Shape Adaptor
2020-ECCV-Shape Adaptor: A Learnable Resizing Module
来源:ChenBong 博客园
- Institute:Imperial College London,Adobe Research
- Author:Shikun Liu,Zhe Lin,Edward Johns,etc.
- GitHub:https://github.com/lorenmt/shape-adaptor 【50+】
- Citation:/
Introduction
Prepare
- network shape: 我们将整个 network 的各层 feature map 大小定义为 network shape 。
- layer 类型:human-designed CNN 一般由2种 layer 组成:
- 1)normal layer,即不 reshape feature map 大小的 layer(如 stride-1 conv)
- 2)resizing layer,即 reshape feature map 大小的层(如max/avg pooling,down sampling,stride-2 conv)
- reshape factor:网络层对 feature map 大小的改变系数 (reshape factor = width_{out} / width_{in}) ,e.g. normal layer:reshape factor=1,resizing layer:reshape factor=0.5 or 2
- Shape Adaptor:可动态调整 reshape factor 的 resizing layer
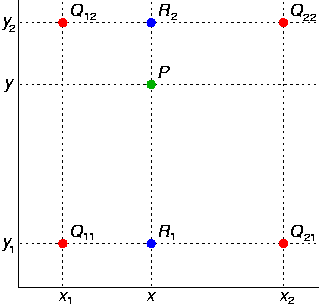
- 如何做任意实数值的 resize ?
- 双线性插值(Bilinear Interpolation)
- 本文的方法只在网络中插入 可调整 resizing factor 的 resizing layer (即Shape Adaptor),并不修改卷积层:
Shape Adaptor 介绍
- 本文提出 Shape Adaptor 方法,通过在网络不同深度位置中插入多个 shape adaptor(resizing layer),在训练中逐渐通过修改 resizing layer 的 reshape factor 来调整网络各层的输出 feature map 的大小,使 network shape 收敛到一个合适的值,达到最高的精度,训练 shape adaptor 的过程也是训练网络权重的过程,因此无需 fine-tune 的过程。
