- 概念
- 生产者
- 消费者
- 面试题
- kafka设计
- 请说明什么是Apache Kafka?
- 请说明什么是传统的消息传递方法?
- 请说明Kafka相对传统技术有什么优势?
- Kafka与传统MQ消息系统之间有三个关键区别
- 说说Kafka的使用场景?
- 使用Kafka有什么优点和缺点?
- 谈谈Kafka吞吐量为何如此高?
- zookeeper对于kafka的作用
- 什么是ISR伸缩
- Kafka中是怎么体现消息顺序性的?
- Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
- Kafka为什么不支持读写分离?
- 是什么确保了Kafka中服务器的负载平衡?
- Kafka判断一个节点是否还活着有那两个条件?
- kafka的高可用机制是什么?
- Apache Kafka是分布式流处理平台吗?如果是,你能用它做什么?
- Apache Kafka的缺陷
- 主题、分区、副本
- 当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?
- topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
- topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
- 创建topic时如何选择合适的分区数?
- Kafka目前有哪些内部topic,它们都有什么特征?各自的作用又是什么?
- __consumer_offsets是做什么用的?
- 优先副本是什么?它有什么特殊的作用?
- Kafka有哪几处地方有分区分配的概念?简述大致的过程及原理
- 失效副本是指什么?有哪些应对措施?
- 多副本下,各个副本中的 HW和 LEO的演变过程
- 副本和ISR扮演什么角色?
- 解释如何减少ISR中的扰动?broker什么时候离开ISR?
- Kafka为什么需要复制?
- 如果副本在ISR中停留了很长时间表明什么?
- 请说明如果首选的副本不在ISR中会发生什么?
- Kafka创建Topic时如何将分区放置到不同的Broker中
- Kafka新建的分区会在哪个目录下创建
- partition的数据如何保存到硬盘
- 日志
- 生产者
- 消费者
- 消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1?
- 有哪些情形会造成重复消费?
- 哪些情景下会造成消息丢失?
- KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?
- 简述消费者与消费组之间的关系
- Kafka的旧版Scala的消费者客户端的设计有什么缺陷?
- “消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果正确,那么有没有什么hack的手段?
- 解释Kafka的用户如何消费信息?
- Kafa consumer是否可以消费指定分区消息?
- consumer 是推还是拉?
- 什么是消费者组?
- 讲讲kafka维护消费状态跟踪的方法
- 消费者如何不自动提交偏移量,由应用提交?
- 消费者故障,出现活锁问题如何解决?
- 如何控制消费的位置?
- kafka 分布式(不是单机)的情况下,如何保证消息的顺序消费?
- rebalance
- 事务
- kafka进阶
- 解释如何提高远程用户的吞吐量?
- 解释一下,在数据制作过程中,你如何能从Kafka得到准确的信息?
- 聊一聊你对Kafka底层存储的理解
- 聊一聊Kafka的延时操作的原理
- 聊一聊Kafka控制器的作用
- Kafka的缓冲池满了怎么办?
- Kafka在什么情况下会出现消息丢失?
- 能说一下leader选举过程吗
- 分区Leader选举策略有几种?
- Kafka能手动删除消息吗?
- Kafka的哪些场景中使用了零拷贝(Zero Copy)?
- 如何调优Kafka?
- Controller发生网络分区(Network Partitioning)时,Kafka会怎么样?
- Java Consumer为什么采用单线程来获取消息?
- 简述Follower副本消息同步的完整流程
- 消费者负载均衡策略
- 讲一下主从同步?
- 如何设置Kafka能接收的最大消息的大小?
- Broker的Heap Size如何设置?
- 如何估算Kafka集群的机器数量?
- Leader总是-1,怎么破?
- Kafka在可靠性方面做了哪些改进?(HW, LeaderEpoch)
- Kafka中的延迟队列怎么实现
- Kafka中怎么实现死信队列和重试队列?
- Kafka中怎么做消息审计?
- Kafka中怎么做消息轨迹?
- 怎么计算Lag?(注意read_uncommitted和read_committed状态下的不同)
- Kafka有哪些指标需要着重关注?
- 如何配置Kafka的机器数据量、副本数和日志保存时间
- Kafka中数据量计算及硬盘大小确定
- Kafka消息数据积压,Kafka消费能力不足怎么处理?
- Kafka单条日志传输大小
- Kafka的分区分配策略
- Kafka中有那些配置参数比较有意思?聊一聊你的看法
- Kafka中有那些命名比较有意思?聊一聊你的看法
- Kafka有哪些指标需要着重关注?
