参考文章:
-
https://www.linuxidc.com/Linux/2016-02/128149.htm
-
https://blog.csdn.net/circyo/article/details/46724335
前言
本教程是使用编译hadoop的方式进行安装,原因是下载的hadoop是32位,安装完后会有问题。
编译方法:http://www.cnblogs.com/champaign/p/8952533.html
1、集群部署介绍
1.1 Hadoop简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统HDFS(Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任 务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
从上面的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。HDFS在集群上实现分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
1.2 环境说明
准备三台服务器:
| IP | 用途 | 操作系统 | 主机名 |
| 172.18.29.151 | 主 | Centos 6.8 | master.hadoopo |
| 172.18.29.152 | 从1 | Centos 6.8 | slave1.hadoop |
| 172.18.29.153 | 从2 | Centos 6.8 | slave2.hadoop |
在三台服务器中创建相同账号:hadoop 密码三台也一要致,最好不要与账号相同
1.3 环境配置
修改三台服务器的hosts文件:
vi /etc/hosts 新增以下内容 172.18.29.151 master.hadoop 172.18.29.152 slave1.hadoop 172.18.29.153 slave2.hadoop
可以使用 ping 命令测试三台机器的连通性
1.4 所需软件
(1)JDK软件
下载地址:http://www.Oracle.com/technetwork/java/javase/index.html
(2)Hadoop软件
使用前面编译生成的安装包
2、SSH无密码验证配置
如果你的Linux没有安装SSH,请首先安装SSH
yum -y install openssh-server
2.1 SSH基本原理和用法
1)SSH基本原理
SSH之所以能够保证安全,原因在于它采用了公钥加密。过程如下:
(1)远程主机收到用户的登录请求,把自己的公钥发给用户。
(2)用户使用这个公钥,将登录密码加密后,发送回来。
(3)远程主机用自己的私钥,解密登录密码,如果密码正确,就同意用户登录。
2)SSH基本用法
假如用户名为java,登录远程主机名为linux,如下命令即可:
$ ssh java@linux
SSH的默认端口是22,也就是说,你的登录请求会送进远程主机的22端口。使用p参数,可以修改这个端口,例如修改为88端口,命令如下:
$ ssh -p 88 java@linux
注意:如果出现错误提示:ssh: Could not resolve hostname linux: Name or service not known,则是因为linux主机未添加进本主机的Name Service中,故不能识别,需要在/etc/hosts里添加进该主机及对应的IP即可:
linux 192.168.1.107
2.2配置Master无密码登录所有Salve
1)SSH无密码原理
Master(NameNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器Salve(DataNode | Tasktracker)上时,需要在Master上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的Slave上。当Master通过SSH连接Salve时,Salve就会生成一个随机数并用Master的公钥对随机数进行加密,并发送给Master。Master收到加密数之后再用私钥解密,并将解密数回传给Slave,Slave确认解密数无误之后就允许Master进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。
2)Master机器上设置无密码登录
a. Master节点利用ssh-keygen命令生成一个无密码密钥对。
首先切换到hadoop用户,在Master节点上执行以下命令:
[root@SVR-29-151 ~]# su hadoop [hadoop@SVR-29-151 root]$ ssh-keygen -t rsa
运行后询问其保存路径时直接回车采用默认路径。生成的密钥对:id_rsa(私钥)和id_rsa.pub(公钥),默认存储在"/用户名/.ssh"目录下。
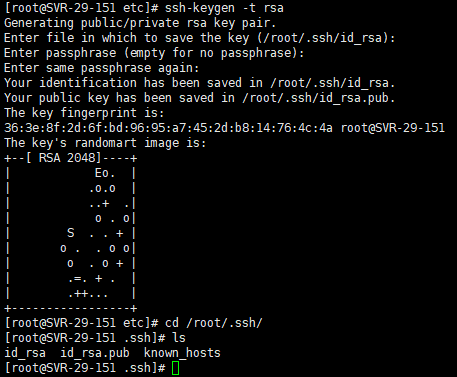
b. 接着在Master节点上做如下配置,把id_rsa.pub追加到授权的key里面去。
[hadoop@SVR-29-151 root]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
查看下authorized_keys的权限,如果权限不对则利用如下命令设置该文件的权限:
[hadoop@SVR-29-151 root]$ cd ~/.ssh [hadoop@SVR-29-151 .ssh]$ ll
[hadoop@SVR-29-151 .ssh]$ chmod 600 authorized_keys
c. 用root用户登录修改SSH配置文件"/etc/ssh/sshd_config"的下列内容。
检查下面几行前面”#”注释是否取消掉:
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile %h/.ssh/authorized_keys # 公钥文件路径
设置完之后记得重启SSH服务,才能使刚才设置有效。
[root@SVR-29-151 ~]# service sshd restart
d. 用root用户登录修改SSH配置文件"/etc/ssh/ssh_config"的下列内容(由于我的系统环境中ssh 默认端口必须使用 62222,如没有修改默认端口此步骤可以略过)。
将port选项的值修改为下图
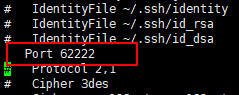
同样设置完之后记得重启SSH服务,才能使刚才设置有效。
[root@SVR-29-151 ~]# service sshd restart
e.切换到hadoop用户下,使用ssh-copy-id命令将公钥传送到远程主机上(这里以Slave1.Hadoop为例)。
[root@SVR-29-151 ~]# su hadoop [hadoop@SVR-29-151 root]$ ssh-copy-id hadoop@slave1.hadoop