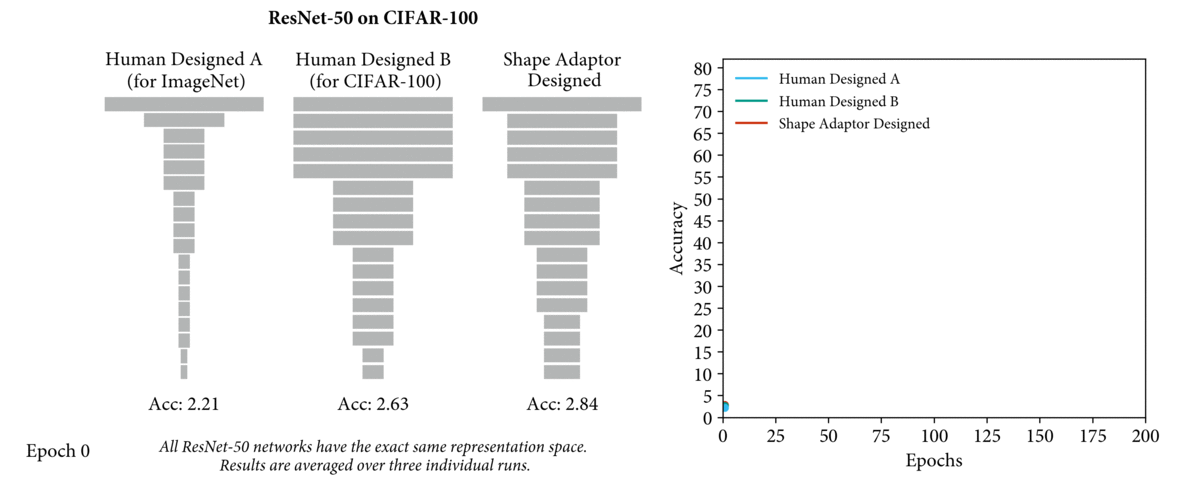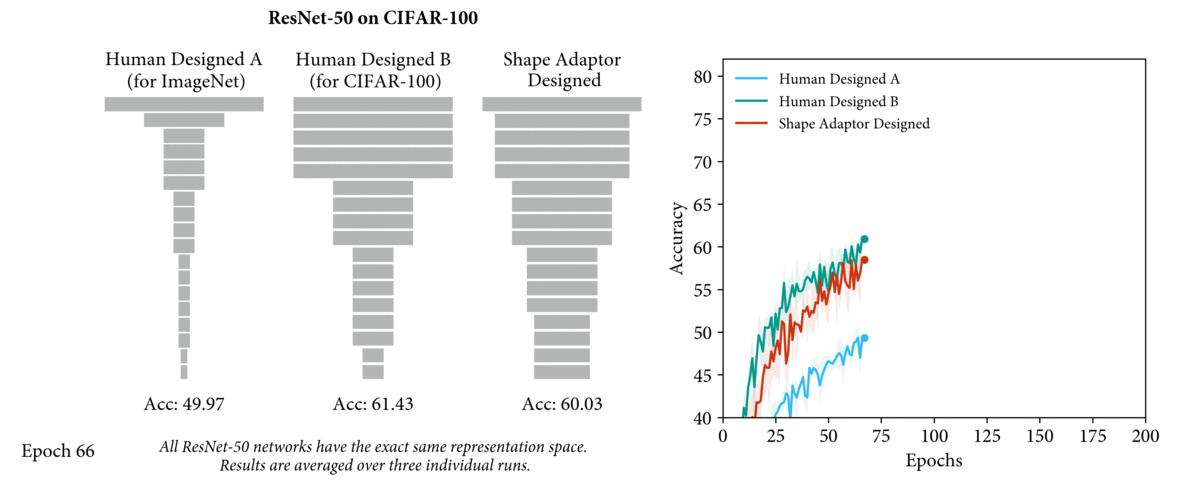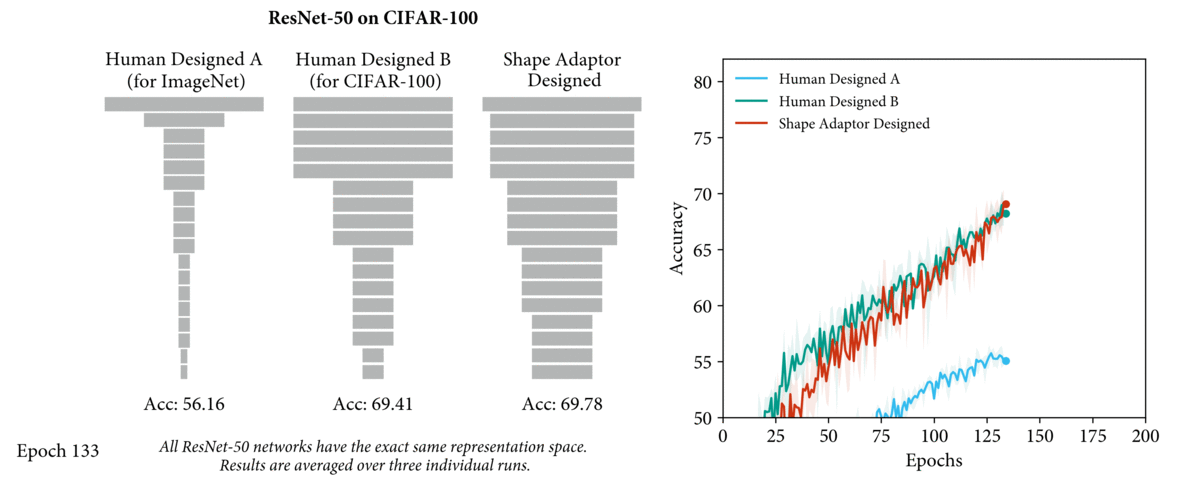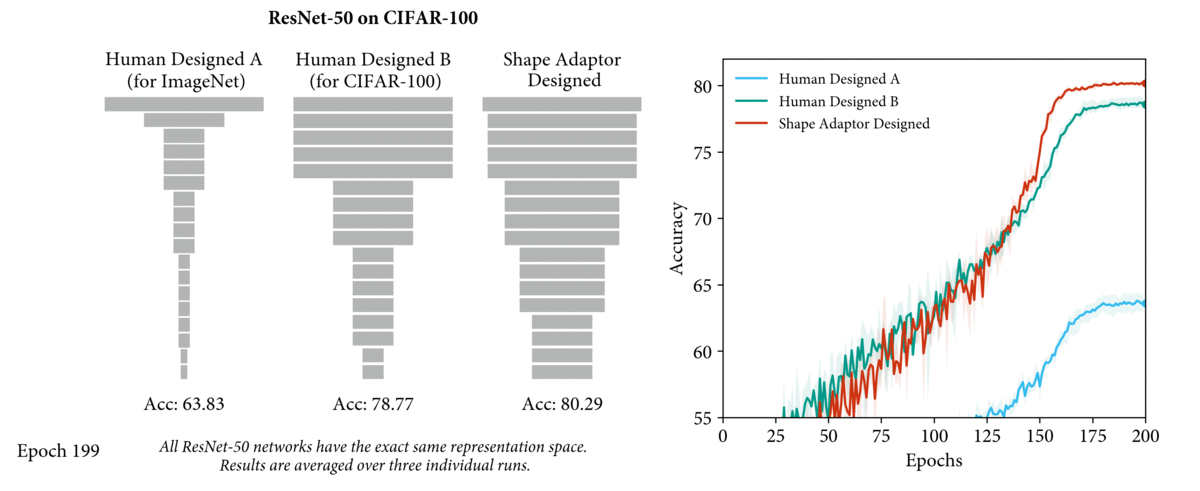
Motivation
- 现有的工作,无论是 human-design network 还是 NAS,resizing layer 放置的位置 和 reshape factor 都是手工设定的(e.g. down-sampling:0.5,up-sampling:2),所以整个 network shape 其实都是手工确定的
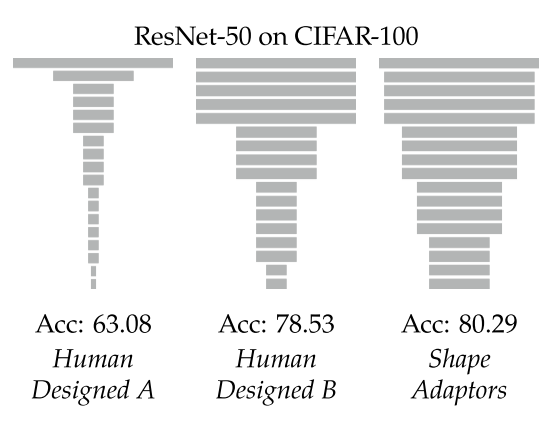
- 而我们认为 network shape 对网络性能有很大的影响(如下图,A是为ImageNet设计的ResNet-50,B是为cifar-100设计的ResNet-50,都应用在cifar100上的性能表现),因此 network shape 还有很大的优化空间。
Contribution
Method
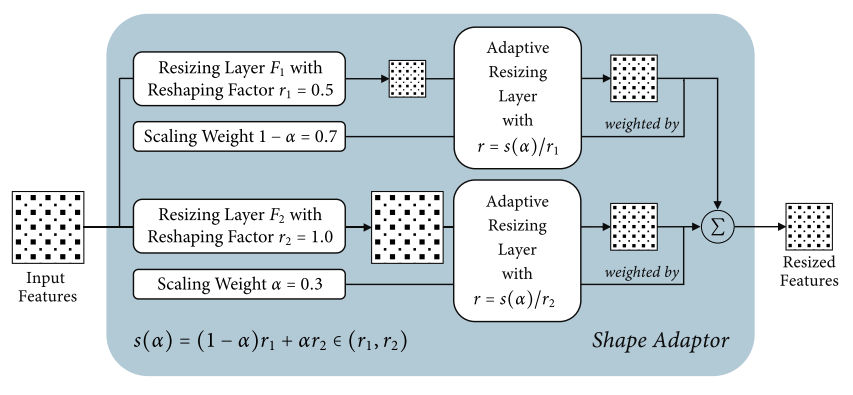

