无论在室内、野外、空中还是水下,SLAM是机器人进入未知环境遇到的第一个问题。本期给大家介绍SLAM的基础知识:传感器与视觉SLAM框架
近来年,智能机器人技术在世界范围内得到了大力发展。人们致力于把机器人用于实际场景:从室内的移动机器人,到野外的自动驾驶汽车、空中的无人机、水下环境的探测机器人等等,均得到了广泛的关注。
在大多数场合中,我们研究机器人会碰到一个基础性的困难,那就是定位和建图,也就是所谓的SLAM技术。没有准确的定位与地图,扫地机就无法在房间自主地移动,只能随机乱碰;家用机器人就无法按照指令准确到达某个房间。此外,在虚拟现实(Virtual Reality)和增强现实技术(Argument Reality)中,没有SLAM提供的定位,用户就无法在场景中漫游。在这几个应用领域中,人们需要SLAM向应用层提供空间定位的信息,并利用SLAM的地图完成地图的构建或场景的生成。
一、传感器
当我们谈论SLAM时,最先问到的就是传感器。SLAM的实现方式与实现难度和传感器的形式和安装方式密切相关。传感器分为激光和视觉两大类,视觉下面又分三小方向。如此庞大的传感器家族,下面将带你认识每个成员的特性。
1、传感器之激光雷达程序代写接单群733065427

激光雷达是最古老,研究也最多的SLAM传感器。它们提供机器人本体与周围环境障碍物间的距离信息。常见的激光雷达,例如SICK、Velodyne还有我们国产的rplidar等,都可以拿来做SLAM。激光雷达能以很高精度测出机器人周围障碍点的角度和距离,从而很方便地实现SLAM、避障等功能。
主流的2D激光传感器扫描一个平面内的障碍物,适用于平面运动的机器人(如扫地机等)
欢迎光临程序代写小店https://item.taobao.com/item.htm?spm=a230r.1.14.59.255028c3ALNkZ0&id=586797758241&ns=1&abbucket=15#detail
可直接联系客服QQ交代需求:953586085
进行定位,并建立2D的栅格地图。这种地图在机器人导航中很实用,因为多数机器人还不能在空中飞行或走上台阶,仍限于地面。在SLAM研究史上,早期SLAM研究几乎全使用激光传感器进行建图,且多数使用滤波器方法,例如卡尔曼滤波器与粒子滤波器等。
激光的优点是精度很高,速度快,计算量也不大,容易做成实时SLAM。缺点是价格昂贵,一台激光动辄上万元,会大幅提高一个机器人的成本。因此激光的研究主要集中于如何降低传感器的成本上。对应于激光的EKF-SLAM理论方面,因为研究较早,现在已经非常成熟。与此同时,人们也对EKF-SLAM的缺点也有较清楚的认识,例如不易表示回环、线性化误差严重、必须维护路标点的协方差矩阵,导致一定的空间与时间的开销,等等。
2、传感器之视觉SLAM
视觉SLAM是21世纪SLAM研究热点之一,一方面是因为视觉十分直观,不免令人觉得:为何人能通过眼睛认路,机器人就不行呢?另一方面,由于CPU、GPU处理速度的增长,使得许多以前被认为无法实时化的视觉算法,得以在10 Hz以上的速度运行。硬件的提高也促进了视觉SLAM的发展。
以传感器而论,视觉SLAM研究主要分为三大类:单目、双目(或多目)、RGBD。其余还有鱼眼、全景等特殊相机,但是在研究和产品中都属于少数。此外,结合惯性测量器件(Inertial Measurement Unit,IMU)的视觉SLAM也是现在研究热点之一。就实现难度而言,我们可以大致将这三类方法排序为:单目视觉>双目视觉>RGBD。

