不管是在测试中还是面试中,总是会遇到这种场景,某个数据表中的数据存在重复,要求删除重复数据时,保留一行。接下来,我给大家演示一下,如何写出符合要求的SQL语句。
1、首先,创建一个数据表SC,建表语句如下:
CREATE TABLE sc (
id INT PRIMARY KEY auto_increment,
SNO VARCHAR(3) NOT NULL,
CNO VARCHAR(5) NOT NULL,
DEGREE NUMERIC(10, 1) NOT NULL
);
2、接着插入一些数据,这些数据中有一部分是重复的。
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (103,'3-245',86);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (105,'3-245',75);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (109,'3-245',68);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (103,'3-245',86);
INSERT INTO SCORE(SNO,CNO,DEGREE)VALUES (103,'3-245',86);
3、查询SC表中的重复数据
SELECT SNO,CNO ,COUNT(*)
FROM sc
GROUP BY sno,cno
HAVING COUNT(*)>1;
显示结果如下:

4、删除重复数据,写了如下SQL语句:
DELETE FROM sc WHERE sno in(
SELECT SNO
FROM sc
GROUP BY sno,cno
HAVING COUNT(*)>1);
运行时,发现报错,具体报错信息如下:
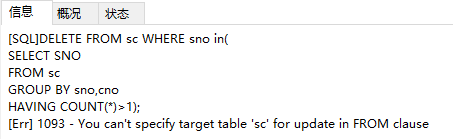
也就是说,在同一张表上不能在统计查询的时候,进行删除操作。
那么,我就想到了命名别名的方式,避免这个问题,于是写了如下SQL
DELETE FROM sc
WHERE sno in(SELECT sno FROM (SELECT sno
FROM sc
GROUP BY sno,cno
HAVING COUNT(*)>1)as a);
运行之后,重复数据删除了,但是全部删除了,没有保留数据,而我的本意是在删除重复数据的时候,希望保留一条记录的,于是在上面的SQL语句基础上做了完善,具体SQL语句如下:
DELETE FROM sc
WHERE sno in(SELECT sno FROM (SELECT sno
FROM sc
GROUP BY sno,cno
HAVING COUNT(*)>1)as a)
and ID not in(SELECT MIN(id)FROM
(SELECT id FROM sc GROUP BY sno,cno
HAVING COUNT(sno)>1)b );
这么写了SQL之后,我的问题完美的解决了,删除了重复数据的同时,保留了一条记录。