微服务简介
一、spring boot和spring cloud 的关系
spring boot来写各个拆分出来的微服务,spring cloud把各个微服务联系起来,比如各个微服务通过eurke找到对方
spring cloud还提供很多微服务解决方案,比如网关、安全、熔断降级
二、如何来设计微服务
1.服务拆分
2.服务注册:一个单体架构拆分成多个微服务之后,一个服务怎么知道另一个服务的存在呢,或者怎么找到另一个服务,就需要服务注册
3.服务发现:需要找到另一个服务的时候,可以通过服务的名称去调用另一个服务
4.服务消费(feign或者ribbon实现):A服务区调用B服务, A服务就是消费者,服务被称为提供者
5.统一入口(API网关实现)
服务数量多起来之后肯定难管理,不可能去获知到每一个服务,虽然可以通过服务名称来调用,这样服务的消费者需要记住很多服务的名称话 很麻烦
这就需要一个统一的入口,只需要知道这个入口的名称就可以了,不需要具体的知道每一个服务提供者的名称
6.配置管理(config或者Apollo实现):配置文件管理平台
7.熔断机制(hystrix实现):
系统在高并发的可能会响应不过来,这时候就需要熔断机制,把所有请求都挡住,防止系统崩溃;
通过熔断系统,把请求挡住,返回一个默认的值
8.自动扩展:服务能自动扩容.
三、拆分方法
1.拆分方法
- 用户界面层
- 应用层
- 领域层
- 基础设施层
天气预报系统架构设计
1.拆分后的每个微服务的名称
msa-weather-collection-server
msa-weather-data-server
msa-weather-city-server
msa-weather-report-server
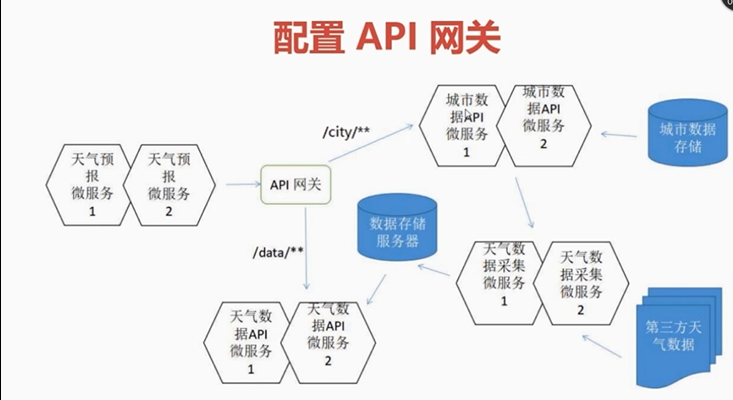
2.天气预报系统每个微服务作用
1)天气数据来自于第三方的数据接口,通过"天气数据采集微服务"采集过来存储到redis
2)所有城市数据列表存储在xml文件,通过"城市数据API微服务"来解析,并提供相应接口给:
- 天气数据采集微服务(根据"城市数据列表微服务"去采集该城市的数据,比如去采集广州的数据)
- 天气预报微服务,因为天气预报微服务需要提供下拉框来选择不同的城市,展示天气情况
3)"天气数据API微服务"数据来源是从redis中获取的,数据提供给"天气预报微服务"来展现
3.天气预报系统工作流程
1).天气数据采集微服务 通过调用"城市数据API微服务"获得该城市的ID或者Name,去采集该城市的天气数据存储到redis
2).天气预报微服务 通过调用"城市数据数据API"获得该城市ID或者Name,在调用"天气数据API微服务"去采集该城市的天气数据,然后展现在web页面
4.天气预报系统接口设计
第三放天气接口
GET http://whther.etouch.cn/weather_mini?citykey={cityId} 参数:cityId
天气数据接口
GET /weather/cityId/{cityId} 参数cityId为城市ID
GET /weather/cityName/{cityName} 参数cityName为城市名称
天气预报接口
GET /report/cityId{cityId} 参数:cityId为城市ID
城市数据接口
GET /cities
系统存储是redis和XML(城市的列表)
spring cloud简介
1.spring cloud作用
- 提供配置管理
- 服务注册,作为服务的管理者,他要了解这些服务的状况,让每个服务都注册到spring cloud中,跟它有交互
- 服务发现:不同服务之间能够互相发现对方,通过服务注册表和服务注册中心实现,发现之后才能调用对方
- 断路器:当系统负载过大的时候它会掐断访问
- 负载均衡、智能路由、微代理、服务间调用、一次性令牌、控制总线、全局锁、领导选举、分布式会话、集群状态、分布式消息
2.spring cloud子项目介绍
1)spring cloud config
配置中心,把配置利用git来集中管理程序的配置,客户端去读git中的配置
2)spring cloud netflix
集群众多netflix的开源软件,包括:Eureka、hystrix、zuul、archaius
3)spring cloud bus
消息总线,利用分布式消息将服务和服务实例连接在一起,用于在一个集群中传播状态的变化,比如配置更改的事件.
