目录:
一、概述
二、awk基本语法格式
三、awk基本操作
四、awk条件及循环语句
五、awk函数
六、awk演示示例(源自于man手册)
一、概述
1. 产品概述:
awk是一种编程语言,用于在linux/unix下对文本和数据进行扫描与处理。数据可以来自标准输入、文件、管道。
awk分别代表其作者姓氏的第一个字母。因为它的作者是三个人,分别是Alfred Aho、Peter Weinberger、Brian Kernighan。
实际上awk有很多种版本,如:awk、nawk、mawk、gawk、MKS awk、tawk... 这其中有开源产品也有商业产品。
目前在Linux中常用的awk编译器版本有mawk,gawk,其中以RedHat为代表使用的是gawk,以Ubuntu为代表使用的是mawk。
gawk是GNU Project 的awk解释器的开源代码实现。
本文将以gawk作为讲解工具。
2. 原理:
1). awk逐行扫描文件,从第一行到最后一行,寻找匹配特定模式的行,并在这些行上进行你想要的操作。
2). awk基本结构包括模式匹配(用于找到要处理的行)和处理过程(即处理动作)。
pattern {action}
| # 提示:awk读取文件内容的每一行时,将对比改行是否与给定的模式相匹配,如果匹配则执行处理过程,否则对该行不做任何处理。 如果没有指定处理脚本,则把匹配的行显示到标准输出,即默认处理动作是print打印行; 如果没有指定模式匹配,则默认匹配所有数据。 |
3). awk有两个特殊的模式:BEGIN和END,他们被放置在没有读取任何数据之前以及在所有数据读取完成以后执行。
3. awk流程图:
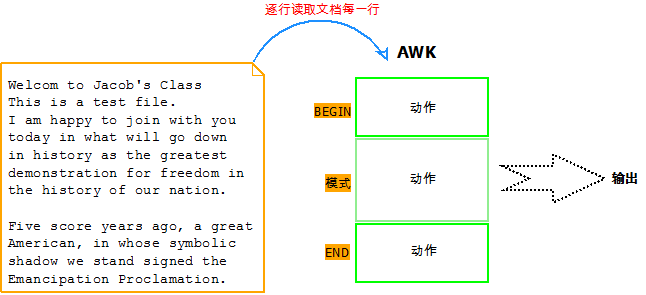
| 提示:awk将文件中的每一行当作一条记录,并将记录分割为若干字段,默认以空格或制表符为分隔符。 |
如This is a test file. 将分割为5个字段,awk可以对这5个字段进行分别处理。
二、awk基本语法格式
1. 格式:
gawk [ POSIX or GNU style options ] -f program-file [ -- ] file ...注释:POSIX or GNU style options表示gawk支持POSIX以及GNU两种选项;-f后接脚本文件;file表示准备处理的文档名称。
2. gawk支持以下选项:
-F fs
--field-separator fs
指定以fs作为输入行的分隔符(默认分隔符为空格或制表符)
-v var=val
--assign var=val
在执行处理过程以前,设置一个变量var值为val
-f program-file
--file program-file
从脚本文件中读取AWK指令,以取代在命令参数中输入处理脚本
-W compat
-W traditional
--compat
--traditional
使用兼容模式运行awk,GNU扩展选项将被忽略
-W copyleft
-W copyright
--copyleft
--copyright
输出简短的GNU版权信息
-W dump-variables[=file]
--dump-variables[=file]
打印全局变量(变量名、类型、值)到文件中,如果没有提供文件名,则自动输出至名为dump-variables的文件中。
示例:
awk -W dump-variables=out.txt 'x=1 {print x}' test.txt -W exec file
--exec file
类似于-f选项,但脚本文件需要以#!开头;另外命令行的变量将不再生效
-W help
-W usage
--help
--usage
显示各个选项的简短描述
3. awk程序结构
一个awk程序包含一系列的 模式 {动作指令} 或是函数定义。
模式可以是:
BEGIN
END
表达式
表达式,表达式
动作指令需要以{}引起来
4. 简单示例:
awk '/^$/ {print "Blank line}' test.txt备注:/^$/通过正则表达式匹配空白行,动作为打印Blank line;即test.txt如有N个空白行,awk将在屏幕打印N个Blank line。
awk '/HOSTNAME/' /etc/sysconfig/network备注:打印包含主机名的行,因为没有指定动作指令,默认动作为打印。
cat awk.sh'/^$/ {print "Blank line}'