- kafka设计
概念
Kafka基础概念
- broker:Kafka 服务器,负责消息存储和转发
- topic:消息类别,Kafka 按照 topic 来分类消息
- partition:topic 的分区,一个 topic 可以包含多个 partition,topic 消息保存在各个partition 上
- offset:消息在日志中的位置,可以理解是消息在 partition 上的偏移量,也是代表该消息的唯一序号
- Producer:消息生产者
- Consumer:消息消费者
- Consumer Group:消费者分组,每个 Consumer 必须属于一个 group
- Zookeeper:保存着集群 broker、topic、partition 等 meta 数据;另外,还负责 broker 故障发现,partition leader 选举,负载均衡等功能
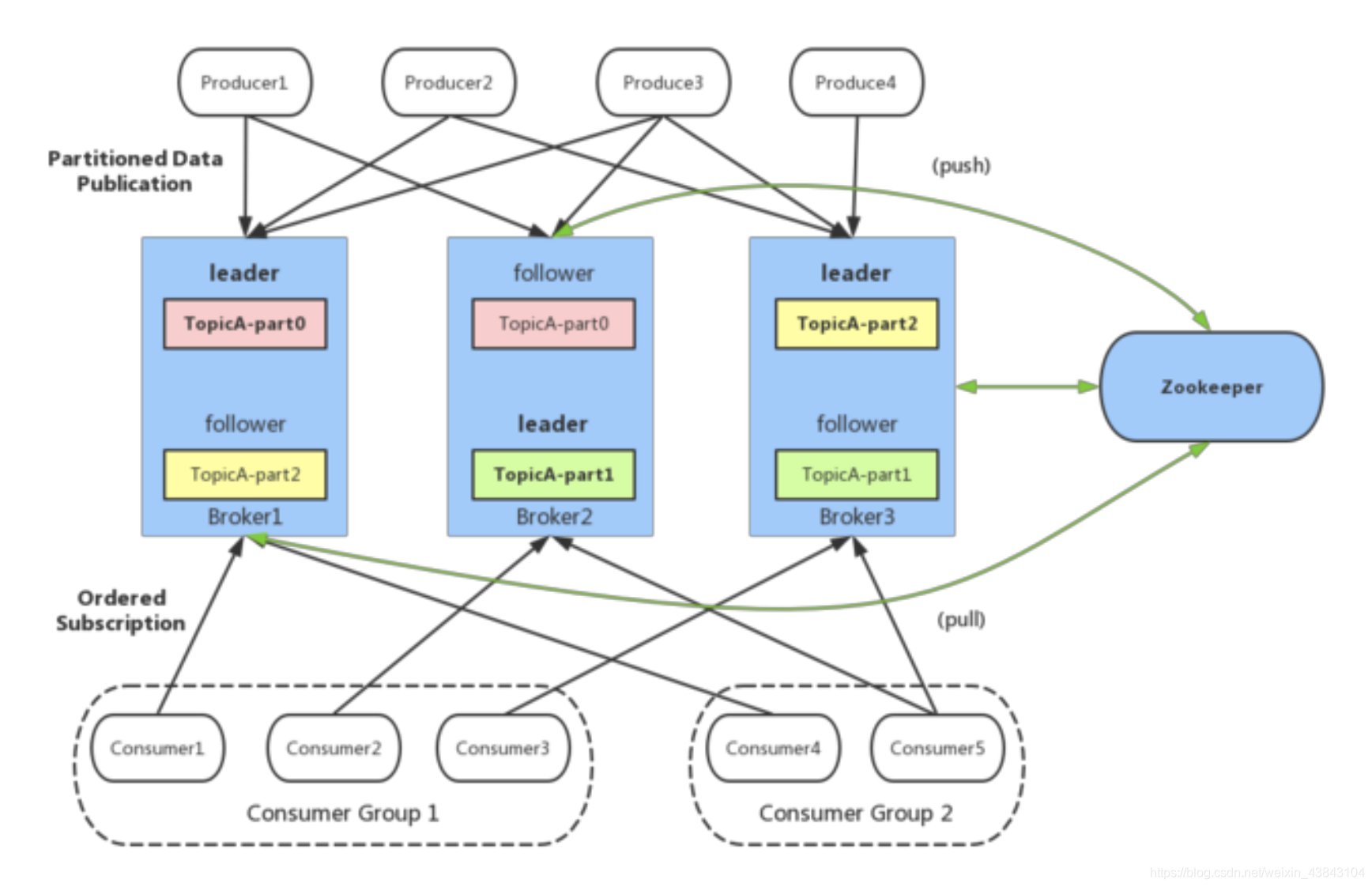
分区和副本:
副本(replica):增加副本数量提升容灾能力,leader副本负责读写请求,follower副本只负责与leader副本消息同步

LEO、LSO、AR、ISR、HW:
- HW(High Watermark): 消费者只能拉取到这个offset之前的消息
- LW(Low Watermark): 低水位,代表 AR 集合中最小的 logStartOffset 值。
- LEO(Log End Offset):标志当前日志文件中下一条待写入消息的offset
- LSO(Log Stable Offset):这是Kafka事务的概念。如果你没有使用到事务,那么这个值不存在(其实也不是不存在,只是设置成一个无意义的值)。该值控制了事务型消费者能够看到的消息范围。它经常与Log Start Offset,即日志起始位移值相混淆,因为有些人将后者缩写成LSO,这是不对的。在Kafka中,LSO就是指代Log Stable Offset
- AR(Assigned Replicas):AR是主题被创建后,分区创建时被分配的副本集合,副本个数由副本因子决定。
- ISR(In-Sync Replicas):Kafka中特别重要的概念,指代的是AR中那些与Leader保持同步的副本集合。在AR中的副本可能不在ISR中,但Leader副本天然就包含在ISR中。

(https://blog.csdn.net/u013256816/article/details/88939070)
命令行
启动
bin/kafka-server-start.sh -daemon config/server.properties
创建主题
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --create --topic topic-demo --replication-factor 3 --partitions 4
查看主题
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --describe --topic topic-demo
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --list
生产者
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-demo
消费者
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-demo
Kafka 数据存储设计
- partition 的数据文件(offset,MessageSize,data)
partition 中的每条 Message 包含了以下三个属性:offset,MessageSize,data,其中 offset 表示 Message 在这个 partition 中的偏移量,offset 不是该 Message 在 partition 数据文件中的实际存储位置,而是逻辑上一个值,它唯一确定了 partition 中的一条 Message,可以认为 offset 是partition 中 Message 的 id;MessageSize 表示消息内容 data 的大小;data 为 Message 的具体内容。
- 数据文件分段 segment(顺序读写、分段命令、二分查找)
partition 物理上由多个 segment 文件组成,每个 segment 大小相等,顺序读写。每个 segment数据文件以该段中最小的 offset 命名,文件扩展名为.log。这样在查找指定 offset 的 Message 的时候,用二分查找就可以定位到该 Message 在哪个 segment 数据文件中
- 数据文件索引(分段索引、稀疏存储)
Kafka 为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。index 文件中并没有为数据文件中的每条 Message 建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。

kafka在zookeeper中存储结构

生产者
生产者设计
Kafka生产者客户端中使用了2个线程,主线程和Sender线程,其中:
- 主线程负责创建消息,然后通过分区器、序列化器、拦截器作用之后缓存到累加器RecordAccumulator中。
- Sender线程负责将RecordAccumulator中消息发送到kafka中.
