连接池
1.连接池是一个用来存储连接的容器
2.连接池是一个集合对象,该集合必须是线程安全的,不能两个线程拿到同一个连接
3.该集合实现队列的特征:先进先出(在mybatis中实际上是ArrayList)

连接池在配置文件的位置
<environments default="mysql"> <environment id="mysql"> <transactionManager type="JDBC"></transactionManager> <dataSource type="POOLED">
有三种内建的数据源类型(也就是 type=”[UNPOOLED|POOLED|JNDI]”):
MyBatis 在初始化时, 根据<dataSource>的 type 属性来创建相应类型的的数据源 DataSource,即:
type=”POOLED”: MyBatis 会创建 PooledDataSource 实例
type=”UNPOOLED” : MyBatis 会创建 UnpooledDataSource 实例
type=”JNDI”: MyBatis 会从 JNDI 服务上查找 DataSource 实例,然后返回使用

主要讲一下:pooled与unpooled
MyBatis 内部分别定义了实现了 java.sql.DataSource 接口的 UnpooledDataSource,
PooledDataSource 类来表示 UNPOOLED、 POOLED 类型的数据源。
在这三种数据源中,我们一般采用的是 POOLED 数据源(很多时候我们所说的数据源就是为了更好的管理数据
库连接,也就是我们所说的连接池技术) 。
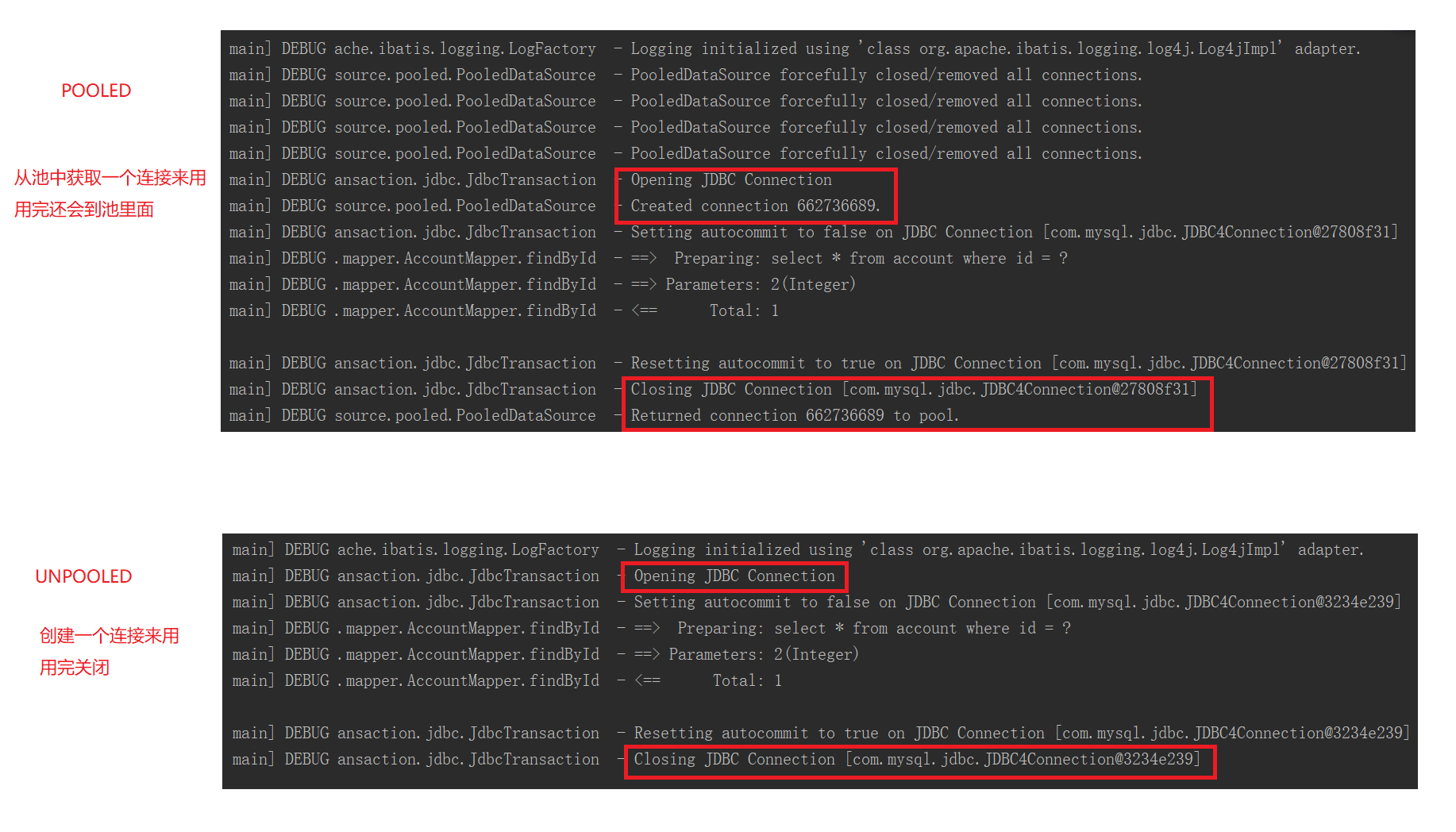
追踪unpooled
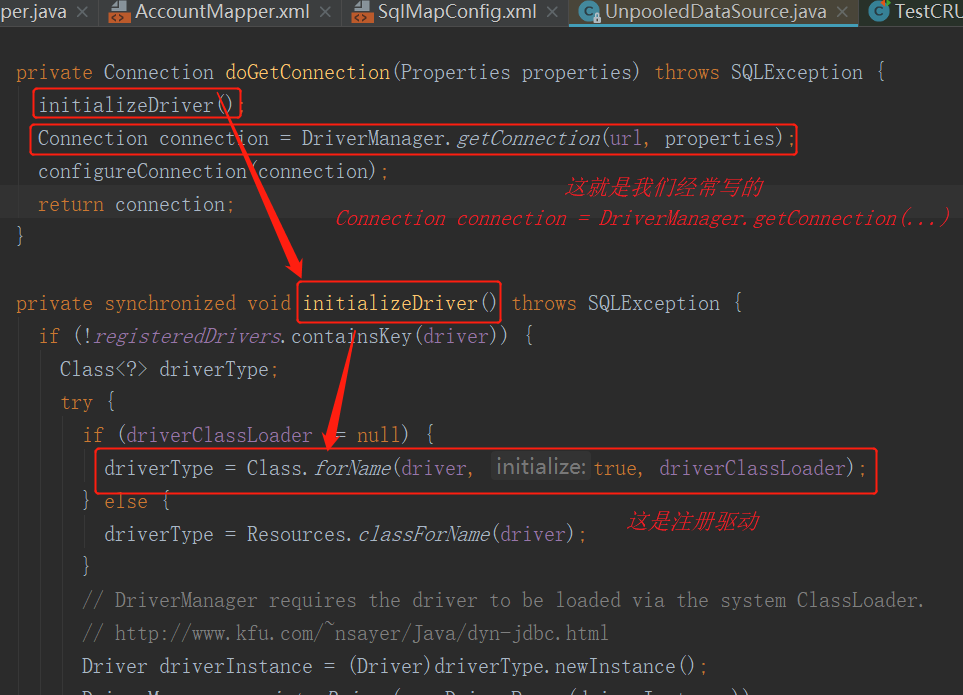
在idea中通过【ctrl + N】搜索【unpooleddatasource】,找到如下
贴一下jdbc中的执行步骤
//1.加载数据库驱动 //Class.forName是把这个类加载到JVM中,加载的时候,就会执行其中的静态初始化块,完成驱动的初始化的相关工作。 Class.forName("com.mysql.jdbc.Driver"); //2.通过驱动管理类获得数据库连接a connection = DriverManager.getConnection ("jdbc:mysql://localhost:3306/cong","root","123456"); //3.定义sql语句 String sql = "select * from account where id = ?"; //4.获得预处理statement preparedStatement = connection.prepareStatement(sql); //5.设置参数,第一个参数为 sql 语句中参数的序号(从 1 开始),第二个参数为设置的参数值 preparedStatement.setString(1, "1"); //6.执行操作 resultSet = preparedStatement.executeQuery(); //7.处理结果 while (resultSet.next()){ System.out.println("Account:"+resultSet.getInt("id") + "," + resultSet.getString("name")+ ","+resultSet.getFloat("money")); }
追踪pooled
在idea中通过【ctrl + N】搜索【pooleddatasource】,找到如下

分析源代码,得出 PooledDataSource 工作原理如下:

下面是获取连接的源码
@Override public Connection getConnection() throws SQLException { return popConnection(dataSource.getUsername(), dataSource.getPassword()).getProxyConnection(); } @Override public Connection getConnection(String username, String password) throws SQLException { return popConnection(username, password).getProxyConnection(); }
