1.Faster R-CNN
1.1 流程
Faster R-CNN网络结构:
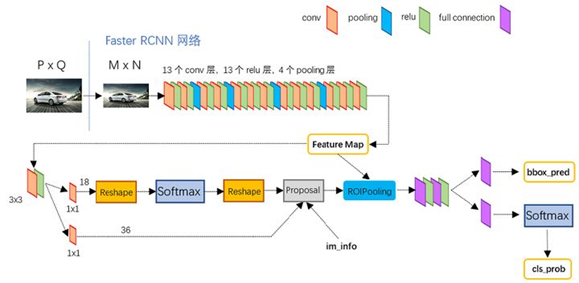
(这个是引用的原图,其实并没看明白,我翻了书查人网上解说,归结了以下)
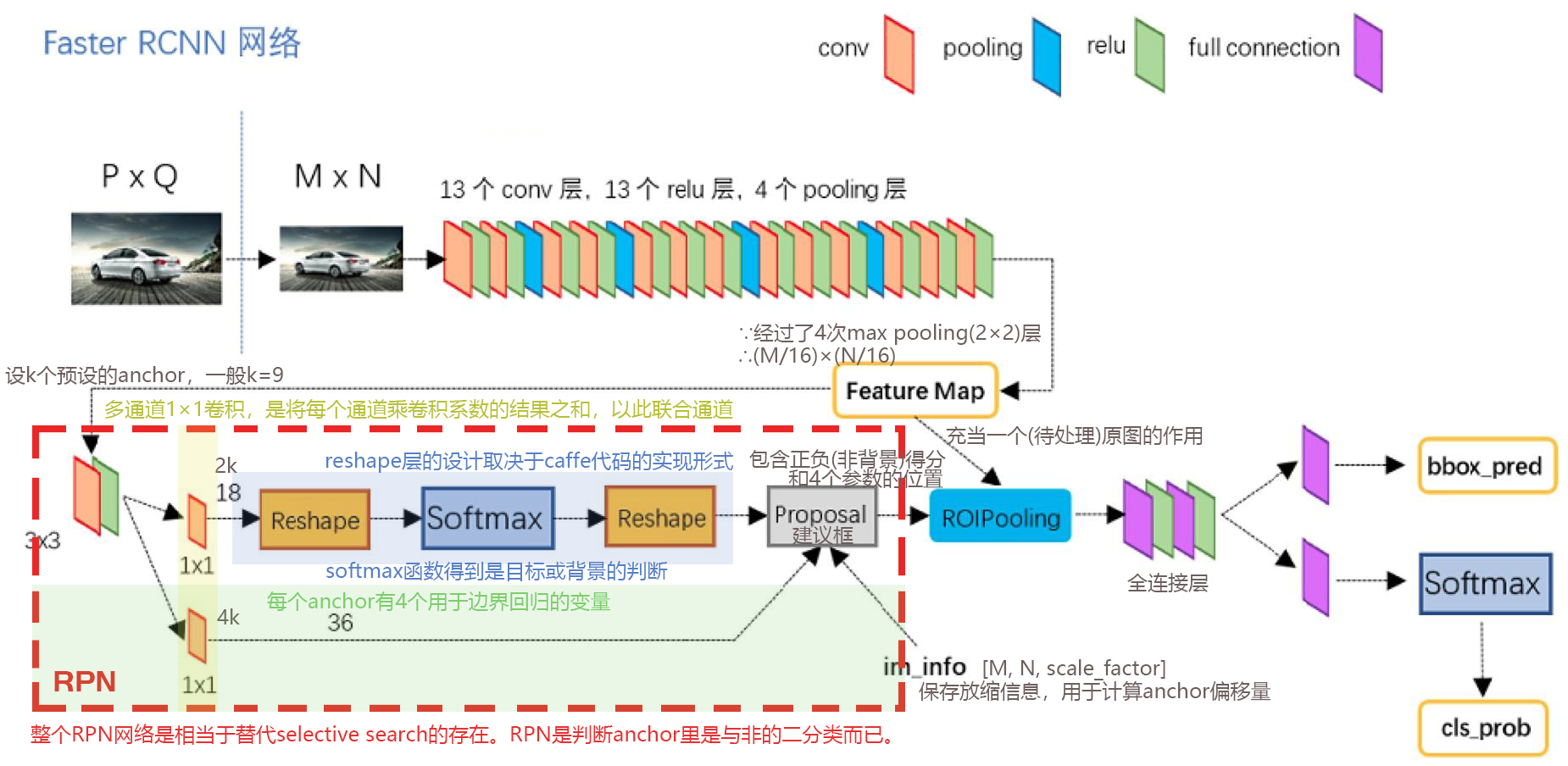
1.2 RPN(Region Proposal Network)
锚点(anchor),是一个固定的矩形框,它的形状和大小可以预设为k个,一般k取9,比例可以如下图示:
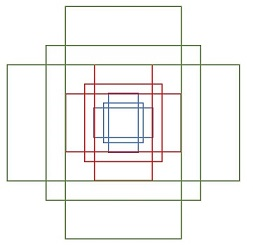
RPN起始的3×3卷积层可以看作是一个滑动窗口,它在特征图上每个点上滑行,anchor以这个点为核心展开上面9个尺寸。
而后的1×1卷积层是把多个通道联合起来,
一个出参18个(9*2,2表示分类结果数,分别是非背景得分和背景得分);##?这里有点奇怪,0和1表示结果,那占1个位就可以了
另一个出参36个(9*4,4表示位置,坐标和宽高)。
RPN接入到Fast-RCNN,其入参的建议框有处理:
先用anchor得到4个位置参数,剔除明显超出边界的建议框;##这一点我不明白,为什么不先筛选类别再求位置
取前景softmax得分最高的6000个,再用非极大值抑制筛选一批建议框,最后将不超过300个proposal层输出的建议框到ROI Pooling层。(详细参照proposal_layer.py代码)
RPN是一个多任务损失函数,它的总损失定义:

p是前景背景的分类层,t是边界框回归层,i是mini-batch中的一个anchor索引,pi是预测为目标的概率,p*i是标签。
……(详解略,此处针对流程)
1.3 如何训练
如何让RPN和Fast R-CNN融合成一个统一的网络,这需要二者共享卷积层,一个实现的思路是:交替训练,以优化最终的Faster R-CNN。
(1) 单独训练RPN
RPN是通过反向传播和随机梯度下降的方式进行端到端的训练。
首先网络入参,取预训练(例如VGG16)模型载入,且叫它R1;作为监督型网络,它的标签需要我们自己处理出样本。
(训练中,每个mini-batch要有由R1中随机出来的256个anchor,正负样本各一半(正样本少一些也可),其中正样本IoU>0.7,负样本0 < IoU < 0.3)
(2) 单独训练Fast R-CNN
