上一章节,我们讲解了通过mybatis的懒加载来提高查询效率,那么除了懒加载,还有什么方法能提高查询效率呢?这就是我们本章讲的缓存。
本篇源码下载链接:百度云盘/java实例/java框架—mybatis/MyBatisCache.zip
mybatis 为我们提供了一级缓存和二级缓存,可以通过下图来理解:

①、一级缓存是SqlSession级别的缓存。在操作数据库时需要构造sqlSession对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的。
②、二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
1、一级缓存
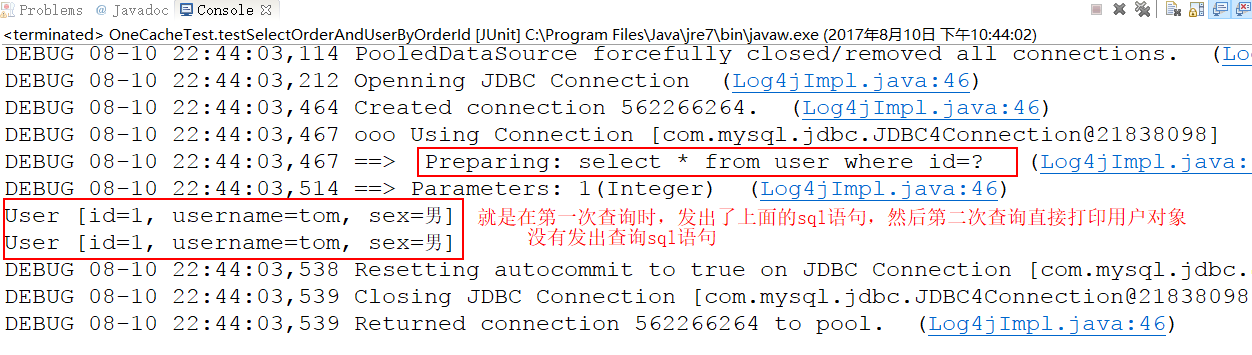
①、我们在一个 sqlSession 中,对 User 表根据id进行两次查询,查看他们发出sql语句的情况。
@Test public void testSelectOrderAndUserByOrderId(){ //根据 sqlSessionFactory 产生 session SqlSession sqlSession = sessionFactory.openSession(); String statement = "one.to.one.mapper.OrdersMapper.selectOrderAndUserByOrderID"; UserMapper userMapper = sqlSession.getMapper(UserMapper.class); //第一次查询,发出sql语句,并将查询的结果放入缓存中 User u1 = userMapper.selectUserByUserId(1); System.out.println(u1); //第二次查询,由于是同一个sqlSession,会在缓存中查找查询结果 //如果有,则直接从缓存中取出来,不和数据库进行交互 User u2 = userMapper.selectUserByUserId(1); System.out.println(u2); sqlSession.close(); }
查看控制台打印情况:
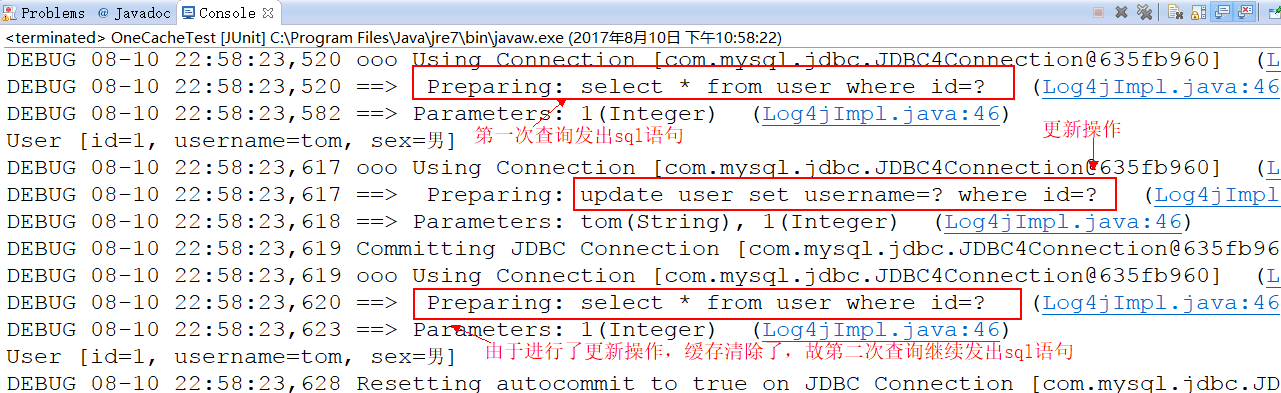
②、 同样是对user表进行两次查询,只不过两次查询之间进行了一次update操作。
@Test public void testSelectOrderAndUserByOrderId(){ //根据 sqlSessionFactory 产生 session SqlSession sqlSession = sessionFactory.openSession(); String statement = "one.to.one.mapper.OrdersMapper.selectOrderAndUserByOrderID"; UserMapper userMapper = sqlSession.getMapper(UserMapper.class); //第一次查询,发出sql语句,并将查询的结果放入缓存中 User u1 = userMapper.selectUserByUserId(1); System.out.println(u1); //第二步进行了一次更新操作,sqlSession.commit() u1.setSex("女"); userMapper.updateUserByUserId(u1); sqlSession.commit(); //第二次查询,由于是同一个sqlSession.commit(),会清空缓存信息 //则此次查询也会发出 sql 语句 User u2 = userMapper.selectUserByUserId(1); System.out.println(u2); sqlSession.close(); }
控制台打印情况:
③、总结
1、第一次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,如果没有,从数据库查询用户信息。得到用户信息,将用户信息存储到一级缓存中。
2、如果中间sqlSession去执行commit操作(执行插入、更新、删除),则会清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
3、第二次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,缓存中有,直接从缓存中获取用户信息