最后我们可以发现,真正连接打开的时间点,只是在我们执行SQL语句时,才会进行。其实这样做我们也可以
进一步发现,数据库连接是我们最为宝贵的资源,只有在要用到的时候,才去获取并打开连接,当我们用完了就再
立即将数据库连接归还到连接池中
我们在实际开发中都会使用连接池。
因为它可以减少我们获取连接所消耗的时间。
事务管理
mybatis中的事务是通过sqlsession对象的commit方法和rollback方法实现事务的提交和回滚
找到JdbcTransaction.java和SqlSessionFactory.java中的源码,可以发现

于是,在我们的测试类中,可以这样修改
当然,这个只能用于每次都仅仅执行一个对数据库的crud操作的时候才可以用
像之前的转账操作,相当于在一个测试方法里面多次跟数据库进行交互,
如果让每个连接都处于独立的自动提交,那这个事务肯定是控制不住的
spring中的转账传送门:https://www.cnblogs.com/ccoonngg/p/11229393.html
@Before//在测试方法执行之前执行 public void init() throws Exception { //1.读取配置文件,生成字节输入流 inputStream = Resources.getResourceAsStream("SqlMapConfig.xml"); //2.获取SqlSessionFactoryBuilder SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(inputStream); //3.生成sqlSession sqlSession = factory.openSession(true);//参数true表示自动提交 //4.获取mapper的代理对象 mapper = sqlSession.getMapper(AccountMapper.class); } @After//在测试方法执行之后执行 public void close() throws Exception { //提交事务,增删改需要提交事务,数据库才会发生改变 //sqlSession.commit(); //释放资源 sqlSession.close(); inputStream.close(); }
再运行一次,很明显,自动提交了
我们发现,此时事务就设置为自动提交了,同样可以实现CUD操作时记录的保存。虽然这也是一种方式,但就
编程而言,设置为自动提交方式为 false 再根据情况决定是否进行提交,这种方式更常用。因为我们可以根据业务
情况来决定提交是否进行提交。
以下引用mybatis文档
传送门:http://www.mybatis.org/mybatis-3/zh/configuration.html#environments
事务管理器(transactionManager)
在 MyBatis 中有两种类型的事务管理器(也就是 type=”[JDBC|MANAGED]”):
1.JDBC – 这个配置就是直接使用了 JDBC 的提交和回滚设置,它依赖于从数据源得到的连接来管理事务作用域。
2.MANAGED – 这个配置几乎没做什么。它从来不提交或回滚一个连接,而是让容器来管理事务的整个生命周期(比如 JEE 应用服务器的上下文)。
默认情况下它会关闭连接,然而一些容器并不希望这样,因此需要将 closeConnection 属性设置为 false 来阻止它默认的关闭行为。例如:
<transactionManager type="MANAGED">
<property name="closeConnection" value="false"/>
</transactionManager>
提示:如果你正在使用 Spring + MyBatis,则没有必要配置事务管理器, 因为 Spring 模块会使用自带的管理器来覆盖前面的配置。
这两种事务管理器类型都不需要设置任何属性。它们其实是类型别名,换句话说,你可以使用 TransactionFactory 接口的实现类的完全限定名或类型别名代替它们。
