这篇文章讲得还不错:
https://blog.csdn.net/weixin_42446330/article/details/86710838
《Encoder-Decoder框架、Attention、Transformer、ELMO、GPT、Bert学习总结》
里面有一些点可以注意:
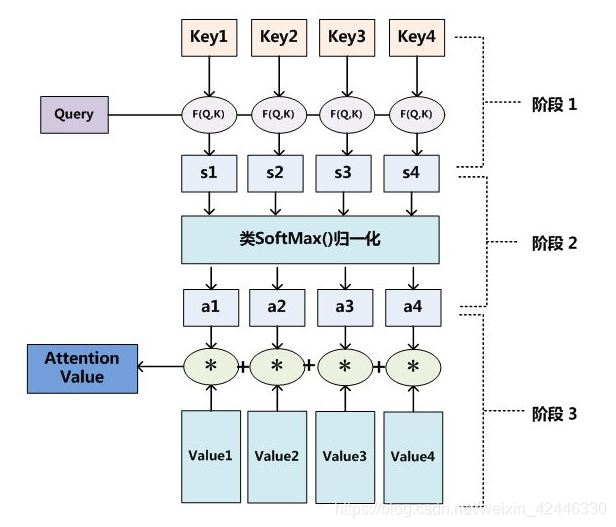

- 引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:


然后为了防止其结果过大,会除以一个尺度标度 ,其中
为一个query和key向量的维度。
关于这个scale,可以参考这篇文章:
https://blog.csdn.net/ltochange/article/details/119957892
简单的说是为了让attention得到的权值更加均匀一点。
在数量级较大时,softmax将几乎全部的概率分布都分配给了最大值对应的标签。
如果本身就想获得差距较大的attention值,可以不用scaled。例如在这里:https://blog.csdn.net/ltochange/article/details/119816832
论文提出了两点改进:(1)提出带有方向与相对位置信息的atteniton机制;(2)丢弃了原有Transformer self-attention的scale factor,scale factor的引入是为了得到分布相对均匀的attention权重,但是在NER中,并不需要关注所有词。
ELMO
ELMO采用了典型的两阶段过程:
- 利用语言模型进行预训练;
- 在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。
优点:
- 引入上下文动态调整单词的embedding后解决了多义词问题;
- 适用范围是非常广的,普适性强
缺点:
- LSTM抽取特征能力弱于Transformer
- 拼接方式双向融合特征融合能力偏弱
GPT模型
GPT是“Generative Pre-Training”的简称,从名字看其含义是指的生成式的预训练。GPT也采用两阶段过程:
- 利用语言模型进行预训练;
- 通过Fine-tuning的模式解决下游任务;
与ELMO区别:
- 特征抽取器不是用的RNN,而是用的Transformer
- 采用的是单向的语言模型
优点:
- 引入Transformer任务性能提升非常明显
缺点:
- 单项语言模型只采用Context-before这个单词的上文来进行预测,而抛开了下文,白白丢掉了很多信息
Bert模型:
Bert采用和GPT完全相同的两阶段模型:
- 首先是语言模型预训练;
- 其次是使用Fine-Tuning模式解决下游任务。
与GPT区别:
最主要不同在于在预训练阶段采用了类似ELMO的双向语言模型
另外一点是语言模型的数据规模要比GPT大
优点:
在各种类型的NLP任务中达到目前最好的效果,某些任务性能有极大的提升
Bert最关键两点:
一点是特征抽取器采用Transformer;
第二点是预训练的时候采用双向语言模型。
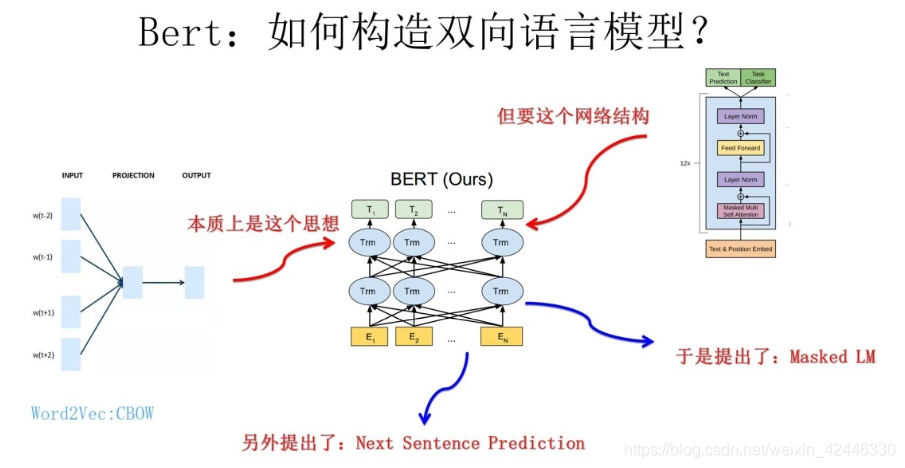
创新点:
- Masked 语言模型:
-
①随机选择语料中15%的单词,用[Mask]掩码代替原始单词,
②然后要求模型去正确预测被抠掉的单词。
③15%的被上天选中要执行[mask]替身这项光荣任务的单词中,只有80%真正被替换成[mask]标记
④10%被狸猫换太子随机替换成另外一个单词,10%情况这个单词还待在原地不做改动。 - Next Sentence Prediction:
- ①一种是选择语料中真正顺序相连的两个句子;
②另外一种是第二个句子从语料库中抛色子,随机选择一个拼到第一个句子后面。
这篇文章里面提到的几篇参考文章:
参考:深度学习:transformer模型、放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较