numpy.random包含多种概率分布的随机样本,是数据分析辅助的重点工具之一。
1.生成标准正态分布
# 随机数生成 samples = np.random.normal(size=(4,4)) print(samples) # 生成一个标准正态分布的4*4样本值
运行结果:
[[ 1.39503381e+00 -8.78976381e-01 -3.91561368e-01 1.53535114e+00] [ 2.42761416e-01 -9.14683577e-01 5.31498034e-01 -5.34133555e-01] [-8.23769059e-01 9.67241954e-01 1.32559619e+00 -5.99931949e-04] [ 1.16256260e+00 1.68124375e+00 -1.14891175e-01 2.29245845e+00]]
2.生成一个[0,1)之间的随机浮点数或N维浮点数组 —— 均匀分布
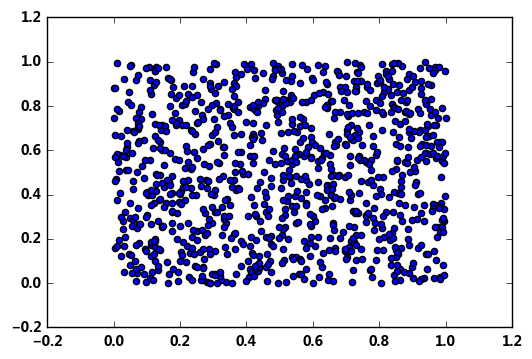
# numpy.random.rand(d0, d1, ..., dn):生成一个[0,1)之间的随机浮点数或N维浮点数组 —— 均匀分布 import matplotlib.pyplot as plt # 导入matplotlib模块,用于图表辅助分析 % matplotlib inline # 魔法函数,每次运行自动生成图表 a = np.random.rand() print(a,type(a)) # 生成一个随机浮点数 b = np.random.rand(4) print(b,type(b)) # 生成形状为 c = np.random.rand(2,3) print(c,type(c)) # 生成形状为2*3的二维数组,注意这里不是((2,3)) samples1 = np.random.rand(1000) samples2 = np.random.rand(1000) plt.scatter(samples1,samples2) # 生成1000个均匀分布的样本值
运行结果:
0.45885369494340966 <class 'float'> [0.69046696 0.15681846 0.72039881 0.92133037] <class 'numpy.ndarray'> [[0.06343286 0.53977786 0.50854073] [0.14302969 0.49934197 0.27444025]] <class 'numpy.ndarray'>
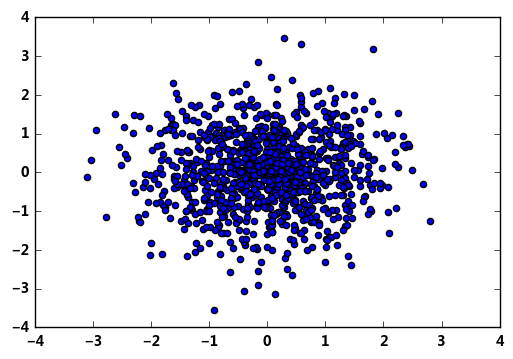
3.numpy.random.randn(d0, d1, ..., dn):生成一个浮点数或N维浮点数组 —— 正态分布
samples1 = np.random.randn(1000) samples2 = np.random.randn(1000) plt.scatter(samples1,samples2) # randn和rand的参数用法一样 # 生成1000个正太的样本值
4. 随机生成一个整数
# numpy.random.randint(low, high=None, size=None, dtype='l'):生成一个整数或N维整数数组 # 若high不为None时,取[low,high)之间随机整数,否则取值[0,low)之间随机整数,且high必须大于low # dtype参数:只能是int类型 print(np.random.randint(2)) # low=2:生成1个[0,2)之间随机整数 print(np.random.randint(2,size=5)) # low=2,size=5 :生成5个[0,2)之间随机整数 print(np.random.randint(2,6,size=5)) # low=2,high=6,size=5:生成5个[2,6)之间随机整数 print(np.random.randint(2,size=(2,3))) # low=2,size=(2,3):生成一个2x3整数数组,取数范围:[0,2)随机整数 print(np.random.randint(2,6,(2,3))) # low=2,high=6,size=(2,3):生成一个2*3整数数组,取值范围:[2,6)随机整数
运行结果:
1 [1 0 0 0 1] [2 5 3 5 5] [[0 0 0] [0 0 1]] [[5 2 3] [2 5 3]]
5.使程序每次运行生成的随机数是相同的——随机数种子
# 随机种子 # 计算机实现的随机数生成通常为伪随机数生成器,为了使得具备随机性的代码最终的结果可复现,需要设置相同的种子值 rng = np.random.RandomState(1) #1为种子,种子不一样,生成的随机数也不一样,但是对每个种子来说,每次运行所生成的随机数是相同的 xtrain = 10 * rng.rand(30) ytrain = 8 + 4 * xtrain + rng.rand(30) # np.random.RandomState → 随机数种子,对于一个随机数发生器,只要该种子(seed)相同,产生的随机数序列就是相同的 # 生成随机数据x与y # 样本关系:y = 8 + 4*x fig = plt.figure(figsize =(12,3)) ax1 = fig.add_subplot(1,2,1) plt.scatter(xtrain,ytrain,marker = '.',color = 'k') plt.grid() plt.title('样本数据散点图') # 生成散点图
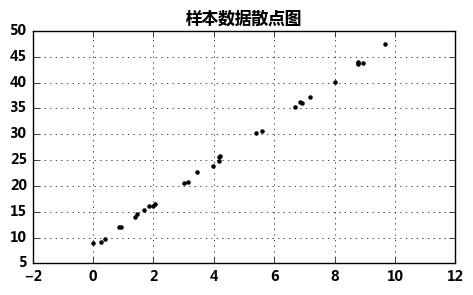
测试:
import numpy as np rng2 = np.random.RandomState(1) rng2.randn(3,2)
运行:
array([[ 1.62434536, -0.61175641], [-0.52817175, -1.07296862], [ 0.86540763, -2.3015387 ]])
练习1:
请按照要求创建数组ar,再将ar[:2,:2]的值改为[0,1)的随机数

import numpy as np ar = np.arange(25.0).reshape(5,5) print(ar) ar[:2,:2] = np.random.rand(2,2) print(ar)
运行结果:
[[ 0.83651399 0.69131755 2. 3. 4. ] [ 0.78268105 0.242201 7. 8. 9. ] [10. 11. 12. 13. 14. ] [15. 16. 17. 18. 19. ] [20. 21. 22. 23. 24. ]]