RecordAccumulator主要用来缓存消息,以便Sender线程可以批量发送,进而减少网络传输的资源消耗以提升性能(可由buffer.memory参数配置,默认32MB)
主线程中发送过来消息都会被追加到RecordAccumulator的某个双端队列中(Deque),在RecordAccumulator的内部为每个分区都维护一个双端队列,队列内容就是ProducerBatch。

- 负载均衡(partition 会均衡分布到不同 broker 上)
由于消息 topic 由多个 partition 组成,且 partition 会均衡分布到不同 broker 上,因此,为了有效利用 broker 集群的性能,提高消息的吞吐量,producer 可以通过随机或者 hash 等方式,将消息平均发送到多个 partition 上,以实现负载均衡。

- 批量发送
是提高消息吞吐量重要的方式,Producer 端可以在内存中合并多条消息后,以一次请求的方式发送了批量的消息给 broker,从而大大减少 broker 存储消息的 IO 操作次数。但也一定程度上影响了消息的实时性,相当于以时延代价,换取更好的吞吐量
- 压缩
Producer 端可以通过 GZIP 或 Snappy 格式对消息集合进行压缩。Producer 端进行压缩之后,在Consumer 端需进行解压。压缩的好处就是减少传输的数据量,减轻对网络传输的压力,在对大数据处理上,瓶颈往往体现在网络上而不是 CPU(压缩和解压会耗掉部分 CPU 资源)
消费者
消费者设计
消费者组:
同一 Consumer Group 中的多个 Consumer 实例,不能同时消费同一个 partition中同一消息,等效于队列模式。partition 内消息是有序的,Consumer 通过 pull 方式消费消息。Kafka 不删除已消费的消息对于 partition,顺序读写磁盘数据,以时间复杂度 O(1)方式提供消息持久化能力。

面试题
kafka设计
请说明什么是Apache Kafka?
Apache Kafka是由Apache开发的一种发布订阅消息系统,它是一个分布式的、分区的和可复制的提交日志服务。
请说明什么是传统的消息传递方法?
传统的消息传递方法包括两种:
- 排队:在队列中,一组用户可以从服务器中读取消息,每条消息都发送给其中一个人
- 发布-订阅:在这个模型中,消息被广播给所有的用户。
请说明Kafka相对传统技术有什么优势?
- 快速:单一的Kafka代理可以处理成千上万的客户端,每秒处理数兆字节的读写操作
- 可伸缩:在一组机器上对数据进行分区
- 和简化,以支持更大的数据
- 持久:消息是持久性的,并在集群中进
- 行复制,以防止数据丢失。
- 设计:它提供了容错保证和持久性
Kafka与传统MQ消息系统之间有三个关键区别
- Kafka持久化日志,这些日志可以被重复读取和无限期保留
- Kafka是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过复制数据提升容错能力和高可用性
- Kafka支持实时的流式处理
- (消息顺序性保障和回溯消费)
说说Kafka的使用场景?
- 异步处理
将一些实时性要求不是很强的业务异步处理,起到缓冲的作用,一定程度上也会避免因为有些消费者处理的太慢或者网络问题导致的通讯等待太久,因而导致的单个服务崩溃,甚至产生多个服务间的雪崩效应;
- 应用解耦
消息队列将消息生产者和消费者分离开来,可以实现应用解耦
- 流量削峰
可以通过在应用前端采用消息队列来接收请求,可以达到削峰的目的:请求超过队列长度直接不处理,重定向至错误页面。类似于网关限流的作用
- 冗余存储
消息队列把数据进行持久化,直到它们已经被完全处理,通过这一方式规避了数据丢失风险
- 消息通讯
可以作为基本的消息通讯,比如聊天室等工具的使用
实际使用场景:
- 日志信息收集记录
Kafka使用最多的场景,就是用它与FileBeats和ELK组成典型的日志收集、分析处理以及展示的框架。FileBeats+Kafka+ELK集群架构。Kafka在框架中,作为消息缓冲队列FileBeats先将数据传递给消息队列,Logstash server(二级Logstash)拉取消息队列中的数据,进行过滤和分析,然后将数据传递给Elasticsearch进行存储,最后,再由Kibana将日志和数据呈现给用户
由于引入了Kafka缓冲机制,即使远端Logstash server因故障停止运行,数据也不会丢失,可靠性得到了大大的提升
- 用户轨迹跟踪
kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等操作,这些活动信息被各个服务器发布到kafka的topic中,然后消费者通过订阅这些topic来做实时的监控分析,当然也可以保存到数据库
- 运营指标
kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告
- 流式处理
比如spark streaming和storm
使用Kafka有什么优点和缺点?
优点:
- 支持跨数据中心的消息复制;
- 高吞吐量:我们在Kafka中不需要任何大型硬件,因为它能够处理高速和大容量数据。此外,它还可以支持每秒数千条消息的消息吞吐量。(topic数量对吞吐量的影响:topic从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,kafka尽量保证topic数量不要过多。如果要支撑大规模topic,需要增加更多的机器资源)
- 低延迟:ms级;
- 可用性(容错性):非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用;
- 消息可靠性(容错性、持久性):经过参数优化配置,消息可以做到0丢失;
- 功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用。
- 可扩展性:kafka可以扩展,而不需要通过添加额外的节点而在运行中造成任何停机。
缺点:
- 由于是批量发送,数据并非真正的实时; 仅支持统一分区内消息有序,无法实现全局消息有序;
- 有可能消息重复消费;
- 依赖zookeeper进行元数据管理,等等。
谈谈Kafka吞吐量为何如此高?
