目标检测之anchor https://zhuanlan.zhihu.com/p/55824651
【深度学习】感受野 https://blog.csdn.net/baidu_27643275/article/details/88711329
感受野详解 https://blog.csdn.net/qq_41076797/article/details/114434415
CNN基础知识——卷积(Convolution)、填充(Padding)、步长(Stride)
https://zhuanlan.zhihu.com/p/77471866
1. yolo v1
(1)优点:
YOLO检测速度非常快。标准版本的YOLO可以每秒处理 45 张图像;YOLO的极速版本每秒可以处理150帧图像。这就意味着 YOLO 可以以小于 25 毫秒延迟,实时地处理视频。对于欠实时系统,在准确率保证的情况下,YOLO速度快于其他方法。
YOLO 实时检测的平均精度是其他实时监测系统的两倍。
迁移能力强,能运用到其他的新的领域(比如艺术品目标检测)。
(2)局限:
YOLO对相互靠近的物体,以及很小的群体检测效果不好,这是因为一个网格只预测了2个框,并且都只属于同一类。
由于损失函数没有完成对大小物体进行区别对待,损失函数没有完成对大小物体进行区别对待 ,因为对IOU影响较大 ,定位误差是影响检测效果的主要原因.
YOLO对数据依赖强 , 对不常见的角度的目标泛化性能偏弱,下采样过多,导致特征过于粗糙。
2. yolo v2
YOLOv2在YOLO的基础上进行了大量的改进:
ü 加入Batch Normalization
ü 为主干网络训练进行高分辨率的fine tune
ü 加入anchor box机制
ü 使用k-mean来辅助anchor的设定
ü 沿用YOLO的方法对anchor中心点进行修正
ü 使用passthrough layer,融合低维度特征
ü 使用multi-scale trainning提高准确率
ü 提出darknet-19来加速
ü 使用hierarchical classification进行超多目标的分类
3. yolo v3
YOLOv3在YOLOv2的基础上主要是融合一些用于提高准确率的方法:
ü 将类别置信度预测改为逻辑独立分类 将softmax loss 变成logistic loss
ü 结合FPN的结构进行多level的预测
ü 提出Darknet-53,将shortcut连接加入到网络中
² loss不同:作者v3替换了v2的softmax loss 变成logistic loss,而且每个ground truth只匹配一个先验框。
² anchor bbox prior不同:v2作者用了5个anchor,一个折衷的选择,所以v3用了9个anchor,提高了IOU。
² detection的策略不同:v2只有一个detection,v3一下变成了3个,分别是一个下采样的,feature map为13*13,还有2个上采样的eltwise sum,feature map为26*26,52*52,也就是说v3的416版本已经用到了52的feature map,而v2把多尺度考虑到训练的data采样上,最后也只是用到了13的feature map,这应该是对小目标影响最大的地方。
² backbone不同:这和上一点是有关系的,v2的darknet-19变成了v3的darknet-53,为啥呢?就是需要上采样啊,卷积层的数量自然就多了,另外作者还是用了一连串的3*3、1*1卷积,3*3的卷积增加channel,而1*1的卷积在于压缩3*3卷积后的特征表示,这波操作很具有实用性,一增一减,效果棒棒。
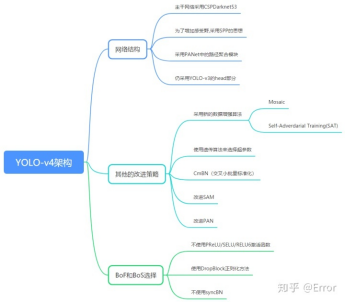
- yolo v4
输入端采用mosaic数据增强,
Backbone上采用了CSPDarknet53、Mish激活函数、Dropblock等方式,
Neck中采用了SPP、FPN+PAN的结构,
输出端则采用CIOU_Loss、DIOU_nms操作。
(1)BoF(bag of freebies)
在文中是指那些能够提高精度而不增加推断时间的技术。
比如数据增广的方法:图像几何变换、Cutout、grid mask等,
网络正则化的方法:Dropout、Dropblock等,
类别不平衡的处理方法,
难例挖掘方法,
损失函数的设计等,
(2) BoS(bag of specials)
是指那些增加稍许推断代价,但可以提高模型精度的方法。
比如增大模型感受野的SPP、ASPP、RFB等,
引入注意力机制Squeeze-and-Excitation (SE) 、Spatial Attention Module (SAM)等 ,
特征集成方法SFAM , ASFF , BiFPN等,
改进的激活函数Swish、Mish等,
或者是后处理方法如soft NMS、DIoU NMS等,
5. yolo v5
(1)数据增强
(2)自适应锚框
(3)自适应图片缩放
(4)Focus结构
(5)CSP结构(用于Backbone和Neck)
(6)GIOU
(7)nms非极大值抑制
(1)输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
(2)Backbone:Focus结构,CSP结构
(3)Neck:FPN+PAN结构
(4)Prediction:GIOU_Loss