(s(α) = r1 + (r2 − r1)α)
s(a) 的 pytorch代码如下:
def shape_adaptor(input1, input2, alpha, r1, r2):
sigmoid_alpha = torch.sigmoid(alpha)
s_alpha = (r2 - r1) * sigmoid_alpha.item() + r1
input1_rs = F.interpolate(input1, scale_factor=s_alpha/r1, mode='bilinear', align_corners=True)
input2_rs = F.interpolate(input2, size=input1_rs.shape[-2:], mode='bilinear', align_corners=True)
return (1 - sigmoid_alpha) * input1_rs + sigmoid_alpha * input2_rs
Experiments
Setup
- DataSet:
- small:CIFAR10/100、SVHN
- fine-grained:FGVC-Aircraft(Aircraft),CUBS-200-2011(Bird),Stanford Cars (Cars)
- ImageNet
- Train:
- Epochs:200 for small / fine-grained,150 for ImageNet
- Batch Size:128 for small,8 for fine-grained,256 for ImageNet
- Optimizer:SGD
- Momentum:0.9
- Learning Rate:0.1,cosine
- Weight Decay:5e-4 / 4e-5,cosine
- GPU:/
Image Classification
不同网络结构,插入shape adaptor 后在数据集上的性能变化:
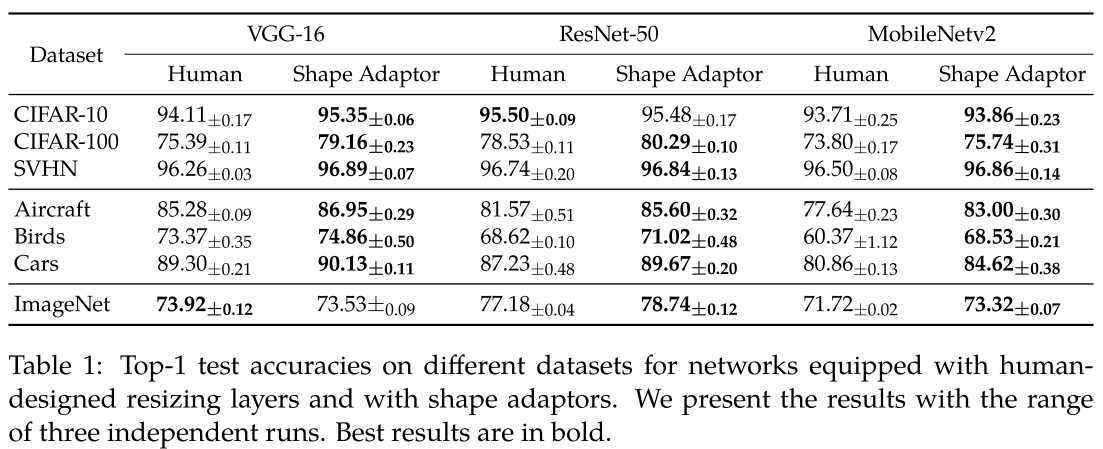
没有提供搜索到结构的 FLOPs,性能提升伴随 FLOPs 的增大。
Ablation Study
Number of Shape Adaptors
插入的 shape adaptor 数量对性能的影响:
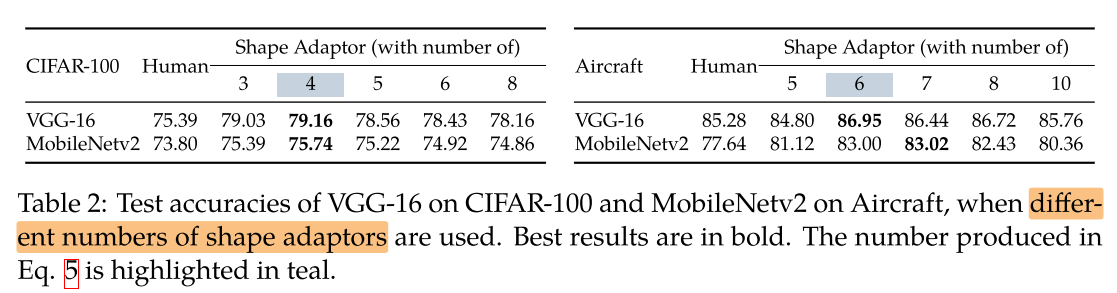
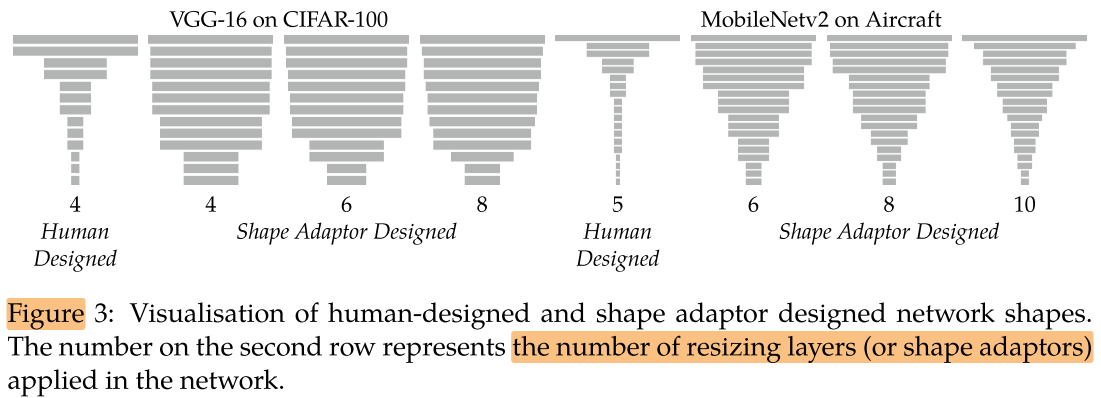
我们发现网络中插入不同数量的 shape adaptor,最后收敛的网络形状几乎一致。