多分区、batch sends kafka Reator 网络模型、pagecaches sendfile 零拷贝、数据 、压缩
- 顺序读写
Kafka是将消息记录持久化到本地磁盘中的,有的人会认为磁盘读写性能差,可能会对Kafka性能如何保证提岀质疑。实际上不管是内存还是磁盘,快或慢关键在于寻址的方式,磁盘分为顺序读写与随机读写,内存也一样分为顺序读写与随机读写。基于磁盘的随机读写确实很慢,但磁盘的顺序读写性能却很高,一般而言要高岀磁盘随机读写三个数量级,一些情况下磁盘顺序读写性能甚至要高于内存随机读写。
磁盘的顺序读写是磁盘使用模式中最有规律的,并且操作系统也对这种模式做了大量优化,Kafka就是使用了磁盘顺序读写来提升的性能。Kafka的message是不断追加到本地磁盘文件末尾的,而不是随机的写入,这使得Kafka写入吞吐量得到了显著提升。
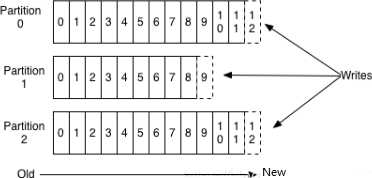
上图就展示了 Kafka是如何写入数据的,每一个Partition其实都是一个文件,收到消息后Kafka会把数据插入到文件末尾(虚框部分)。
这种方法有一个缺陷一一没有办法删除数据,所以Kafka是不会删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个 offset用来表示读取到了第几条数据。
- 零拷贝
零拷贝就是一种避免CPU将数据从一块存储拷贝到另外一块存储的技术。
linux操作系统“零拷贝”机制使用了send句e方法,允许操作系统将数据从 PageCache直接发送到网络,只需要最后一步的copy操作将数据复制到NIC缓冲区,这样避免重新复制数据。示意图如下:

通过这种“零拷贝”的机制,Page Cache结合sendfile方法,Kafka消费端的性 能也大幅提升。这也是为什么有时候消费端在不断消费数据时,我们并没有看到磁盘io比较高,此刻正是操作系统缓存在提供数据
- 分区分段+索引
Kafka的message是按topic分类存储的,topic中的数据又是按照一个一个的partition即分区存储到不同broker节点。每个partition对应了操作系统上的一个文件夹,partition实际上又是按照segment分段存储的。这也非常符合分布式系统分区分桶的设计思想。
通过这种分区分段的设计,Kafka的message消息实际上是分布式存储在一个一个小的segment中的,每次文件操作也是直接操作的segment。为了进一步的查询优化,Kafka又默认为分段后的数据文件建立了索引文件,就是文件系统上 的.index文件。这种分区分段+索引的设计,不仅提升了数据读取的效率,同时也 提高了数据操作的并行度。
- 批量读写
Kafka数据读写也是批量的而不是单条的。
在向Kafka写入数据时,可以启用批次写入,这样可以避免在网络上频繁传输单个消息带来的延迟和带宽开销。假设网络带宽为1OMB/S,—次性传输1OMB的消息比传输1KB的消息1OOOO万次显然要快得多。
- 批量压缩
如果每个消息都压缩,但是压缩率相对很低,所以Kafka使用了批量压缩,即将多个消息一起压缩而不是单个消息压缩
Kafka允许使用递归的消息集合,批量的消息可以通过压缩的形式传输并且在日志中也可以保持压缩格式,直到被消费者解压缩
Kafka支持多种压缩协议,包括Gzip和Snappy压缩协议
Kafka把所有的消息都变成一个批量的文件,并且进行合理的批量压缩,减少网络IO损耗,通过mmap提高I/O速度,写入数据的时候由于单个Partion是末尾添加,所以速度最优;读取数据的时候配合sendfile直接暴力输岀。
zookeeper对于kafka的作用
目前,Kafka使用ZooKeeper存放集群元数据、成员管理、Controller选举,以及其他一些管理类任务。之后,等KIP-500提案完成后,Kafka将完全不再依赖于ZooKeeper。KIP-500 思想,是使用社区自研的基于Raft的共识算法,替代ZooKeeper,实现Controller自选举。
- 存放元数据:是指主题分区的所有数据都保存在 ZooKeeper中,且以它保存的数据为权威,其他 “人” 都要与它保持对齐。
- 成员管理:是指 Broker 节点的注册、注销以及属性变更,等等。
- Controller选举:是指选举集群 Controller,而其他管理类任务包括但不限于主题删除、参数配置等。
Zookeeper主要用于在集群中不同节点之间进行通信
在Kafka中,它被用于提交偏移量,因此如果节点在任何情况下都失败了,它都可以从之前提交的偏移量中获取
Kafka的数据会存储在zookeeper上。包括broker和消费者consumer的信息. 其中:
- broker信息:包含各个broker的服务器信息、Topic信息
- 消费者信息:主要存储每个消费者消费的topic的offset的值
除此之外,它还执行其他活动,如: leader检测、分布式同步 、配置管理、 识别新节点何时离开或连接、集群、节点实时状态等等。
什么是ISR伸缩
Leader副本负责维护和跟踪ISR集合中所有的follower副本的滞后状态,当follower副本落后太多或者失效时,leader副本会把它从ISR集合中剔除。如果OSR集合中follower副本追上了Leader副本,之后再ISR集合中的副本才有资格被选举为leader,而在OSR集合中的副本则没有机会。
Kafka在启动的时候会开启两个与ISR相关的定时任务,名称分别为“isr-expiration"和”isr-change-propagation".。isr-expiration任务会周期性的检测每个分区是否需要缩减其ISR集合。这个周期和“replica.lag.time.max.ms”参数有关。大小是这个参数一半。默认值为5000ms,当检测到ISR中有是失效的副本的时候,就会缩减ISR集合。如果某个分区的ISR集合发生变更,则会将变更后的数据记录到ZooKerper对应/brokers/topics//partition//state节点中
https://www.pianshen.com/article/39371363880/
Kafka中是怎么体现消息顺序性的?