然后测试是否无密码登录其它机器成功
[hadoop@SVR-29-151 root]$ ssh slave1.hadoop

如图所示证明成功。
到此为止,我们经过5步已经实现了从"Master.Hadoop"到"Slave1.Hadoop"SSH无密码登录,下面就是重复上面的 步骤e 把 Slave2.Hadoop服务器进行配置。这样,我们就完成了"配置Master无密码登录所有的Slave服务器"。
3、Java环境安装
所有的机器上都要安装JDK,现在就先在Master服务器安装,然后其他服务器按照步骤重复进行即可。安装JDK以及配置环境变量,需要以"root"的身份进行。
3.1 安装JDK
首先用root身份登录"Master.Hadoop"后将jdk复制到"/usr/local/src"文件夹中,然后解压即可。查看"/usr/local/src"下面会发现多了一个名为"jdk-7u25-linux-i586"文件夹,说明我们的JDK安装结束,进入下一个"配置环境变量"环节。
然后将jdk文件夹移动到”/usr/local/“目录下。
3.2 配置环境变量
(1)编辑"/etc/profile"文件
编辑"/etc/profile"文件,在后面添加Java的"JAVA_HOME"、"CLASSPATH"以及"PATH"内容如下:
# set java environment export JAVA_HOME=/usr/local/jdk1.8.0_171/ export JRE_HOME=/usr/local/jdk1.8.0_171/jre export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
(2)使配置生效
保存并退出,执行下面命令使其配置立即生效。
source /etc/profile 或 . /etc/profile
3.3 验证安装成功
配置完毕并生效后,用下面命令判断是否成功。
java -version