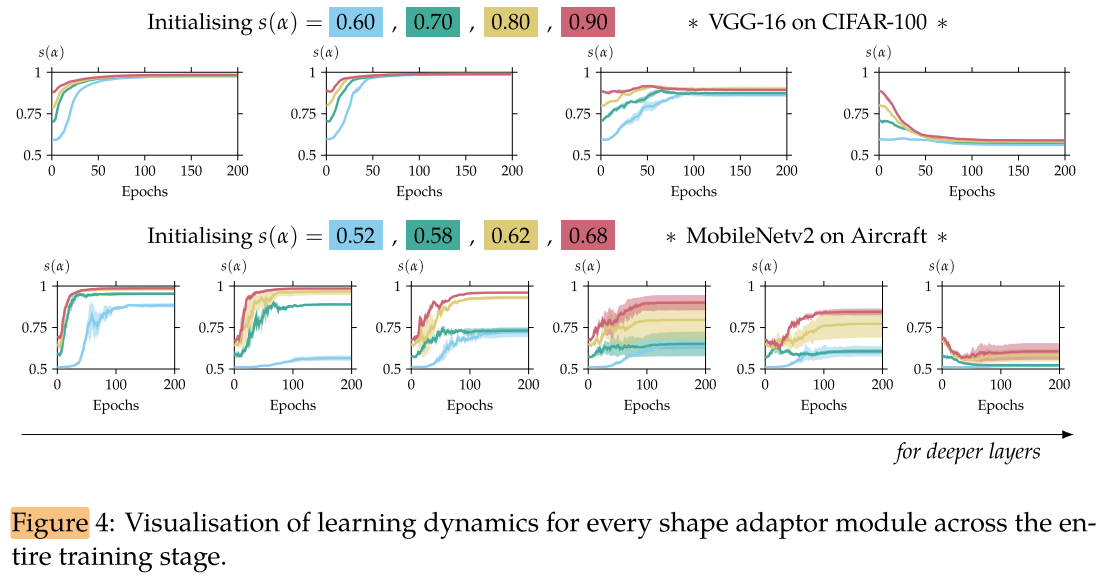
Initialisations in Shape Adaptors
不同层的 alpha initialization ( 初始网络是宽还是瘦) 对网络性能的影响:
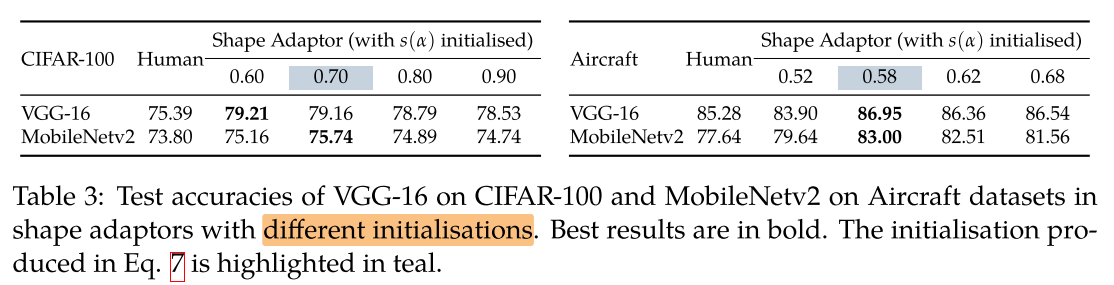
对于小分辨率数据集(如CIFAR-100)初始化网络宽度为多少并不影响最后的收敛结果,同一个位置的 shape adaptor 最后都会收敛到同一个缩放率,且比较浅的 layer 的 resizing factor (α) 越大(α→1),越深的 layer resizing factor (α) 越小(α→0),即浅层不缩小,深层再进行缩小;
对于大数据集(如Aircraft)并不能收敛到同一个缩放率,但收敛的方向是一致的:浅层不缩小,深层再进行缩小。
Shape Adaptor vs. Random Search
在 CIFAR-100 上跑了 200 个基于随机生成的缩放形状的 VGG-16 网络。最后我们得到结果如下图:
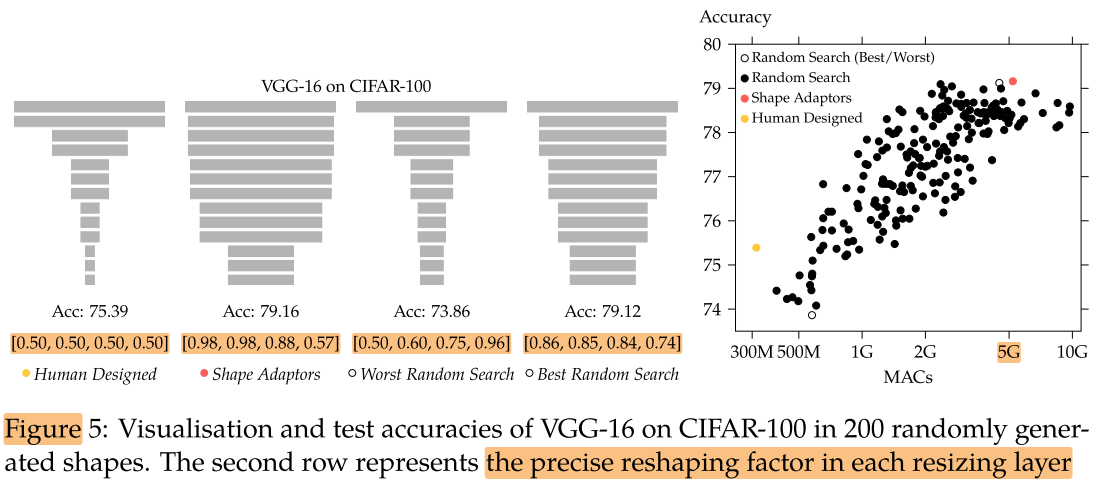
&& shape adaptor 找到的最优结构,虽然性能更好,但也带来了更多的计算量,cifar100 (32×32) 用到5G FLOPs?