public interface TransactionFactory {
default void setProperties(Properties props) { // Since 3.5.2, change to default method
// NOP
}
Transaction newTransaction(Connection conn);
Transaction newTransaction(DataSource dataSource, TransactionIsolationLevel level, boolean autoCommit);
}
任何在 XML 中配置的属性在实例化之后将会被传递给 setProperties() 方法。你也需要创建一个 Transaction 接口的实现类,这个接口也很简单:
public interface Transaction {
Connection getConnection() throws SQLException;
void commit() throws SQLException;
void rollback() throws SQLException;
void close() throws SQLException;
Integer getTimeout() throws SQLException;
}
使用这两个接口,你可以完全自定义 MyBatis 对事务的处理。
数据源(dataSource)
dataSource 元素使用标准的 JDBC 数据源接口来配置 JDBC 连接对象的资源。
许多 MyBatis 的应用程序会按示例中的例子来配置数据源。虽然这是可选的,但为了使用延迟加载,数据源是必须配置的。
有三种内建的数据源类型(也就是 type=”[UNPOOLED|POOLED|JNDI]”):
UNPOOLED– 这个数据源的实现只是每次被请求时打开和关闭连接。虽然有点慢,但对于在数据库连接可用性方面没有太高要求的简单应用程序来说,是一个很好的选择。 不同的数据库在性能方面的表现也是不一样的,对于某些数据库来说,使用连接池并不重要,这个配置就很适合这种情形。UNPOOLED 类型的数据源具有以下属性。:
- driver – 这是 JDBC 驱动的 Java 类的完全限定名(并不是 JDBC 驱动中可能包含的数据源类)。
- url – 这是数据库的 JDBC URL 地址。
- username – 登录数据库的用户名。
- password – 登录数据库的密码。
- defaultTransactionIsolationLevel – 默认的连接事务隔离级别。
- defaultNetworkTimeout – 超时,毫秒数
作为可选项,你也可以传递属性给数据库驱动。只需在属性名加上“driver.”前缀即可,例如:
- driver.encoding=UTF8
这将通过 DriverManager.getConnection(url,driverProperties) 方法传递值为 UTF8 的 encoding 属性给数据库驱动。
POOLED– 这种数据源的实现利用“池”的概念将 JDBC 连接对象组织起来,避免了创建新的连接实例时所必需的初始化和认证时间。 这是一种使得并发 Web 应用快速响应请求的流行处理方式。
除了上述提到 UNPOOLED 下的属性外,还有更多属性用来配置 POOLED 的数据源:
- poolMaximumActiveConnections – 在任意时间可以存在的活动(也就是正在使用)连接数量,默认值:10
- poolMaximumIdleConnections – 任意时间可能存在的空闲连接数。
- poolMaximumCheckoutTime – 在被强制返回之前,池中连接被检出(checked out)时间,默认值:20000 毫秒(即 20 秒)
- poolTimeToWait – 这是一个底层设置,如果获取连接花费了相当长的时间,连接池会打印状态日志并重新尝试获取一个连接(避免在误配置的情况下一直安静的失败),默认值:20000 毫秒(即 20 秒)。