awk -f awk.sh test.txt 备注:提前编辑一个awk脚本再通过-f选项调用该脚本。
三、awk基本操作
1. 记录与字段
awk一次从文件中读取一条记录,并将记录存储在字段变量$0中。记录被分割为字段并存储在$1,$2 ..., $NF中(默认使用空格或制表符为分隔符)。
内建变量NF为记录的字段个数
示例:
echo hello the world | awk '{print $1,$2,$3}'备注:读取输入行并输出第一个字段,第二个字段,第三个字段。
echo hello the world | awk '{print $0}'备注:读取输入行并输出该行。
echo hello the world | awk '{print NF}'备注:读取输入行并输出该行的字段个数:3个字段。
echo hello the world | awk '{print $NF}'备注:读取输入行并输出该行的第三个字段,因为NF为3,所以$NF等同于取行的最后一个字段。
2. 字段分隔符
默认awk读取数据以空格或制表符作为分隔符,但可以通过-F或FS(field separator)变量来改变分隔符。
示例:
awk -F: '{print $1}' /etc/passwdawk 'BEGIN {FS = ":"} {print $1}' /etc/passwd 备注:以上两个示例均将字段的分隔符改冒号(:),即以冒号为分隔符打印passwd文件的第一个字段(帐号名称)。
注意:如果使用FS改变分隔符的话,需要在BEGIN处定义FS,因为在读取第一行前就需要改变字段分隔符。
进阶:指定多个字段分隔符(文档内容为:hello the:word,!)
echo 'hello the:word,!' | awk 'BEGIN {FS="[:, ]"} {print $1,$2,$3,$4}'3. 内置变量
以下为awk内置变量:
ARGC 命令行参数个数
FILENAME 当前输入文档的名称
FNR 当前输入文档的当前记录编号,尤其当有多个输入文档时有用
NR 输入流的当前记录编号
NF 当前记录的字段个数
FS 字段分隔符
OFS 输出字段分隔符,默认为空格
ORS 输出记录分隔符,默认为换行符
RS 输入记录分隔符,默认为换行符
示例:
cat test1.txtThis is a test file. Welcome to Jacob's Class.
cat test2.txtHello the world. Wow! I'm overwhelmed. Ask for more.
输出当前文档的当前行编号,第一个文件两行,第二个文件三行:
awk '{print FNR}' test1.txt test2.txt1 2 1 2 3
awk将两个文档作为一个整体的输入流,通过NR输入当前行编号:
awk '{print NR}' test1.txt test2.txt1 2 3 4 5
test1.txt文档的第一行有5个字段,第二行有4个字段:
awk '{print NF}' test1.txt5 4
-
awk 'BEGIN {FS = ":"} {print $1}' /etc/passwd
-
awk '{print $1,$2,$3}' test1.txt
备注:默认print输出时,各参数将的输出分隔符默认为空格,所以输出内容如下。
This is a Welcome to Jacob's
awk 'BEGIN {OFS="-"} {print $1,$2,$3}' test1.txt备注:通过OFS将输出分隔符设置为"-",这个print在输出第一、二、三个字段时,中间的分隔符为"-",结果如下:
This-is-a Welcome-to-Jacob's
cat test3.txtmail from: tomcat@gmail.com subject:hello date:2012-07-12 17:00 content:Hello, The world. mail from: jerry@gmail.com subject:congregation date:2012-07-12 08:31 content:Congregation to you. mail from: jacob@gmail.com subject:Test date:2012-07-12 10:20 content:This is a test mail.