从上图中得知,我们确定JDK已经安装成功
3.4 安装剩余机器
在其它服务器重复以上步骤
4、Hadoop集群安装(本例中的版本为:3.0.1)
4.1 安装hadoop
(1) 安装软件
首先用root用户登录"Master.Hadoop"机器,将下载的"hadoop-3.0.1.tar.gz"复制到/usr/local/src目录下。然后进入/usr/local/src目录下,用下面命令把文件解压,并将其重命名为"hadoop",把该文件夹的读权限分配给普通用户hadoop
cd /usr/local/src tar –zxvf hadoop-3.0.1.tar.gz mv hadoop-3.0.1 ../hadoop cd .. chown –R hadoop:hadoop hadoop
(2) 创建tmp文件夹.
最后在"/usr/local/hadoop"下面创建tmp文件夹.
(3) 配置环境变量
并把Hadoop的安装路径添加到"/etc/profile"中,修改"/etc/profile"文件,将以下语句添加到末尾,并使其生效(. /etc/profile):
# set hadoop path export HADOOP_INSTALL=/usr/local/hadoop
export PATH=${HADOOP_INSTALL}/bin:${HADOOP_INSTALL}/sbin:${PATH}
export HADOOP_MAPRED_HOME=${HADOOP_INSTALL}
export HADOOP_COMMON_HOME=${HADOOP_INSTALL}
export HADOOP_HDFS_HOME=${HADOOP_INSTALL}
export YARN_HOME=${HADOOP_INSTALLL}
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_INSTALL}/lib/natvie
export HADOOP_OPTS="-Djava.library.path=${HADOOP_INSTALL}/lib:${HADOOP_INSTALL}/lib/native"
(4)重启”/etc/profile”
source /etc/profile
(5)配置salve服务器
首先在slave1.hadoop和slave2.hadoop的/usr/local中创建目录hadoop,然后将它的用户和组改为hadoop
[root@SVR-29-152 local]# mkdir hadoop [root@SVR-29-152 local]# chown hadoop:hadoop hadoop
然后重复前面的(3)、(4)步骤
4.2 配置hadoop
我们先在master.hadoop中进行配置,配置完成后再将hadoop复制到slave1和slave2中。
(1)设置hadoop-env.sh和yarn-env.sh中的java环境变量
cd /usr/local/hadoop/etc/hadoop/ vi hadoop-env.sh // 修改JAVA_HOME export JAVA_HOME=/usr/local/jdk1.8.0_171
(2)配置core-site.xml文件
vi core-site.xml // 修改文件内容为以下 <configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> <description>A base for other temporary directories.</description> </property> <property> <name>fs.default.name</name> <value>hdfs://master.hadoop:9000</value> </property> </configuration>
备注:如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被删掉,必须重新执行format才行,否则会出错。
(3)配置hdfs-site.xml文件
vi hdfs-site.xml // 修改文件内容为以下
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>hadoop-cluster1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master.hadoop:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
(4)配置mapred-site.xml文件
修改Hadoop中MapReduce的配置文件,配置的是JobTracker的地址和端口。
vi mapred-site.xml
// 修改文件为以下内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>master.hadoop:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master.hadoop:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master.hadoop:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://master.hadoop:9001</value>
</property>
</configuration>
(5)配置yarn-site.xml文件
vi yarn-site.xml // 修改文件内容为以下 <configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master.hadoop</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master.hadoop:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master.hadoop:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master.hadoop:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master.hadoop:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master.hadoop:8088</value>
</property>
</configuration>
4.3 配置Hadoop的集群
(1) 将Master中配置好的hadoop传入两个Slave中
注意:使用hadoop账号
scp -r /usr/local/hadoop hadoop@slave1.hadoop:/usr/local/
scp -r /usr/local/hadoop hadoop@slave2.hadoop:/usr/local/
(2) 修改Master主机上的workers文件
[hadoop@SVR-29-151 hadoop]$cd /usr/local/hadoop/etc/hadoop [hadoop@SVR-29-151 hadoop]$ vi workers // 将以下内容写入 slave1.hadoop slave2.hadoop
(3) 格式化HDFS文件系统
// 在Master主机上输入以下指令(使用hadoop用户)
[hadoop@SVR-29-151 hadoop]$ hdfs namenode -format
(4)启动hadoop
[hadoop@SVR-29-151 hadoop]$ start-dfs.sh
结果如下图:

[hadoop@SVR-29-151 hadoop]$ start-yarn.sh

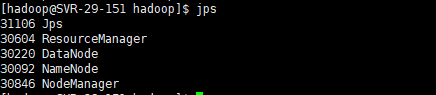
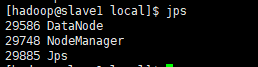
(5) 验证hadoop启动是否成功
[hadoop@SVR-29-151 hadoop]$ jps
master中的结果:
slave中的结果:
web管理页面:http://172.18.29.151:8088/cluster