可与spring cloud config联合实现热部署
其实就是通信方式
4)spring cloud cluster
基于zookeeper、redis、hazelcast、consul等实现的领导选举和平民状态模式的实现
5)spring cloud consul
实现服务发现和配置管理
6)spring cloud security
在zuul代理中为oauth2 rest客户端和认证头转发,提供负载均衡
7)spring cloud sleuth
适用于spring cloud应用程序的分布式跟踪,与zipkin、htrace和基于日志(例如ELK)的跟踪相兼容.可以做日志收集
8)spring cloud data flow
云本地编排服务.易于使用的DSL、拖放式GUI和REST API一起简化了基于微服务的数据管道的整体编排
9)spring cloud stream
一个轻量级的事件驱动的微服务框架来快速构建可以连接到外部系统的应用程序.使用kafka或者rabbitmq在spring boot应用程序之间发送和接收消息的简单声明模型
10)spring cloud connectors
便于paas应用在各种平台上连接到后端,例如数据可和消息服务
服务发现和注册
1.微服务发现的意义
你发布的服务要让其他的服务找到
2.如何发现服务
通过URI访问访问服务
通过服务名称访问
1)10.2.3.1:8080的java服务注册到Eureka中 叫passport,10.2.3.2:8080的java服务注册到Eureka中 叫passport
2)现在Eureka中passport服务后对应的是10.2.3.1:8080和10.2.3.2:8080的java的服务提供服务
3)然后10.2.3.3:8090服务通过访问passport这个服务名访问到10.2.3.1:8080或者10.2.3.2:8080,不用记IP地址+端口访问了
4)假如把10.2.3.2:8080服务迁移到10.2.3.4中,那么只需要将3.4注册到Eureka的passport服务中, 10.2.3.3就不用更改代码了
3.如何搭建Eureka server
1)创建一个spring cloud项目
2)pox.xml引入eureka-server包
3)在配置里设置监听端口,启动server功能,关闭client功能
4.如何把服务注册进Eureka
2)创建一个spring cloud项目
2)引入eureka-client包
3)在代码里加上@EnableDisCoveryClient 就可以被eureka自动发现了
4)在application.properties配置文件里加上如下内容
spring.application.name: passport #注册到eureka server的服务名称
eureka.client.serviceUrl.defaultZone: http://localhost:8761/eureka/ #eureka的server地址