每个分区内,每条消息都有一个offset,故Kafka只能保证分区内消息顺序有序,无法保证全局有序
- 生产者:通过分区的leader副本负责数据顺序写入,来保证消息顺序性
- 消费者:同一个分区内的消息只能被一个group里的一个消费者消费,保证分区内消费有序

Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
生产者中处理顺序是: 拦截器 > 序列化器 > 分区器
- 生产者拦截器:可以用来在消息发送前做一些准备工作,如过滤不符合要求的消息、修改消息内容等,也可以用来在发送回调逻辑前做一些定制化需求,如统计类工作
- 生产者序列化器:把对象转换成字节数组才能通过网络发送给kafka
- 生产者分区器:如果消息ProducerRecord指定了partition,就不需要分区器;若没有,就根据key计算partition值。
- 消费者拦截器:主要在消费到消息或提交消费位移进行一些定制化操作
- 消费者必须进行反序列化
Kafka为什么不支持读写分离?
这其实是分布式场景下的通用问题,因为我们知道CAP理论下,我们只能保证C(一致性)和A(可用性)取其一,如果支持读写分离,那其实对于一致性的要求可能就会有一定折扣,因为通常的场景下,副本之间都是通过同步来实现副本数据一致的,那同步过程中肯定会有时间的消耗,如果支持了读写分离,就意味着可能的数据不一致,或数据滞后。
Leader/Follower模型并没有规定Follower副本不可以对外提供读服务。很多框架都是允许这么做的,只是 Kafka最初为了避免不一致性的问题,而采用了让Leader统一提供服务的方式。
不过,自Kafka 2.4之后,Kafka提供了有限度的读写分离,也就是说,Follower副本能够对外提供读服务。
是什么确保了Kafka中服务器的负载平衡?
由于领导者的主要角色是执行分区的所有读写请求的任务,而追随者被动地复制领导者。因此,在领导者失败时,其中一个追随者接管了领导者的角色。基本上,整个过程可确保服务器的负载平衡。
Kafka判断一个节点是否还活着有那两个条件?
- 节点必须可以维护和ZooKeeper的连接,Zookeeper通过心 跳机制检查每个节点的连接
- 如果节点是个follower,他必须能及时的同步leader的写操作,延时不能太久
kafka的高可用机制是什么?
多副本冗余的高可用机制
producers broker和 consumer都会拥有多个
分区选举机制、消息确认机制
Apache Kafka是分布式流处理平台吗?如果是,你能用它做什么?
Kafka是一个流处理平台。它可以帮助:
- 轻松推送记录
- 可以存储大量记录,而不会出现任何存储问题
- 它还可以在记录进入时对其进行处理
Apache Kafka的缺陷
- 没有完整的监控工具集
- 消息调整的问题
- 不支持通配符主题选择
- 速度问题
主题、分区、副本
当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?
在执行完脚本之后,Kafka 会在 log.dir 或 log.dirs 参数所配置的目录下创建相应的主题分区,默认情况下这个目录为/tmp/kafka-logs/。
在 ZooKeeper 的/brokers/topics/目录下创建一个同名的实节点,该节点中记录了该主题的分区副本分配方案。示例如下:
[zk: localhost:2181/kafka(CONNECTED) 2] get /brokers/topics/topic-create
{"version":1,"partitions":{"2":[1,2],"1":[0,1],"3":[2,1],"0":[2,0]}}
topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
可以增加,使用 kafka-topics 脚本,结合 --alter 参数来增加某个主题的分区数,命令如下:
bin/kafka-topics.sh --bootstrap-server broker_host:port --alter --topic <topic_name> --partitions <新分区数>
当分区数增加时,就会触发订阅该主题的所有 Group 开启 Rebalance。
- 首先,Rebalance 过程对 Consumer Group 消费过程有极大的影响。在 Rebalance 过程中,所有 Consumer 实例都会停止消费,等待 Rebalance完成。这是 Rebalance 为人诟病的一个方面。
- 其次,目前 Rebalance 的设计是所有 Consumer实例共同参与,全部重新分配所有分区。其实更高效的做法是尽量减少分配方案的变动。
- 最后,Rebalance 实在是太慢了。
topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
不支持,因为删除的分区中的消息不好处理。
如果直接存储到现有分区的尾部,消息的时间戳就不会递增,如此对于 Spark、Flink这类需要消息时间戳(事件时间)的组件将会受到影响;如果分散插入现有的分区,那么在消息量很大的时候,内部的数据复制会占用很大的资源,而且在复制期间,此主题的可用性又如何得到保障?与此同时,顺序性问题、事务性问题,以及分区和副本的状态机切换问题都是不得不面对的。
创建topic时如何选择合适的分区数?
在 Kafka 中,性能与分区数有着必然的关系,在设定分区数时一般也需要考虑性能的因素。对不同的硬件而言,其对应的性能也会不太一样。
可以使用Kafka 本身提供的用于生产者性能测试的 kafka-producer- perf-test.sh 和用于消费者性能测试的 kafka-consumer-perf-test.sh来进行测试。
增加合适的分区数可以在一定程度上提升整体吞吐量,但超过对应的阈值之后吞吐量不升反降。如果应用对吞吐量有一定程度上的要求,则建议在投入生产环境之前对同款硬件资源做一个完备的吞吐量相关的测试,以找到合适的分区数阈值区间。
分区数的多少还会影响系统的可用性。如果分区数非常多,如果集群中的某个 broker节点宕机,那么就会有大量的分区需要同时进行 leader 角色切换,这个切换的过程会耗费一笔可观的时间,并且在这个时间窗口内这些分区也会变得不可用。
分区数越多也会让 Kafka的正常启动和关闭的耗时变得越长,与此同时,主题的分区数越多不仅会增加日志清理的耗时,而且在被删除时也会耗费更多的时间。
Kafka目前有哪些内部topic,它们都有什么特征?各自的作用又是什么?
- __consumer_offsets:作用是保存 Kafka 消费者的位移信息
- __transaction_state:用来存储事务日志消息
__consumer_offsets是做什么用的?
这是一个内部主题,主要用于存储消费者的偏移量,以及消费者的元数据信息(消费者实例,消费者id等等)
需要注意的是:Kafka的GroupCoordinator组件提供对该主题完整的管理功能,包括该主题的创建、写入、读取和Leader维护等。
优先副本是什么?它有什么特殊的作用?