2、二级缓存
二级缓存的原理和一级缓存原理一样,第一次查询,会将数据放入缓存中,然后第二次查询则会直接去缓存中取。但是一级缓存是基于 sqlSession 的,而 二级缓存是基于 mapper文件的namespace的,也就是说多个sqlSession可以共享一个mapper中的二级缓存区域,并且如果两个mapper的namespace相同,即使是两个mapper,那么这两个mapper中执行sql查询到的数据也将存在相同的二级缓存区域中。

那么二级缓存是如何使用的呢?
①、开启二级缓存
和一级缓存默认开启不一样,二级缓存需要我们手动开启
首先在全局配置文件 mybatis-configuration.xml 文件中加入如下代码:
<!--开启二级缓存 --> <settings> <setting name="cacheEnabled" value="true"/> </settings>
其次在 UserMapper.xml 文件中开启缓存
<!-- 开启二级缓存 --> <cache></cache>
我们可以看到 mapper.xml 文件中就这么一个空标签<cache/>,其实这里可以配置<cache type="org.apache.ibatis.cache.impl.PerpetualCache"/>,PerpetualCache这个类是mybatis默认实现缓存功能的类。我们不写type就使用mybatis默认的缓存,也可以去实现 Cache 接口来自定义缓存。

我们可以看到 二级缓存 底层还是 HashMap 架构。
②、po 类实现 Serializable 序列化接口

开启了二级缓存后,还需要将要缓存的pojo实现Serializable接口,为了将缓存数据取出执行反序列化操作,因为二级缓存数据存储介质多种多样,不一定只存在内存中,有可能存在硬盘中,如果我们要再取这个缓存的话,就需要反序列化了。所以mybatis中的pojo都去实现Serializable接口。
③、测试
一、测试二级缓存和sqlSession 无关
@Test public void testTwoCache(){ //根据 sqlSessionFactory 产生 session SqlSession sqlSession1 = sessionFactory.openSession(); SqlSession sqlSession2 = sessionFactory.openSession(); String statement = "com.ys.twocache.UserMapper.selectUserByUserId"; UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class); UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class); //第一次查询,发出sql语句,并将查询的结果放入缓存中 User u1 = userMapper1.selectUserByUserId(1); System.out.println(u1); sqlSession1.close();//第一次查询完后关闭sqlSession //第二次查询,即使sqlSession1已经关闭了,这次查询依然不发出sql语句 User u2 = userMapper2.selectUserByUserId(1); System.out.println(u2); sqlSession2.close(); }
可以看出上面两个不同的sqlSession,第一个关闭了,第二次查询依然不发出sql查询语句。
二、测试执行 commit() 操作,二级缓存数据清空
@Test public void testTwoCache(){ //根据 sqlSessionFactory 产生 session SqlSession sqlSession1 = sessionFactory.openSession(); SqlSession sqlSession2 = sessionFactory.openSession(); SqlSession sqlSession3 = sessionFactory.openSession(); String statement = "com.ys.twocache.UserMapper.selectUserByUserId"; UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class); UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class); UserMapper userMapper3 = sqlSession2.getMapper(UserMapper.class); //第一次查询,发出sql语句,并将查询的结果放入缓存中 User u1 = userMapper1.selectUserByUserId(1); System.out.println(u1); sqlSession1.close();//第一次查询完后关闭sqlSession //执行更新操作,commit() u1.setUsername("aaa"); userMapper3.updateUserByUserId(u1); sqlSession3.commit(); //第二次查询,由于上次更新操作,缓存数据已经清空(防止数据脏读),这里必须再次发出sql语句 User u2 = userMapper2.selectUserByUserId(1); System.out.println(u2); sqlSession2.close(); }
查看控制台情况:

④、useCache和flushCache
mybatis中还可以配置userCache和flushCache等配置项,userCache是用来设置是否禁用二级缓存的,在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存。
<select id="selectUserByUserId" useCache="false" resultType="com.ys.twocache.User" parameterType="int"> select * from user where id=#{id} </select>
这种情况是针对每次查询都需要最新的数据sql,要设置成useCache=false,禁用二级缓存,直接从数据库中获取。
在mapper的同一个namespace中,如果有其它insert、update、delete操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读。
设置statement配置中的flushCache=”true” 属性,默认情况下为true,即刷新缓存,如果改成false则不会刷新。使用缓存时如果手动修改数据库表中的查询数据会出现脏读。
<select id="selectUserByUserId" flushCache="true" useCache="false" resultType="com.ys.twocache.User" parameterType="int"> select * from user where id=#{id} </select>
一般下执行完commit操作都需要刷新缓存,flushCache=true表示刷新缓存,这样可以避免数据库脏读。所以我们不用设置,默认即可。
3、二级缓存整合ehcache
上面我们介绍了mybatis自带的二级缓存,但是这个缓存是单服务器工作,无法实现分布式缓存。那么什么是分布式缓存呢?假设现在有两个服务器1和2,用户访问的时候访问了1服务器,查询后的缓存就会放在1服务器上,假设现在有个用户访问的是2服务器,那么他在2服务器上就无法获取刚刚那个缓存,如下图所示:

为了解决这个问题,就得找一个分布式的缓存,专门用来存储缓存数据的,这样不同的服务器要缓存数据都往它那里存,取缓存数据也从它那里取,如下图所示:

如上图所示,在几个不同的服务器之间,我们使用第三方缓存框架,将缓存都放在这个第三方框架中,然后无论有多少台服务器,我们都能从缓存中获取数据。
这里我们介绍mybatis与第三方框架ehcache的整合。
上文一开始提到过,mybatis提供了一个cache接口,如果要实现自己的缓存逻辑,实现cache接口开发即可。mybatis本身默认实现了一个,但是这个缓存的实现无法实现分布式缓存,所以我们要自己来实现。ehcache分布式缓存就可以,mybatis提供了一个针对cache接口的ehcache实现类,这个类在mybatis和ehcache的整合包中。
①、导入 mybatis-ehcache 整合包(最上面的源代码中包含有)
②、在全局配置文件 mybatis-configuration.xml 开启缓存
<!--开启二级缓存 --> <settings> <setting name="cacheEnabled" value="true"/> </settings>
③、在 xxxMapper.xml 文件中整合 ehcache 缓存
将如下的类的全类名写入<cache type="" ></cache>的type属性中
<!-- 开启本mapper的namespace下的二级缓存 type:指定cache接口的实现类的类型,不写type属性,mybatis默认使用PerpetualCache 要和ehcache整合,需要配置type为ehcache实现cache接口的类型 --> <cache type="org.mybatis.caches.ehcache.EhcacheCache"></cache>
④、配置缓存参数
在 classpath 目录下新建一个 ehcache.xml 文件,并增加如下配置:
<?xml version="1.0" encoding="UTF-8"?> <ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="../config/ehcache.xsd"> <diskStore path="F:developehcache"/> <defaultCache maxElementsInMemory="10000" eternal="false" timeToIdleSeconds="120" timeToLiveSeconds="120" maxElementsOnDisk="10000000" diskExpiryThreadIntervalSeconds="120" memoryStoreEvictionPolicy="LRU"> <persistence strategy="localTempSwap"/> </defaultCache> </ehcache>
diskStore:指定数据在磁盘中的存储位置。
defaultCache:当借助CacheManager.add("demoCache")创建Cache时,EhCache便会采用<defalutCache/>指定的的管理策略
以下属性是必须的:
maxElementsInMemory - 在内存中缓存的element的最大数目
maxElementsOnDisk - 在磁盘上缓存的element的最大数目,若是0表示无穷大
eternal - 设定缓存的elements是否永远不过期。如果为true,则缓存的数据始终有效,如果为false那么还要根据timeToIdleSeconds,timeToLiveSeconds判断
overflowToDisk - 设定当内存缓存溢出的时候是否将过期的element缓存到磁盘上
以下属性是可选的:
timeToIdleSeconds - 当缓存在EhCache中的数据前后两次访问的时间超过timeToIdleSeconds的属性取值时,这些数据便会删除,默认值是0,也就是可闲置时间无穷大
timeToLiveSeconds - 缓存element的有效生命期,默认是0.,也就是element存活时间无穷大
diskSpoolBufferSizeMB 这个参数设置DiskStore(磁盘缓存)的缓存区大小.默认是30MB.每个Cache都应该有自己的一个缓冲区.
diskPersistent - 在VM重启的时候是否启用磁盘保存EhCache中的数据,默认是false。
diskExpiryThreadIntervalSeconds - 磁盘缓存的清理线程运行间隔,默认是120秒。每个120s,相应的线程会进行一次EhCache中数据的清理工作
memoryStoreEvictionPolicy - 当内存缓存达到最大,有新的element加入的时候, 移除缓存中element的策略。默认是LRU(最近最少使用),可选的有LFU(最不常使用)和FIFO(先进先出)
4、二级缓存的应用场景
对于访问多的查询请求且用户对查询结果实时性要求不高,此时可采用mybatis二级缓存技术降低数据库访问量,提高访问速度,业务场景比如:耗时较高的统计分析sql、电话账单查询sql等。实现方法如下:通过设置刷新间隔时间,由mybatis每隔一段时间自动清空缓存,根据数据变化频率设置缓存刷新间隔flushInterval,比如设置为30分钟、60分钟、24小时等,根据需求而定。
mybatis二级缓存对细粒度的数据级别的缓存实现不好,比如如下需求:对商品信息进行缓存,由于商品信息查询访问量大,但是要求用户每次都能查询最新的商品信息,此时如果使用mybatis的二级缓存就无法实现当一个商品变化时只刷新该商品的缓存信息而不刷新其它商品的信息,因为mybaits的二级缓存区域以mapper为单位划分的,当一个商品信息变化会将所有商品信息的缓存数据全部清空。解决此类问题可能需要在业务层根据需求对数据有针对性缓存。