但计算量也不是越大越好的,计算量提升的边缘在5G FLOPs左右,计算量再高性能也不再提升,作者认为5G FLOPs 可能是全局最优解(即再往VGG16中插入/修改 resizing layer 也无法提高性能了)
&& 应该在相同MACs下比较acc 或 在相同acc下比较MACs
network 会随着深度增加逐渐变小(注意,传统的网络的 resizing layer 的 位置 和 逐渐降采样的结果是通过大量试错得到的, 而 Shape Adaptor 是自动学习到 feature map 需要随着深度增加逐渐降采样)
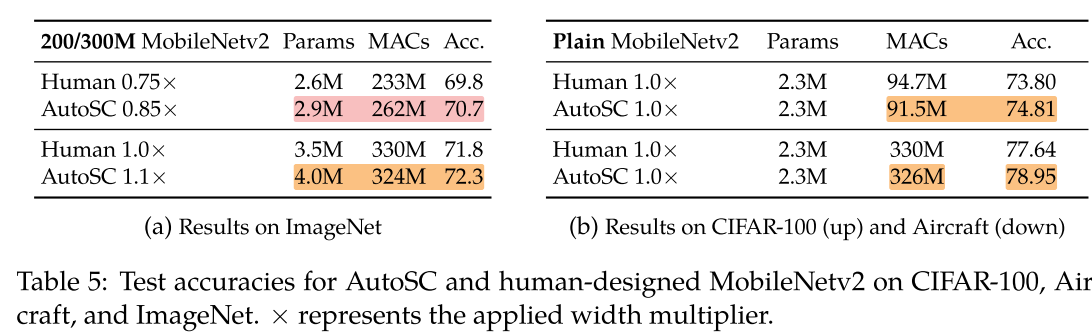
Automated Shape Compression
Shape Adaptor 设计网络最大的局限性是:似乎我们要得到更好的结果,则依赖于一个更大的计算量。
我们在 不大于原始网络定义的搜索空间(memory bounded)的 条件下(把 shape adaptor 插入网络层的同时并不删减原有的 resizing layer),使用Shape Adaptor寻找最优的 network shape(类似网络压缩,但实际上并没有删除卷积核,只是插入/修改网络中的 resizing layer),我们发现在不增加网络计算量的同时, shape adaptor 可以提升少量的网络性能:
Conclusion
Summary
- 最大的贡献在于自动化了网络设计中 “resizing layer” 部分的设计(如自动确定 resizing layer 插入的位置,缩放的系数),可以 drop-in 到其他网络结构设计(包括手动设计 和 自动搜索 NAS)的工作中,提高网络性能。
- 本文只通过修改/插入 resizing layer 来搜索最佳的 network shape ,在不进行 filter 剪枝的情况下要减少FLOPs 性能提升不明显,能否扩展到搜索每一层的卷积核个数?
ToRead
improving spatial robustness with a learnable combination between max and average pooling
- Dingjun Yu, Hanli Wang, Peiqiu Chen, and Zhihua Wei. Mixed pooling for convolutional neural networks. In International conference on rough sets and knowledge technology, pages 364–375. Springer, 2014.
- Chen-Yu Lee, Patrick W Gallagher, and Zhuowen Tu. Generalizing pooling functions in convolutional neural networks: Mixed, gated, and tree. In Artificial intelligence and statistics, pages 464–472, 2016.
with anti-aliased low-pass filters
- Richard Zhang. Making convolutional networks shift-invariant again. In International Conference on Machine Learning, pages 7324–7334, 2019.
Other works impose regularisation and adjustable inference by stochastically inserting pooling layers
- Matthew Zeiler and Robert Fergus. Stochastic pooling for regularization of deep convolutional neural networks. In Proceedings ofthe International Conference on Learning Representation, 2013.
- Jason Kuen, Xiangfei Kong, Zhe Lin, Gang Wang, Jianxiong Yin, Simon See, and YapPeng Tan. Stochastic downsampling for cost-adjustable inference and improved regularization in convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7929–7938, 2018.