所谓的优先副本是指在AR集合列表中的第一个副本。
理想情况下,优先副本就是该分区的leader 副本,所以也可以称之为 preferred leader。Kafka 要确保所有主题的优先副本在 Kafka 集群中均匀分布,这样就保证了所有分区的 leader 均衡分布。以此来促进集群的负载均衡,这一行为也可以称为“分区平衡”。
Kafka有哪几处地方有分区分配的概念?简述大致的过程及原理
在生产者、消费者和broker端都有分区分配
- 生产者的分区分配
如果消息ProducerRecord中指定了partition字段,那么就不需要分区器的作用,因为partition代表的就是所要发往的分区号。如果消息ProducerRecord中没有指定partition字段,那么就需要依赖分区器,根据key这个字段来计算partition的值。分区器的作用就是为消息分配分区
默认情况下,如果消息的key不为null,那么默认的分区器会对key进行哈希(采用MurmurHash2算法,具备高运算性能及低碰撞率),最终根据得到的哈希值来计算分区号,拥有相同key的消息会被写入同一个分区。如果key为null,那么消息将会以轮询的方式发往主题内的各个可用分区。
注意:如果key不为null,那么计算得到的分区号会是所有分区中的任意一个;如果key为null并且有可用分区,那么计算得到的分区号仅为可用分区中的任意一个,注意两者之间的差别。
- 消费者的分区分配
对于消费者的分区分配而言,Kafka自身提供了三种策略,分别为RangeAssignor、RoundRobinAssignor以及StickyAssignor,其中RangeAssignor为默认的分区分配策略.也可以通过实现ParitionAssignor接口来自定义分区分配策略
- broker端的分区分配
为集群制定创建主题时的分区副本分配方案,即在哪个broker中创建哪些分区的副本。分区分配是否均衡会影响到Kafka整体的负载均衡,具体还会牵涉到优先副本等概念。
在创建主题时,如果使用了replica-assignment参数,那么就按照指定的方案来进行分区副本的创建;如果没有使用replica-assignment参数,那么就需要按照内部的逻辑来计算分配方案了。使用kafka-topics.sh脚本创建主题时的内部分配逻辑按照机架信息划分成两种策略:未指定机架信息和指定机架信息。如果集群中所有的broker节点都没有配置broker.rack参数,或者使用disable-rack-aware参数来创建主题,那么采用的就是未指定机架信息的分配策略,否则采用的就是指定机架信息的分配策略。
https://blog.csdn.net/weixin_43823423/article/details/93469866
Kafka有哪几处地方有分区分配的概念?简述大致的过程及原理
生产者的分区分配是指为每条消息指定其所要发往的分区。可以编写一个具体的类实现org.apache.kafka.clients.producer.Partitioner接口。
消费者中的分区分配是指为消费者指定其可以消费消息的分区。Kafka 提供了消费者客户端参数 partition.assignment.strategy 来设置消费者与订阅主题之间的分区分配策略。
分区副本的分配是指为集群制定创建主题时的分区副本分配方案,即在哪个 broker 中创建哪些分区的副本。kafka-topics.sh 脚本中提供了一个 replica-assignment 参数来手动指定分区副本的分配方案。
失效副本是指什么?有哪些应对措施?
正常情况下,分区的所有副本都处于 ISR 集合中,但是难免会有异常情况发生,从而某些副本被剥离出 ISR 集合中。在 ISR 集合之外,也就是处于同步失效或功能失效(比如副本处于非存活状态)的副本统称为失效副本,失效副本对应的分区也就称为同步失效分区,即 under-replicated 分区。
Kafka 从 0.9.x 版本开始就通过唯一的 broker 端参数 replica.lag.time.max.ms 来抉择,当 ISR 集合中的一个 follower 副本滞后 leader 副本的时间超过此参数指定的值时则判定为同步失败,需要将此 follower 副本剔除出 ISR 集合。replica.lag.time.max.ms 参数的默认值为10000。
在 0.9.x 版本之前,Kafka 中还有另一个参数 replica.lag.max.messages(默认值为4000),它也是用来判定失效副本的,当一个 follower 副本滞后 leader 副本的消息数超过 replica.lag.max.messages 的大小时,则判定它处于同步失效的状态。它与 replica.lag.time.max.ms 参数判定出的失效副本取并集组成一个失效副本的集合,从而进一步剥离出分区的 ISR 集合。
Kafka 源码注释中说明了一般有这几种情况会导致副本失效:
follower 副本进程卡住,在一段时间内根本没有向 leader 副本发起同步请求,比如频繁的 Full GC。
follower 副本进程同步过慢,在一段时间内都无法追赶上 leader 副本,比如 I/O 开销过大。
如果通过工具增加了副本因子,那么新增加的副本在赶上 leader 副本之前也都是处于失效状态的。
如果一个 follower 副本由于某些原因(比如宕机)而下线,之后又上线,在追赶上 leader 副本之前也处于失效状态。
应对措施
我们用UnderReplicatedPartitions代表leader副本在当前Broker上且具有失效副本的分区的个数。
如果集群中有多个Broker的UnderReplicatedPartitions保持一个大于0的稳定值时,一般暗示着集群中有Broker已经处于下线状态。这种情况下,这个Broker中的分区个数与集群中的所有UnderReplicatedPartitions(处于下线的Broker是不会上报任何指标值的)之和是相等的。通常这类问题是由于机器硬件原因引起的,但也有可能是由于操作系统或者JVM引起的 。
如果集群中存在Broker的UnderReplicatedPartitions频繁变动,或者处于一个稳定的大于0的值(这里特指没有Broker下线的情况)时,一般暗示着集群出现了性能问题,通常这类问题很难诊断,不过我们可以一步一步的将问题的范围缩小,比如先尝试确定这个性能问题是否只存在于集群的某个Broker中,还是整个集群之上。如果确定集群中所有的under-replicated分区都是在单个Broker上,那么可以看出这个Broker出现了问题,进而可以针对这单一的Broker做专项调查,比如:操作系统、GC、网络状态或者磁盘状态(比如:iowait、ioutil等指标)。
