Once for All
2020-ICLR-Once for All Train One Network and Specialize it for Efficient Deployment
来源:ChenBong 博客园
- Institute:MIT
- Author:Han Cai,Song Han
- GitHub:https://github.com/mit-han-lab/once-for-all 【1k+】
- Citation: 100+
Introduction
训练:先训练一个大网络,再逐步收缩子网大小(四个维度:深度,宽度,kernel size,input size;广义上的剪枝),微调大网络中的子网,使得大网络中的任意子网都能达到很好的精度。
搜索/部署:
- 从大网络中采样一定量的(子网结构,acc),训练一个小的网络:acc predicter,根据目标硬件构建查找表:latency predicter;
- 之后再根据部署平台的需求(FLOPs、Params、latency...)在训练好的大网络中,使用2个predicter来搜索满足需求的最佳子网,直接部署。
和 nas 中one-shot训练超网的思想基本相同,区别在于one-shot的超网只是作为acc predicter,从超网中采出来的子网直接推理的性能和真实性能存在很大的gap,因此搜到最佳结构后还需要retrain。
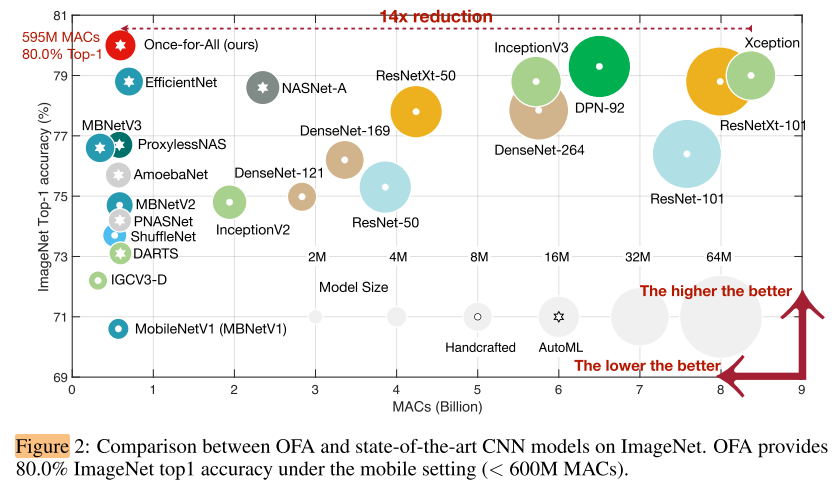
- 箭头增加了图片的易读性
- 二维图表达了多维信息(MACs,acc,params,model设计方式)
Motivation
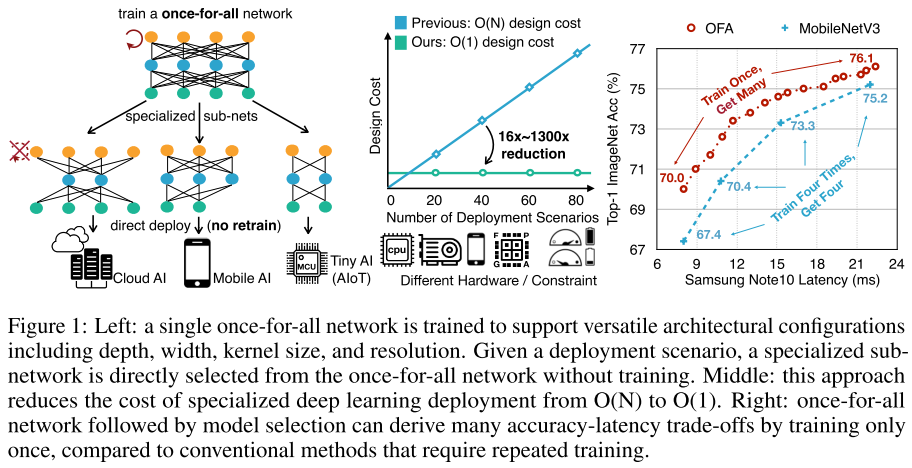
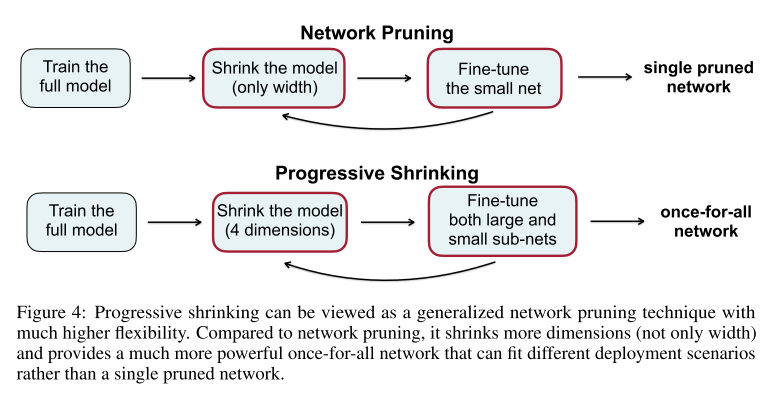
不同的设备需求都不同,为每个设备单独设计网络需要很高的成本(nas中非one-shot类方法不同需求都要单独搜索;one-shot类方法在超网中搜到满足需求的最佳结构后,都得retrain)。
要实现只训练一次,就要设计一个性能良好的超网,并且保证其中包含的子网性能都很好;
困难:
- 子网太多,无法同时训练所有子网
- 如果只是每步随机采样几个子网,会带来显著的acc drop
- 子网之间是耦合的,会互相干扰,所以要保证所有子网性能都很好很困难
Contribution
一次训练,到处部署。
Method
过程
- 训练:先正常训练一个最大的超网