微服务消费者
1.微服务消费模式
1)服务直连模式,直接通过域名或者路径访问
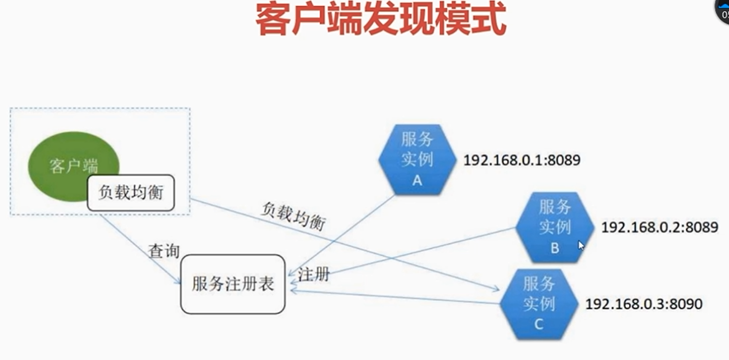
2)客户端发现模式,服务实例启动后,将自己的位置信息提交到注册中心;客户端从注册中心查询,来获取可用的服务实例;客户端自行使用负载均衡算法从多个实例中选择出一个
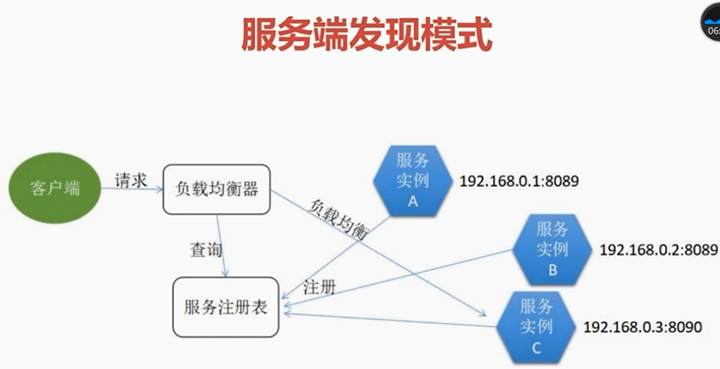
3)服务端发现模式,跟客户端发现模式唯一的区别,就是负载均衡不是客户端来做的,是服务端做的 架构见图
2.常见微服务消费者
1)httpClient
2)ribbon
基于客户端的负载均衡,结合eureka,使用支持http和tcp来实现客户端的负载均衡,Eureka为微服务实例提供服务注册,Robbon作为服务消费的客户端;
Ribbon使用方法
添加依赖
dependencies { compile('org.springframework.cloud:spring-clou-starter-netflix-ribbon') }
注入
加入:@RibbonClient(name="Ribbon-client",configuration = RibbonConfiguration.class)
配置
LB的算法等等
使用
restTemplate.getForEntity("http://passport/cities",String.class) #直接通过注册到eureka的服务名+路径调用.原来是10.2.3.1:8080/cities
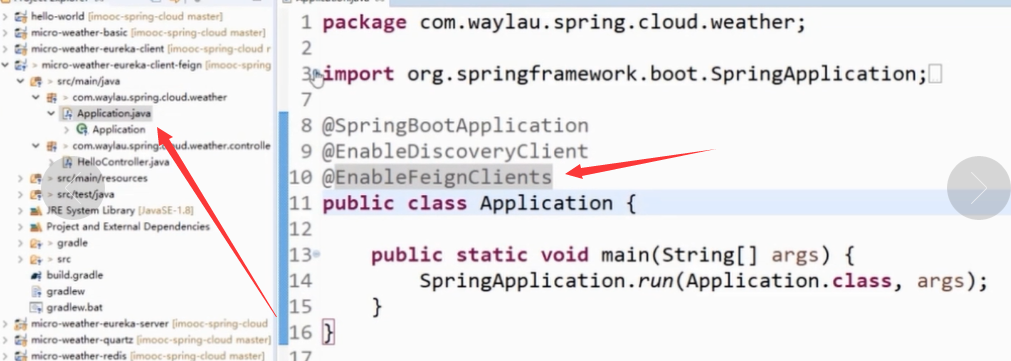
3)feign #这个最常用
①pox. 中添加feign依赖

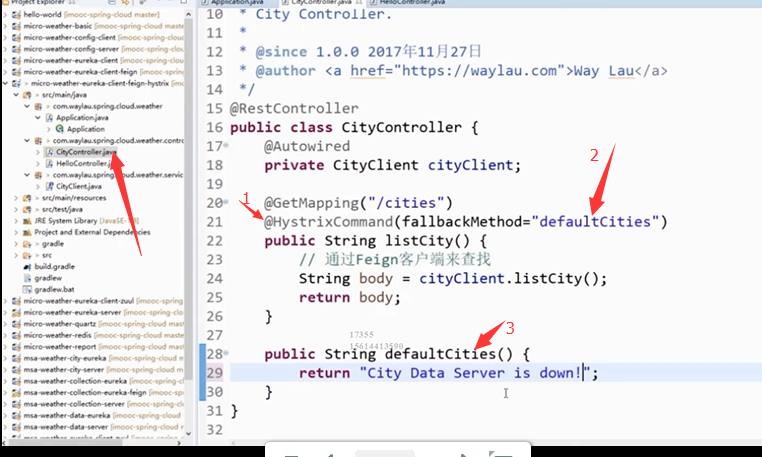
②在Application.java启动类中添加@EnableFeignClients
API网关
1.作用:统一服务入口,可以方便的实现对平台众多服务接口进行管控,对访问的用户身份进行验证,防止数据篡改,业务功能的鉴权,响应数据的脱敏,流量和并发的控制
2.API网关的意义
集合多个API,对多个API进行管理
统一API入口
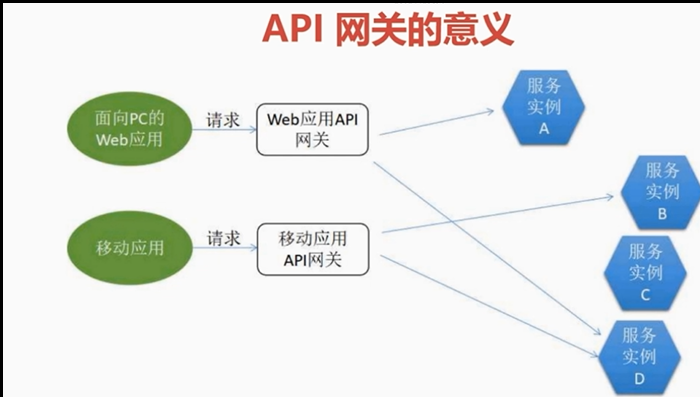
3.API网关的好处
- 避免将内部信息泄露给外部,能够将外部公共API跟内部的微服务的API区分开(外部就是给Android之类的调用,内部就是给微服务之间调用)
- 为微服务添加额外的安全层:为全部的微服务提供统一的入口,从而避免的外面客户进行服务发现和版本控制时都没有授权的API进行访问
- 支持混合通信协议
- 降低构建微服务的复杂性
- 微服务模拟与虚拟化,通过将微服务内部的API和外部的API加以区分
4.API网关弊端