多副本下,各个副本中的 HW和 LEO的演变过程
某个分区有3个副本分别位于 broker0、broker1 和 broker2 节点中,假设 broker0 上的副本1为当前分区的 Leader 副本,那么副本2和副本3就是 Follower 副本,整个消息追加的过程可以概括如下:
- 生产者客户端发送消息至 Leader 副本(副本1)中;
- 消息被追加到 Leader 副本的本地日志,并且会更新日志的偏移量。
- Follower 副本(副本2和副本3)向 Leader 副本请求同步数据。
- Leader 副本所在的服务器读取本地日志,并更新对应拉取的 Follower 副本的信息。
- Leader 副本所在的服务器将拉取结果返回给 Follower 副本。
- Follower 副本收到 Leader 副本返回的拉取结果,将消息追加到本地日志中,并更新日志的偏移量信息。
某一时刻,Leader 副本的 LEO 增加至5,并且所有副本的 HW 还都为0

之后 Follower 副本(不带阴影的方框)向 Leader 副本拉取消息,在拉取的请求中会带有自身的 LEO 信息,这个 LEO 信息对应的是 FetchRequest 请求中的 fetch_offset。Leader 副本返回给 Follower 副本相应的消息,并且还带有自身的 HW 信息,如上图(右)所示,这个 HW 信息对应的是 FetchResponse 中的 high_watermark。
此时两个 Follower 副本各自拉取到了消息,并更新各自的 LEO 为3和4。与此同时,Follower 副本还会更新自己的 HW,更新 HW 的算法是比较当前 LEO 和 Leader 副本中传送过来的 HW的值,取较小值作为自己的 HW 值。当前两个 Follower 副本的 HW 都等于0(min(0,0) = 0)。
接下来 Follower 副本再次请求拉取 Leader 副本中的消息,如下图(左)所示。

此时 Leader 副本收到来自 Follower 副本的 FetchRequest 请求,其中带有 LEO 的相关信息,选取其中的最小值作为新的 HW,即 min(15,3,4)=3。然后连同消息和 HW 一起返回 FetchResponse 给 Follower 副本,如上图(右)所示。注意 Leader 副本的 HW 是一个很重要的东西,因为它直接影响了分区数据对消费者的可见性。两个 Follower 副本在收到新的消息之后更新 LEO 并且更新自己的 HW 为3(min(LEO,3)=3)
https://www.pianshen.com/article/69122024501/
副本和ISR扮演什么角色?
基本上,复制日志的节点列表就是副本。特别是对于特定的分区。但是,无论他们是否扮演领导者的角色,他们都是如此。此外,ISR指的是同步副本。在定义ISR时,它是一组与领导者同步的消息副本。
解释如何减少ISR中的扰动?broker什么时候离开ISR?
ISR是一组与leaders完全同步的消息副本,也就是说ISR中包含了所有提交的消息。
ISR应该总是包含所有的副本,直到出现真正的故障。如果一个副本从leader中脱离出来,将会从ISR中删除。
Kafka为什么需要复制?
Kafka的信息复制确保了任何已发布的消息不会丢失,并且可以在机器错误、程序错误或更常见些的软件升级中使用
如果副本在ISR中停留了很长时间表明什么?
如果一个副本在ISR中保留了很长一段时间,那么它就表明,跟踪器无法像在leader收集数据那样快速地获取数据。
请说明如果首选的副本不在ISR中会发生什么?
如果首选的副本不在ISR中,控制器将无法将leadership转移到首选的副本
Kafka创建Topic时如何将分区放置到不同的Broker中
- 副本因子不能大于 Broker 的个数;
- 第一个分区(编号为0)的第一个副本放置位置是随机从 brokerList 选择的;
- 其他分区的第一个副本放置位置相对于第0个分区依次往后移。
也就是如果我们有5个 Broker,5个分区,假设第一个分区放在第四个 Broker 上,那么第二个分区将会放在第五个 Broker 上;第三个分区将会放在第一个 Broker 上;第四个分区将会放在第二个 Broker 上,依次类推,剩余的副本相对于第一个副本放置位置其实是由 nextReplicaShift 决定的,而这个数也是随机产生的
Kafka新建的分区会在哪个目录下创建
在启动 Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka 数据的存放目录,这个参数可以配置多个目录,目录之间使用逗号分隔,通常这些目录是分布在不同的磁盘上用于提高读写性能。 当然我们也可以配置 log.dir 参数,含义一样。只需要设置其中一个即可。
如果 log.dirs 参数只配置了一个目录,那么分配到各个 Broker 上的分区肯定只能在这个目录下创建文件夹用于存放数据。 但是如果 log.dirs 参数配置了多个目录,那么 Kafka 会在哪个文件夹中创建分区目录呢?答案是:Kafka 会在含有分区目录最少的文件夹中创建新的分区目录,分区目录名为 Topic名+分区ID。
注意,是分区文件夹总数最少的目录,而不是磁盘使用量最少的目录!也就是说,如果你给 log.dirs 参数新增了一个新的磁盘,新的分区目录肯定是先在这个新的磁盘上创建直到这个新的磁盘目录拥有的分区目录不是最少为止。
partition的数据如何保存到硬盘
topic中的多个partition以文件夹的形式保存到broker,每个分区序号从0递增, 且消息有序 Partition文件下有多个segment(xxx.index,xxx.log) segment 文件里的大小和配置文件大小一致可以根据要求修改。默认为1g,如果大小大于1g时,会滚动一个新的segment并且以上一个segment最后一条消息的偏移量命名
日志
简述Kafka的日志目录结构
Kafka 中的消息是以主题为基本单位进行归类的,各个主题在逻辑上相互独立。每个主题又可以分为一个或多个分区。不考虑多副本的情况,一个分区对应一个日志(Log)。为了防止 Log 过大,Kafka 又引入了日志分段(LogSegment)的概念,将 Log 切分为多个 LogSegment,相当于一个巨型文件被平均分配为多个相对较小的文件。
Log 和 LogSegment 也不是纯粹物理意义上的概念,Log 在物理上只以文件夹的形式存储,而每个 LogSegment 对应于磁盘上的一个日志文件和两个索引文件,以及可能的其他文件(比如以“.txnindex”为后缀的事务索引文件)

Kafka中有哪些索引文件?