awk 'BEGIN {FS="
"; RS=""} {print $3}' test3.txt 备注:读取输入数据,以空白行为记录分隔符,即第一个空白行前的内容为第一个记录,第一个记录中字段分隔符为换行符。
以上awk的效果为打印所有的邮件时间,即每个记录的第三个字段。
4. 表达式与操作符
表达式是由变量、常量、函数、正则表达式、操作符组成,awk中变量有字符变量和数字变量。如果在awk中定义的变量没有初始化,则初始值为空字串或0。
注意:字符操作时一定记得需要加引号
1) 变量定义示例:
-
a="welcome to beijing"
-
b=12
2) 操作符(awk操作符与C语言类似)
+ 加
- 减
* 乘
/ 除
% 取余
^ 幂运算
++ 自加1
-- 自减1
+= 相加后赋值给变量(x+=9等同于x=x+9)
-= 相减后赋值给变量(x-=9等同于x=x-9)
*= 相乘后赋值给变量(x*=9等同于x=x*9)
/= 相除后赋值给变量(x/=9等同于x=x/9)
> 大于
< 小于
>= 大于等于
<= 小于等于
== 等于
!= 不等于
~ 匹配
!~ 不匹配
&& 与
|| 或
操作符简单示例:
echo "test" | awk 'x=2 {print x+3}'echo "test" | awk 'x=2,y=3 {print x*2, y*3}'统计所有空白行:
awk '/^$/ {print x+=1}' test.txt打印总空白行个数:
awk '/^$/ {x+=1} END {print x}' test.txt打印root的ID号:
awk -F: '$1~/root/ {print $3}' /etc/passwd列出计算机中ID号大于500的用户名:
awk -F: '$3>500 {print $1}' /etc/passwd四、awk条件及循环语句
1. IF条件判断格式:
if (表达式)
动作1
else
动作2
或者if (表达式) 动作1;else 动作2
说明:如果表达式的判断结果为真则执行动作1,否则执行动作2。
示例:(判断boot分区可用容量小于20M时报警,否则显示OK)
df | grep "boot" | awk '{if($4<20000) print "Alart"; else print "OK"}'
2. 循环
while (条件)
动作
x=1
while (i < 10) {
print $i
}
示例:
awk 'i=1 {} BEGIN { while (i<=10) {++i; print i}}' test.txt do
动作
while (条件)
示例:
awk 'BEGIN { do {++x;print x} while (x<=10)}' test.txt for (变量;条件;计数器)
动作
示例:
for (i=1;i<=10;i++)
print i
awk 'BEGIN {for(i=1;i<=10;i++) print i}' test.txtawk 'BEGIN {for(i=10;i>=1;i--) print i}' test.txt
说明:因为以上循环语句使用的awk均使用的BEGIN模式,所以输入文档可以为任意文档(无关紧要)。
3. Break与Continue
break 跳出循环
continue 终止当前循环
示例:
-
for (i=1; i<=10;i++) {
-
if (i=5)
-
continue
-
print i
-
}
说明:打印1-4,6-10
-
for (i=1; i<=10;i++) {
-
if (i=5)
-
break
-
print i
-
}
说明:仅打印1-4
五、函数
1. rand () 产生0-1之间的浮动类型的随机数
备注:rand产生随机数时需要通过srand()设置一个参数,否则单独的rand()每次删除的随机数都是一样的。
示例:
awk 'BEGIN {print rand(); srand(); print srand()}' test.txt
2. gsub(x,y,z)
在字串z中使用字串y替换与正则表达式x相匹配的所有字串,z默认为$0
sub(x,y,z) 在字串z中使用字串y替换与正则表达式x相匹配的第一个字串,z默认为$0
示例:
将passwd每行中所有的root修改为jacob显示至屏幕
awk -F: 'gsub(/root/,"jacob",$0) {print $0}' /etc/passwd将passwd每行中第一个root修改为jacob显示至屏幕
awk -F: 'sub(/root/,"jacob",$0) {print $0}' /etc/passwd sub相当于sed中的s///,gsub相当于sed中的s///g。
3. length(z)
返回字串z的长度
示例:显示test.txt文档每行的字符长度
awk '{print length()}' test.txt
4. gentline
从输入中读取下一行内容
示例:
df -h- Filesystem Size Used Avail Use% Mounted on
- /dev/mapper/VolGroup00-LogVol00
- 19G 3.6G 15G 21% /
- /dev/sda1 99M 14M 81M 15% /boot
- tmpfs 141M 0 141M 0% /dev/shm
- none 140M 104K 140M 1% /var/lib/xenstored
| 说明:从以上命令的输出结果可以看出,分区的剩余容量显示在第4列,但唯独/根分区的记录显示在了两行;我们需要判断当记录的字段个数为1时,读取下一行,并将该行的第3列显示至屏幕。 |
df -h | awk '{if(NF==1) {getline; print $3}; if(NF==6) print $4}'df -h | awk 'BEGIN {print "Disk Free:"} {if(NF==1) {getline; print $3}; if(NF==6) print $4}'六、awk演示示例(源自于man手册)
1. emulate cat:模拟cat程序
{ print }
2. emulate wc:模拟wc程序,统计行数、单词数、字符数
-
{ chars += length($0) + 1 # add one for the
-
words += NF
-
}
-
END{ print NR, words, chars }
3. sum the second field of every record based on the first field. 根据第一列的内容统计第二列的数据
-
$1 ~ /credit|gain/ { sum += $2 }
-
$1 ~ /debit|loss/ { sum -= $2 }
-
END { print sum }
4. Print and sort the login names of all users: 显示计算机帐号用户名并排序
-
BEGIN { FS = ":" }
-
{ print $1 | "sort" }