- fine-tune:对超网进行渐进式收缩训练,使得所有子网都有比较好的性能
- 搜索:根据目标需求,使用2个predicter进行搜索
超网的设计
大网络的设计,如何实现4个维度的变化?
弹性卷积核大小
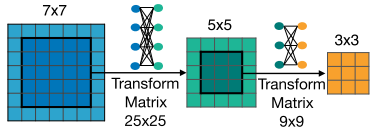
不同大小的卷积核共用中心部分的权重,考虑到3x3卷积核的权重分布和5x5中心部分的权重的分布可能是不同的,因此从7x7 crop出中心5x5的权重时,加入了一个全连接层,作一些非线性的变换;同理从5x5 crop出3x3的权重时,也要经过一个全连接层。
每一层需要 25x25+9x9 个额外参数。
弹性深度(卷积层的层数)
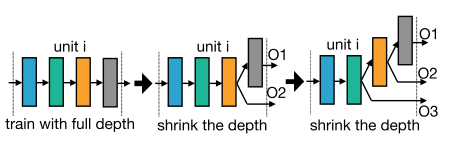
网络由不同的unit(block)组成,每个block的第1层的stride=2,其余层stride=1。当要一个block选择不同的层数时,固定选择top k个层,跳过后面的层。
弹性宽度(每一层卷积核个数)
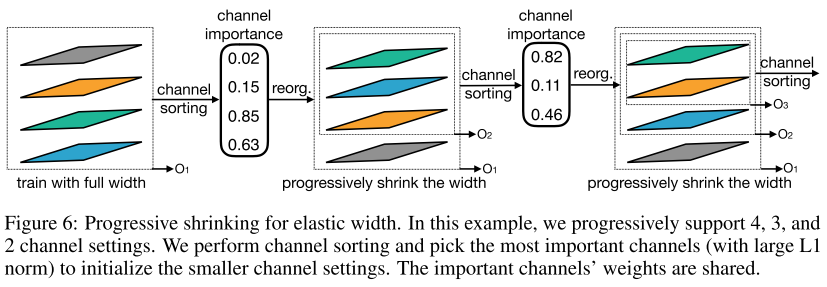
每一层选哪些通道,按L1重要性排序后,选择最重要的top k个通道。
搜索空间:
使用MobileNet V3作为 backbone:
- 卷积核大小:{3,5,7}
- 深度:{2,3,4}
- 宽度:{3,4,6}
子网空间:(2×10^{19})
弹性分辨率
- 分辨率:{128 to 224 with stride 4},25种
超网的 训练=>fine-tune=>部署 流程
超网的训练
使用最大卷积核大小/深度/宽度/分辨率进行训练,得到 ofa_D4_E6_K7
超网的 fine-tune:progressive shrinking(PS)
使用训练好超网作为teacher,采样子网作为student,
教师网络都是 ofa_D4_E6_K7
- 将{3,5}的卷积核大小加入采样空间进行训练,得到权重ofa_D4_E6_K357
- 将{3}的深度大小加入采样空间进行训练,得到权重ofa_D34_E6_K357
- 将{2}的深度大小加入采样空间进行训练,得到权重ofa_D234_E6_K357
- 将{4}的宽度大小加入采样空间进行训练,得到权重ofa_D234_E46_K357
- 将{3}的宽度大小加入采样空间进行训练,得到权重ofa_D234_E346_K357
ofa_D234_E346_K357即为最终PS训练完成的模型权重。
&& 这里的 teacher ofa_D4_E6_K7 是固定的还是变化的?