- 路由逻辑配置要进行统一管理,这样才能保证合理的路由连接
- API网关需要做高可用
5.常见API网关实现方法
- Nginx
- spring cloud zuul
- KONG
6.如何集成zuul
功能:认证、压力测试、金丝雀测试、动态路由、负载削减、安全、静态响应处理、主动交换管理
1)在controller中引入zuul,@EnableZuulProxy
2)在application.properties中写方法,比如zuul.routes.path: /hi/**, zuul.routes.hi.serviceId:passport,就是访问zuul的时候,只要是/hi这个路径的,就将请求转发给passport微服务处理

微服务的集中化配置
一、为什么需要集中化配置
- 微服务数量多,配置多;一个微服务需要部署到多台机器,各自有不同的配置
- 手工管理配置繁琐
二、集中化配置按什么分类
1.按照配置的来源划分
主要有源代码、文件、数据库连接、远程调用等
2.按照配置的环境划分
开发环境、测试环境、预发布环境、生产环境
3.按照配置的集成阶段划分
编译时:源代码级别的配置;把源代码和编译文件一起提交到代码仓库
打包时:打包阶段通过某种形式将配置文件打入到最终的应用中
运行时:应用在启动前不需要知道具体的配置,在启动的时候就可以在本地或者远程获取配置文件
4.按照配置的加载方式划分
启动加载: 应用在启动时获取配置,并且是只获取一次,在应用起来之后就不会再去加载配置了(比如端口号,线程池的信息,基本上一启动就不会变)
动态加载: 应用在运行的各个过程中随时 都可以获取到的一些配置;这些配置意味着在应用运行过程中可能会被经常的修改(比如页面中分页的大小,比如从一页20,改为一页30,改完就会生效的)
三、配置中心的要求
1.面向可配置的编码,提取出来,不能写死
比如页面分页的大小,数据库的连接池
2.隔离性
不能的部署环境,应用之间的配置要隔离,比如生产环境一个配置,测试环境一个配置
3.一致性
同个微服务,如果要部署在多台机器上做分布式,要使用同一个配置
4.集中化配置
在分布式环境下应用的配置应该要具备可管理性;配置可以被远程管理
四、spring cloud config架构
config server:基于git,所以能轻松的实现标记版本的配置环境(可以实现环境+版本的区分),可以访问管理内容
config client:
五、如何集成spring cloud config
1.配置config server
添加依赖: dependencies {compile('org.springframe.cloud:spring-cloud-config-server')}
引入config server注解:@EnableConfigServer
修改application.properties
spring.application.name: micro-weather-config-server #服务名称