单目相机SLAM简称MonoSLAM,即只用一支摄像头就可以完成SLAM。这样做的好处是传感器特别的简单、成本特别的低,所以单目SLAM非常受研究者关注。相比别的视觉传感器,单目有个最大的问题,就是没法确切地得到深度。这是一把双刃剑。
一方面,由于绝对深度未知,单目SLAM没法得到机器人运动轨迹以及地图的真实大小。直观地说,如果把轨迹和房间同时放大两倍,单目看到的像是一样的。因此,单目SLAM只能估计一个相对深度,在相似变换空间Sim(3)中求解,而非传统的欧氏空间SE(3)。如果我们必须要在SE(3)中求解,则需要用一些外部的手段,例如GPS、IMU等传感器,确定轨迹与地图的尺度(Scale)。
另一方面,单目相机无法依靠一张图像获得图像中物体离自己的相对距离。为了估计这个相对深度,单目SLAM要靠运动中的三角测量,来求解相机运动并估计像素的空间位置。即是说,它的轨迹和地图,只有在相机运动之后才能收敛,如果相机不进行运动时,就无法得知像素的位置。同时,相机运动还不能是纯粹的旋转,这就给单目SLAM的应用带来了一些麻烦,好在日常使用SLAM时,相机都会发生旋转和平移。不过,无法确定深度同时也有一个好处:它使得单目SLAM不受环境大小的影响,因此既可以用于室内,又可以用于室外。

相比于单目,双目相机通过多个相机之间的基线,估计空间点的位置。与单目不同的是,立体视觉既可以在运动时估计深度,亦可在静止时估计,消除了单目视觉的许多麻烦。不过,双目或多目相机配置与标定均较为复杂,其深度量程也随双目的基线与分辨率限制。通过双目图像计算像素距离,是一件非常消耗计算量的事情,现在多用FPGA来完成。

RGBD相机是2010年左右开始兴起的一种相机,它最大的特点是可以通过红外结构光或Time-of-Flight原理,直接测出图像中各像素离相机的距离。因此,它比传统相机能够提供更丰富的信息,也不必像单目或双目那样费时费力地计算深度。目前常用的RGBD相机包括Kinect/Kinect V2、Xtion等。不过,现在多数RGBD相机还存在测量范围窄、噪声大、视野小等诸多问题。出于量程的限制,主要用于室内SLAM。
三、视觉SLAM框架
视觉SLAM几乎都有一个基本的框架。一个SLAM系统分为四个模块(除去传感器数据读取)VO、后端、建图、回环检测。本期我们简要介绍各模块的涵义,之后再详细介绍其使用方法。
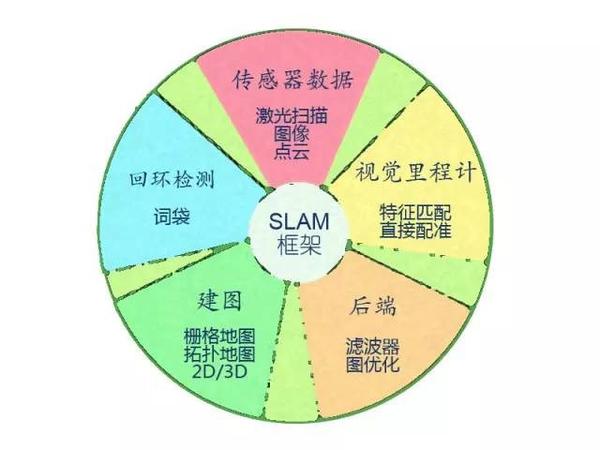
1、SLAM框架之视觉里程计
Visual Odometry,即视觉里程计。它估计两个时刻机器人的相对运动(Ego-motion)。在激光SLAM中,我们可以将当前的观测与全局地图进行匹配,用ICP求解相对运动。而对于相机,它在欧氏空间里运动,我们经常需要估计一个三维空间的变换矩阵——SE3或Sim3(单目情形)。求解这个矩阵是VO的核心问题,而求解的思路,则分为基于特征的思路和不使用特征的直接方法。