- poolMaximumLocalBadConnectionTolerance – 这是一个关于坏连接容忍度的底层设置, 作用于每一个尝试从缓存池获取连接的线程。 如果这个线程获取到的是一个坏的连接,那么这个数据源允许这个线程尝试重新获取一个新的连接,但是这个重新尝试的次数不应该超过 poolMaximumIdleConnections 与 poolMaximumLocalBadConnectionTolerance 之和。 默认值:3 (新增于 3.4.5)
- poolPingQuery – 发送到数据库的侦测查询,用来检验连接是否正常工作并准备接受请求。默认是“NO PING QUERY SET”,这会导致多数数据库驱动失败时带有一个恰当的错误消息。
- poolPingEnabled – 是否启用侦测查询。若开启,需要设置 poolPingQuery 属性为一个可执行的 SQL 语句(最好是一个速度非常快的 SQL 语句),默认值:false。
- poolPingConnectionsNotUsedFor – 配置 poolPingQuery 的频率。可以被设置为和数据库连接超时时间一样,来避免不必要的侦测,默认值:0(即所有连接每一时刻都被侦测 — 当然仅当 poolPingEnabled 为 true 时适用)。
JNDI – 这个数据源的实现是为了能在如 EJB 或应用服务器这类容器中使用,容器可以集中或在外部配置数据源,然后放置一个 JNDI 上下文的引用。这种数据源配置只需要两个属性:
- initial_context – 这个属性用来在 InitialContext 中寻找上下文(即,initialContext.lookup(initial_context))。这是个可选属性,如果忽略,那么将会直接从 InitialContext 中寻找 data_source 属性。
- data_source – 这是引用数据源实例位置的上下文的路径。提供了 initial_context 配置时会在其返回的上下文中进行查找,没有提供时则直接在 InitialContext 中查找。
和其他数据源配置类似,可以通过添加前缀“env.”直接把属性传递给初始上下文。比如:
- env.encoding=UTF8
这就会在初始上下文(InitialContext)实例化时往它的构造方法传递值为 UTF8 的 encoding 属性。
你可以通过实现接口 org.apache.ibatis.datasource.DataSourceFactory 来使用第三方数据源:
public interface DataSourceFactory {
void setProperties(Properties props);
DataSource getDataSource();
}
org.apache.ibatis.datasource.unpooled.UnpooledDataSourceFactory 可被用作父类来构建新的数据源适配器,比如下面这段插入 C3P0 数据源所必需的代码:
import org.apache.ibatis.datasource.unpooled.UnpooledDataSourceFactory;
import com.mchange.v2.c3p0.ComboPooledDataSource;
public class C3P0DataSourceFactory extends UnpooledDataSourceFactory {
public C3P0DataSourceFactory() {
this.dataSource = new ComboPooledDataSource();
}
}
为了令其工作,记得为每个希望 MyBatis 调用的 setter 方法在配置文件中增加对应的属性。 下面是一个可以连接至 PostgreSQL 数据库的例子:
<dataSource type="org.myproject.C3P0DataSourceFactory">
<property name="driver" value="org.postgresql.Driver"/>
<property name="url" value="jdbc:postgresql:mydb"/>
<property name="username" value="postgres"/>
<property name="password" value="root"/>
</dataSource>