是否使用PS的对比:

时间开销:1200 GPU hours(V100)
- 举例说明PS对不同子网的性能提高都是有效的
- 不同子网(从最小233,到最大467)
部署
采样16K个sub-model,获得 16K 组 (arch+resolution, acc),用来训练一个 acc predicter(arch, resolution)=acc(3层的fc,每层400个神经元)
根据目标硬件,构建 lookup table:latency predicter(arch, resolution)=latency
时间开销:40 GPU hours
1/2是训练,3是搜索,通过以上方式,将训练和搜索解耦,只需要训练一次,之后无论有多少个硬件平台,都只需要进行搜索。
Experiments
compare with nas on mobile(300/600M FLOPs)
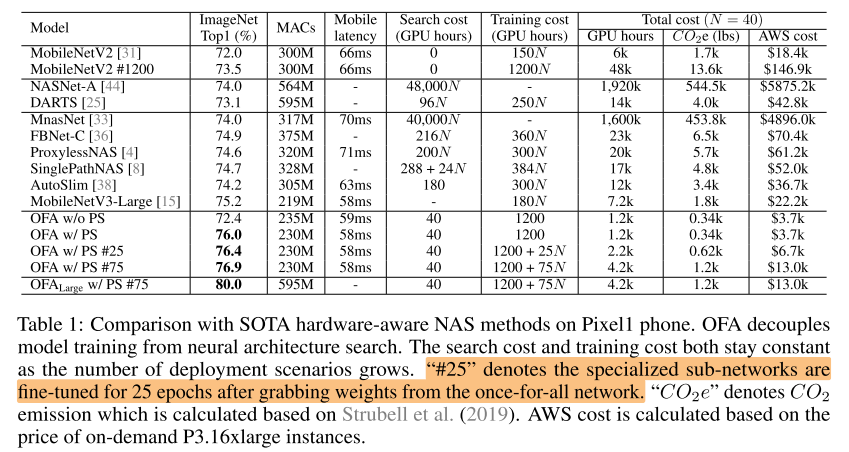
- (CO_2) 和 AWS cost
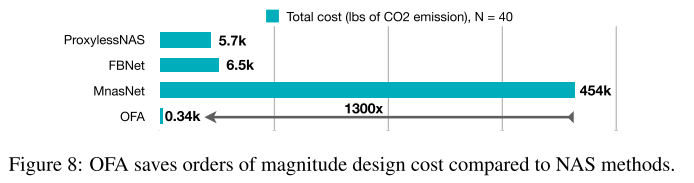
- 重点强调了当目标硬件平台N增加时,搜索成本的对比
- 选择CO2作为指标,体现方法的环境友好
Different Constraints(FLOPs/latency)
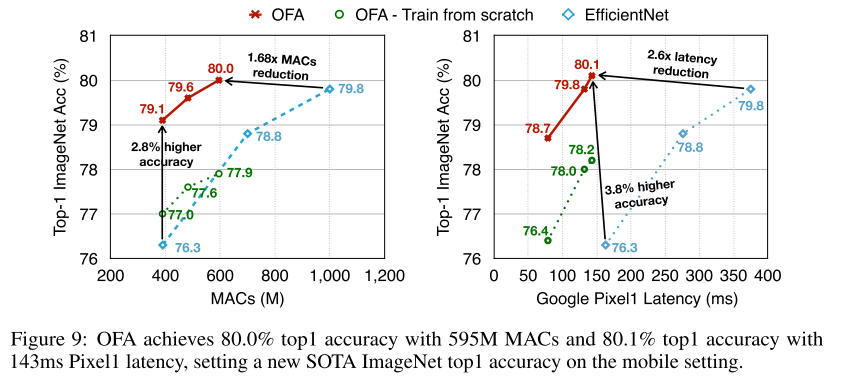
图里的OFA应该是fine-tune 75个epoch后的精度。
- 箭头直接表达了数量变化,更直观
- 左右对比,表达对不同约束 (FLOPs/latency) 都有很好的效果
- OFA超网中采样出来的子结构,比相同结构train from scratch 还有更好(性能不仅取决于结构,还取决于初始化的权重,KD等)
Diverse Hardware Platforms
