参考这篇文章:
https://www.cnblogs.com/dogecheng/p/11615750.html
我们期望每一个 word token 都有一个 embedding。每个 word token 的 embedding 依赖于它的上下文。这种方法叫做 Contextualized Word Embedding。
BERT 是 Transformer 的 Encoder,GPT则是 Transformer 的 Decoder。GPT 输入一些词汇,预测接下来的词汇。其计算过程如下图所示。
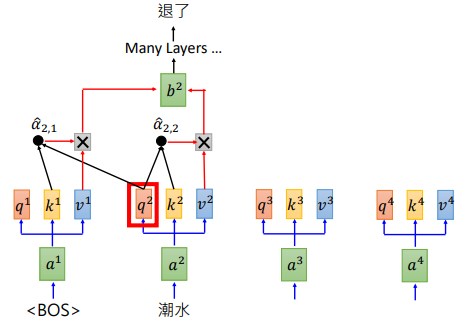
先记到这里吧,其他好像也没有特别需要记录的。