将(1)训练出来的RPN作为此网络的入参。
(3) 联合上述网络后训练RPN
(1)(2)网络接入,并且将(2)Fast R-CNN的学习率设置为0,以此固定(2),仅更新(1)。
(4) 微调Fast R-CNN网络
固定(1)参数,调整(2)的部分。
这个实验我没做过,书上是说实验证明,上述训练过程多次迭代并没有明显效果。
===========================================
资料:
https://zhuanlan.zhihu.com/p/31426458
杜鹏、谌(chen2)明、苏统华 编著《深度学习与目标检测》
2. R-FCN(基于区域的全卷积网络)
Faster R-CNN中需要对RPN给出的RoI计算,而RPN本身也要计算出RoI,这当中就有重复计算,R-FCN主要针对这一点,提出位置敏感分数图,以解决图像分类中的平移不变性(translation invariance)与目标检测中的平移可变性(translation variance)之间的矛盾。
平移指目标所在图像位置变化,目标位置变了,但目标分类不变,此为平移不变性,但位置出参会变化,此为平移可变性。
需要注意的是,引入的预训练模型,像是AlexNet、VGGNet都是分类模型,会存在平移不变性的问题,那对于识别目标位置并不友好,所以才有了Fast/Faster R-CNN这样中间插入一段RoI网络的设计,加深了RoI子网络提高了精度同时也牺牲了计算速度。
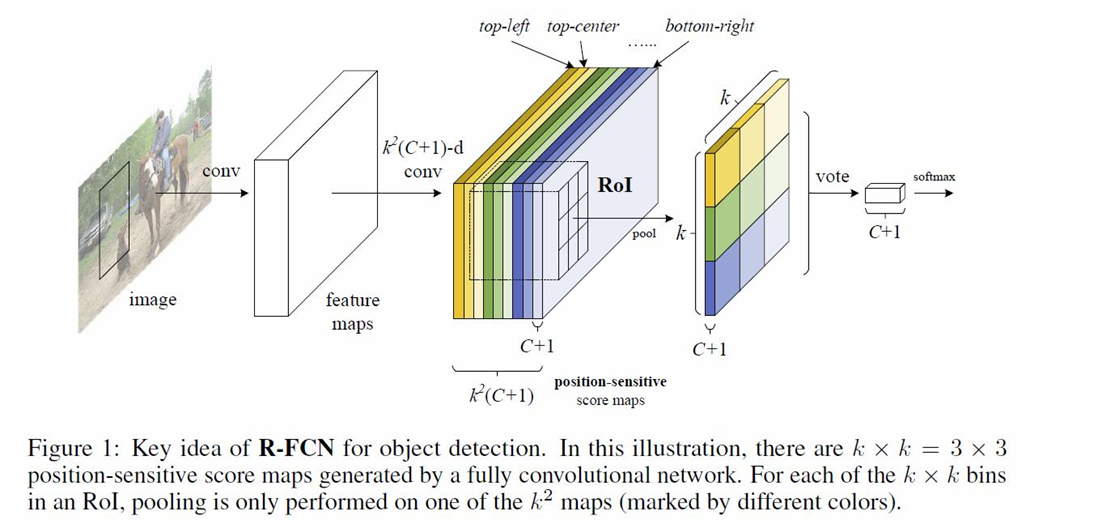
R-FCN使用了一组专门的卷积层来构建一组位置敏感的分数图,以替代在Faster R-CNN中RPN的后接部分。
它沿用RPN提取建议框RoI,然后利用分类的平移不变性,在最后的卷积层后,把卷积层平均切分成k*k块,给这k*k块作C+1种分类打分,C是分类数量,1是背景。所以RPN出的聚合RoI(position-sensitive RoI-pool)大小为k*k*(C+1)和4*k*k(?这点持怀疑)。聚合RoI上的投票时求平均值的过程,对C+1个k*k区域求平均值(代码实现为一个平均池化层),得到C+1维向量,再用softmax函数出最终类别。
===========================================
资料:
杜鹏、谌(chen2)明、苏统华 编著《深度学习与目标检测》