server.port=8888
eureka.client.serviceUrl.defaultZone: http://localhost:8761/eureka #注册到eureka-server
spring.cloud.config.server.git.uri=https://github.com/waylau/spring-cloud-microservice-development #指定git地址
spring.cloud.config.server.git.searchPaths=config-repo #指定git下面的路径,跟上面合起来就是https://github.com/waylau/spring-cloud-microservice-development/config-repo
2.配置config client
添加依赖 dependcies { compile('org.springframe.cloud:spring-cloud-config-client') }
修改application.properties
spring.application.name: passport #服务名称
eureka.client.serviceUrl.defaultZone: http://localhost:8761/eureka #注册到eureka-server
spring.cloud.config.profile=dev #指定环境
spring.cloud.config.uri= http://localhost:8888 #指定config server地址
#### https://github.com/waylau/spring-cloud-microservice-development目录下有个配置文件叫passport-dev.properties,内容如下
auther=mayun #指定一个作者名字
3.配置文件命名规则
{application—name}-{profile}.properties
比如:passport-dev.properties
那passport微服务怎么找到这个配置文件呢
就是通过application.properties中的服务名称-环境(passport-dev)去config server中application.properties中定义的地址里去找passport-dev.properties
4.让passport去调用远程配置文件
写一个测试用例 public class ApplicationTests { @Value("${auther}") @Test public void contextLoads() { assertEquals("mayun",auther) #如果配置文件中的auther的值跟我定义的"mayun"相等,那么就是读取到了 } }