基于特征的方法是目前VO的主流方式。对于两幅图像,首先提取图像中的特征,然后根据两幅图的特征匹配,计算相机的变换矩阵。最常用的是点特征,例如Harris角点、SIFT、SURF、ORB。如果使用RGBD相机,利用已知深度的特征点,就可以直接估计相机的运动。给定一组特征点以及它们之间的配对关系,求解相机的姿态,该问题被称为PnP问题(Perspective-N-Point)。PnP可以用非线性优化来求解,得到两个帧之间的位置关系。
不使用特征进行VO的方法称为直接法。它直接把图像中所有像素写进一个位姿估计方程,求出帧间相对运动。例如,在RGBD SLAM中,可以用ICP(Iterative Closest Point,迭代最近邻)求解两个点云之间的变换矩阵。对于单目SLAM,我们可以匹配两个图像间的像素,或者像图像与一个全局的模型相匹配。直接法的典型例子是SVO和LSD-SLAM。它们在单目SLAM中使用直接法,取得了较好的效果。目前看来,直接法比特征VO需要更多的计算量,而且对相机的图像采集速率也有较高的要求。
2、SLAM框架之后端
在VO估计帧间运动之后,理论上就可以得到机器人的轨迹了。然而视觉里程计和普通的里程计一样,存在累积误差的问题(Drift)。直观地说,在t1和t2时刻,估计的转角比真实转角少1度,那么之后的轨迹就全部少掉了这1度。时间一长,建出的房间可能由方形变成了多边形,估计出的轨迹亦会有严重的漂移。所以在SLAM中,还会把帧间相对运动放到一个称之为后端的程序中进行加工处理。
早期的SLAM后端使用滤波器方式。由于那时还未形成前后端的概念,有时人们也称研究滤波器的工作为研究SLAM。SLAM最早的提出者R. Smith等人就把SLAM建构成了一个EKF(Extended Kalman Filter,扩展卡尔曼滤波)问题。他们按照EKF的形式,把SLAM写成了一个运动方程和观测方式,以最小化这两个方程中的噪声项为目的,使用典型的滤波器思路来解决SLAM问题。
当一个帧到达时,我们能(通过码盘或IMU)测出该帧与上一帧的相对运动,但是存在噪声,是为运动方程。同时,通过传感器对路标的观测,我们测出了机器人与路标间的位姿关系,同样也带有噪声,是为观测方程。通过这两者信息,我们可以预测出机器人在当前时刻的位置。同样,根据以往记录的路标点,我们又能计算出一个卡尔曼增益,以补偿噪声的影响。于是,对当前帧和路标的估计,即是这个预测与更新的不断迭代的过程。
21世纪之后,SLAM研究者开始借鉴SfM(Structure from Motion)问题中的方法,把捆集优化(Bundle Adjustment)引入到SLAM中来。优化方法和滤波器方法有根本上的不同。它并不是一个迭代的过程,而是考虑过去所有帧中的信息。通过优化,把误差平均分到每一次观测当中。在SLAM中的Bundle Adjustment常常以图的形式给出,所以研究者亦称之为图优化方法(Graph Optimization)。图优化可以直观地表示优化问题,可利用稀疏代数进行快速的求解,表达回环也十分的方便,因而成为现今视觉SLAM中主流的优化方法。
3、SLAM框架之回环检测
回环检测,又称闭环检测(Loop closure detection),是指机器人识别曾到达场景的能力。如果检测成功,可以显著地减小累积误差。回环检测实质上是一种检测观测数据相似性的算法。对于视觉SLAM,多数系统采用目前较为成熟的词袋模型(Bag-of-Words, BoW)。词袋模型把图像中的视觉特征(SIFT, SURF等)聚类,然后建立词典,进而寻找每个图中含有哪些“单词”(word)。也有研究者使用传统模式识别的方法,把回环检测建构成一个分类问题,训练分类器进行分类。
回环检测的难点在于,错误的检测结果可能使地图变得很糟糕。这些错误分为两类:1.假阳性(False Positive),又称感知偏差(Perceptual Aliasing),指事实上不同的场景被当成了同一个;2.假阴性(False Negative),又称感知变异(Perceptual Variability),指事实上同一个场景被当成了两个。感知偏差会严重地影响地图的结果,通常是希望避免的。一个好的回环检测算法应该能检测出尽量多的真实回环。研究者常常用准确率-召回率曲线来评价一个检测算法的好坏。