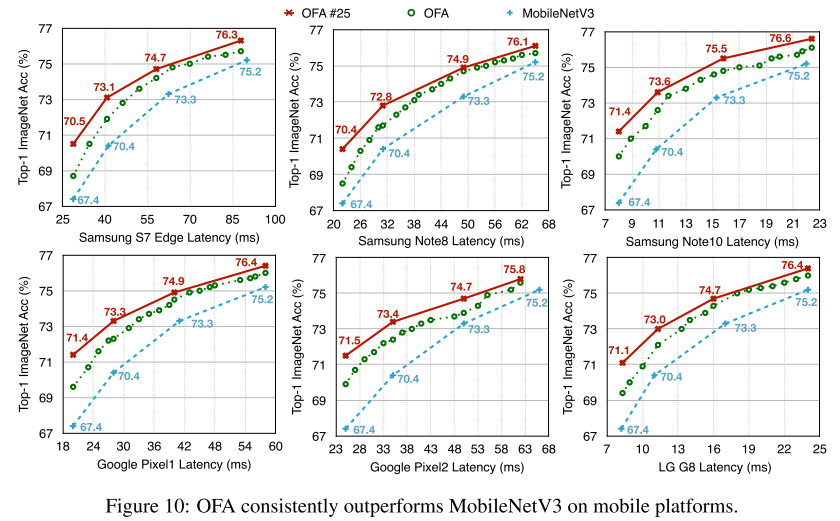
- 6张图,表达OFA超网对不同平台的适应能力
- 单张图的绿/蓝线,表达OFA超网直接采样的subnet都比 MBV3 要好
- 单张图的红/蓝线,表达OFA超网直接采样的subnet进一步fine-tune,性能还能继续提高
ACC predicter
At convergence, the root-mean-square error (RMSE) between predicted accuracy and estimated accuracy on the test set is only 0.21%.
Conclusion
Summary
- 没有说明为什么PS的方式就可以消除子网之间的互相干扰
- 直接从超网采样子网直接推理就能达到超越独立训练的精度,有点反直觉(子网继承超网权重、KD的影响;重用学习到的知识)
- 开源了OFA Full model,以及acc predicter,任何人都可以下载下来根据自己的需求搜索子网,直接部署,有比较高的工程价值
- 配图质量很高
To Read
Reference
https://openreview.net/forum?id=HylxE1HKwS
https://zhuanlan.zhihu.com/p/80952768
https://zhuanlan.zhihu.com/p/137086377
https://blog.csdn.net/weixin_39505272/article/details/100184165
https://blog.csdn.net/iamxiaoluoli/article/details/112394176
https://www.linkresearcher.com/theses/0f08e576-fc39-4449-9138-9f489e7b6a08