服务的熔断降级
1.什么是服务的熔断机制
如果突然间访问量过大,超过我们的承受能力,就需要熔断机制,不至于让我们的资源耗尽,我们又要做响又要做防护,就靠熔断机制
比如访问量突然过大,超过我们的承受能力(设置阈值),就返回给用户一个默认值(比如错误页面之类的)
2.熔断的原理
就是断路器
3.断路器的模式
1)微软的方案
close(关闭) Half-open(半打开) open(打开)
如果服务正常的时候,断路器默认是close的,如果请求过来失败的次数超过定义的阈值,会启动一个定时器,这段时间断路器是half-open(给系统处理问题的时候),如果超过这个定时器,断路器就会完全打开,给请求的用户返回一个自定义的默认值
2)spring cloud hystrix方案
如果某个服务崩了不正常了,不能提供正常响应的,这时候就会启用一个断路器,把该服务的响应断开,这时候就有一个Fallback,返回一个错误信息给用户
4.熔断的意义
好处:
系统稳定:如果服务崩了,可以快速给用户返回一个响应,而不是让这个访问等待超时
减少性能损耗:如果服务崩了,直接返回一个简单的响应内容给用户,让用户知道服务挂了,而不是一直重试 占用系统资源
及时响应:
阈值可定制:比如请求数超过1W就启用熔断器,
功能:
异常处理:例如应用程序会暂时的降级,然后调用备选的操作,来尝试相同的任务或者获取相同的数据,或者将这个应用通知给用户,让他稍后再试
日志记录:断路器能记录失败的请求数,以便管理者能
测试失败的操作:
手动复位:
并发:熔断器可以被大量并发访问,大量请求过来后导致服务无法响应,这时候才启用熔断,这时候所以的请求都是被熔断器处理了,所以熔断器需要能抗住大量并发
加速断路:
重试失败:把失败的详细信息记录下来,在系统恢复正常的时候,在重试一下失败的请求,就是把流量copy下来,在系统恢复正常之后 在重试
5.熔断与降级的区别
熔断器是比如某个微服务故障了 就会触发熔断操作
降级就是,原本每天有100个请求,现在每天只有50个请求,那么就会降低一个服务数量
6.如何集成hystrix
在spring cloud中hystrix会监控微服务的调用状况,当失败的调用达到一定的阈值的时候,就会启用熔断机制
hystrix有一个注解叫做hystrix command,通过这个注解将注解的这个类关联到熔断器连在一起的代理上
1)开发环境
spring cloud starter OpenFeign Finchley.M2
spring cloud starter Netflix Hystrix Finchley.M2
2)创建熔断器(添加hystrix依赖)
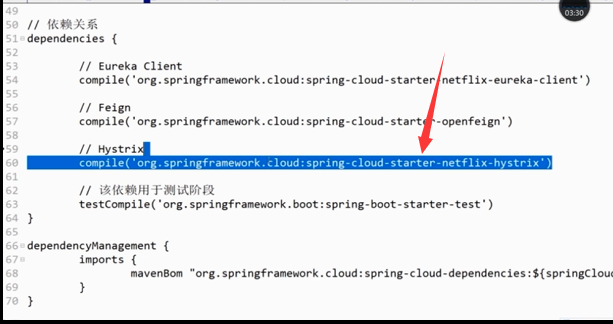
3)启用熔断器(加上注解)
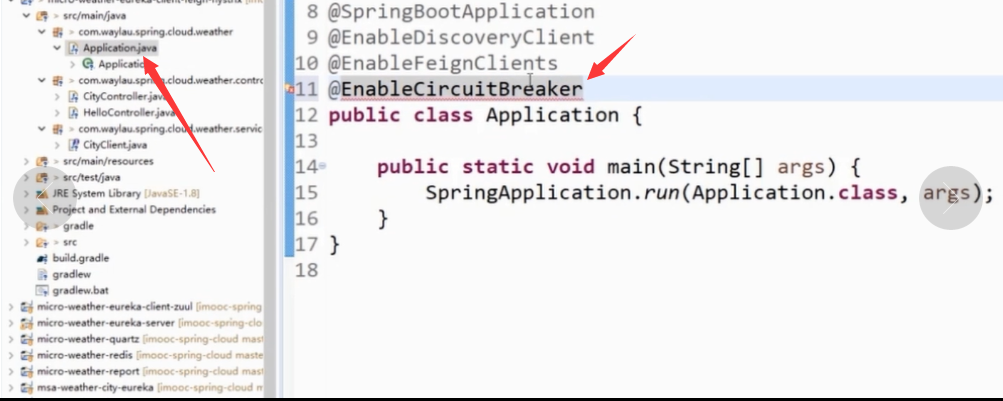
3)在controller中加入HystrixCommand注解