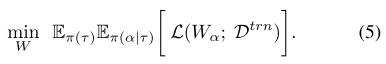
(pi_{( au)}) 是 FLOPs 服从的分布(按照超网中不同子网的FLOPs分布进行采样/训练 &&有什么好处?)
(pi_{(alpha | au)}) 是在FLOPs 为 ( au) 的条件下,子网结构服从的均匀分布
但AttentiveNAS的优化目标是那些属于pareto最优或最差集合的子网结构,因此优化目标变为:
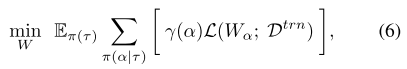
其中 (gamma(alpha)) 是一个指示函数,当 (alpha) 属于最优/最差时, (gamma(alpha)) =1
实际的做法:每个batch,对于n个目标 FLOPs ({ au_o}) ,在每个目标FLOPs约束下均匀采样k个(若k=1,就退化成随机采样)子网,选择k个子网中pareto最好/最差的1个进行训练:
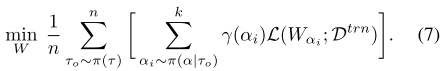
如何判断 (alpha) 属于最优/最差集合?指示函数 (gamma(alpha)) :对k个子网使用性能评估器 (P(alpha)) 进行评估,性能最高的认为是pareto最优集合;性能最差的认为是pareto最差集合

搜索子网阶段
进化算法
Experiments
训练超网的细节
如何获得子网 FLOPs 的先验分布?
从超网中随机采样m((m>10^6))个子网,统计它们的FLOPs,将采样频率近似为将概率:
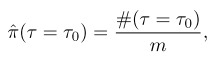
这里的 ( au= au_o) 是有一个容忍度 (t=25M) FLOPs 的
如何获得子网在 (FLOPs = au_o) 约束下的分布?
在 (FLOPs = au_o) 的约束下,子网 (α = [o_1, ..., o_d] ∈ R^d) 的分布近似为 一个连乘积:
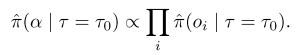
由于每一维都是独立采样的,因此其中每一项都可以用采样频率近似概率:
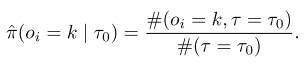
性能评估器 (P(alpha))
2种类型:
- Minibatch-loss as performance estimator: (P(α) = −L(W_α; D_{val}))
- Accuracy predictor as performance estimator:训练一个精度预测器, (P(alpha)=acc_{predict}) ,增加的开销小于总开销的10%
采样结果分析
采样集合 - 每个batch采样子网的个数k (评估器类型)


箱式图:可以体现数据分布的5个特征(最大最小值,中位数,第1/3四分位数)
- 只训练worstup可以提高下限
- 使用 acc predictor 作为评估器时,只训练worstup比只训练bestup效果更好,甚至WorstUp-1M (acc) 完全超过了 BestUp-1M (acc),这个观察挑战了那些更多关注在优化最佳结构的nas方法(DARTS)
- WorstUp-3 (loss) 和 BestUp-3 (loss) 都比 baseline(均匀采样)有提升,说明了优化最好/最差子网的有效性 (&&这里为什么换成loss作为评估器?)
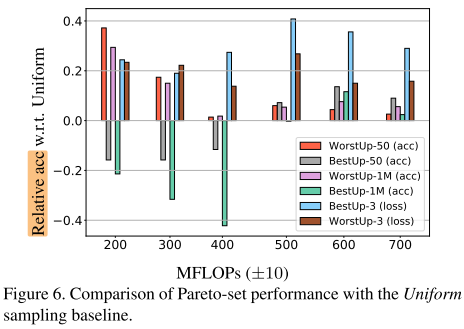
- 只训练 bestup 在中等规模的FLOPs约束(500-700M)下更有效
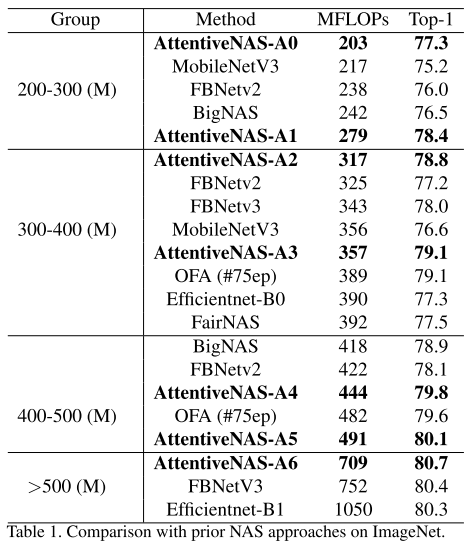
与SOTA的比较
Conclusion
Summary
pros:
- motivation明确(和greednas相同),但实现的方式更简洁,直接修改采样概率
- 采样概率考虑到FLOPs先验、子网分布先验等,求先验分布的方式很简洁,直接通过采样来近似
- 只优化pareto最差的网络也有很好的效果,挑战了之前的的一些只优化pareto最优的方法(greednas,DARTS)
cons:
- 2种评估器(acc predictor/loss)的区别没有做具体的分析
- 为什么只训练pareto最优的子网在中等规模的FLOPs(500-700M)下更有效没有做具体的分析