每个日志分段文件对应了两个索引文件,主要用来提高查找消息的效率。
- 偏移量索引文件用来建立消息偏移量(offset)到物理地址之间的映射关系,方便快速定位消息所在的物理文件位置
- 时间戳索引文件则根据指定的时间戳(timestamp)来查找对应的偏移量信息。
如果我指定了一个offset,Kafka怎么查找到对应的消息?
Kafka是通过seek() 方法来指定消费的,在执行seek() 方法之前要去执行一次poll()方法,等到分配到分区之后会去对应的分区的指定位置开始消费,如果指定的位置发生了越界,那么会根据auto.offset.reset 参数设置的情况进行消费。
如果我指定了一个timestamp,Kafka怎么查找到对应的消息?
Kafka提供了一个 offsetsForTimes() 方法,通过 timestamp 来查询与此对应的分区位置。offsetsForTimes() 方法的参数 timestampsToSearch 是一个 Map 类型,key 为待查询的分区,而 value 为待查询的时间戳,该方法会返回时间戳大于等于待查询时间的第一条消息对应的位置和时间戳,对应于 OffsetAndTimestamp 中的 offset 和 timestamp 字段。
聊一聊你对Kafka的Log Retention的理解
日志删除(Log Retention):按照一定的保留策略直接删除不符合条件的日志分段。
我们可以通过 broker 端参数 log.cleanup.policy 来设置日志清理策略,此参数的默认值为“delete”,即采用日志删除的清理策略。
-
基于时间
日志删除任务会检查当前日志文件中是否有保留时间超过设定的阈值(retentionMs)来寻找可删除的日志分段文件集合(deletableSegments)retentionMs 可以通过 broker 端参数 log.retention.hours、log.retention.minutes 和 log.retention.ms 来配置,其中 log.retention.ms 的优先级最高,log.retention.minutes 次之,log.retention.hours 最低。默认情况下只配置了 log.retention.hours 参数,其值为168,故默认情况下日志分段文件的保留时间为7天。
删除日志分段时,首先会从 Log 对象中所维护日志分段的跳跃表中移除待删除的日志分段,以保证没有线程对这些日志分段进行读取操作。然后将日志分段所对应的所有文件添加上“.deleted”的后缀(当然也包括对应的索引文件)。最后交由一个以“delete-file”命名的延迟任务来删除这些以“.deleted”为后缀的文件,这个任务的延迟执行时间可以通过 file.delete.delay.ms 参数来调配,此参数的默认值为60000,即1分钟。 -
基于日志大小
日志删除任务会检查当前日志的大小是否超过设定的阈值(retentionSize)来寻找可删除的日志分段的文件集合(deletableSegments)。
retentionSize 可以通过 broker 端参数 log.retention.bytes 来配置,默认值为-1,表示无穷大。注意 log.retention.bytes 配置的是 Log 中所有日志文件的总大小,而不是单个日志分段(确切地说应该为 .log 日志文件)的大小。单个日志分段的大小由 broker 端参数 log.segment.bytes 来限制,默认值为1073741824,即 1GB。
这个删除操作和基于时间的保留策略的删除操作相同。 -
基于日志起始偏移量
基于日志起始偏移量的保留策略的判断依据是某日志分段的下一个日志分段的起始偏移量 baseOffset 是否小于等于 logStartOffset,若是,则可以删除此日志分段。

如上图所示,假设 logStartOffset 等于25,日志分段1的起始偏移量为0,日志分段2的起始偏移量为11,日志分段3的起始偏移量为23,通过如下动作收集可删除的日志分段的文件集合 deletableSegments:
从头开始遍历每个日志分段,日志分段1的下一个日志分段的起始偏移量为11,小于 logStartOffset 的大小,将日志分段1加入 deletableSegments。
日志分段2的下一个日志偏移量的起始偏移量为23,也小于 logStartOffset 的大小,将日志分段2加入 deletableSegments。
日志分段3的下一个日志偏移量在 logStartOffset 的右侧,故从日志分段3开始的所有日志分段都不会加入 deletableSegments。
收集完可删除的日志分段的文件集合之后的删除操作同基于日志大小的保留策略和基于时间的保留策略相同
聊一聊你对Kafka的Log Compaction的理解
日志压缩(Log Compaction):针对每个消息的 key 进行整合,对于有相同 key 的不同 value 值,只保留最后一个版本。
如果要采用日志压缩的清理策略,就需要将 log.cleanup.policy 设置为“compact”,并且还需要将 log.cleaner.enable (默认值为 true)设定为 true。

如下图所示,Log Compaction 对于有相同 key 的不同 value 值,只保留最后一个版本。如果应用只关心 key 对应的最新 value 值,则可以开启 Kafka 的日志清理功能,Kafka 会定期将相同 key 的消息进行合并,只保留最新的 value 值。
Kafka存储在硬盘上的消息格式是什么?
消息由一个固定长度的头部和可变长度的字节数组组成。头部包含了一个版本号和CRC32校验码。
- 消息长度: 4 bytes (value: 1+4+n)
- 版本号: 1 byte
- CRC校验码: 4 bytes
- 具体的消息: n bytes
Kafka高效文件存储设计特点:
- Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
- 通过索引信息可以快速定位message和确定response的最大大小。
- 通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。
- 通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
生产者
讲一讲kafka的ack的三种机制
request.required.acks有三个值0、1、-1( all )
- 0: 生产者不会等待broker的ack,这个延迟最低。但是存 储的保证最弱,当server挂掉的时候就会丢数据。
- 1:服务端会等待ack值,leader副本确认接收到消息后发 送ack,但是如果leader挂掉后他不确保是否复制完成新lea der,也会导致数据丢失 。
- -1 (all) :服务端会等所有的follower的副本收到数据后才会收到leader发出的ack,这样数据不会丢失
有可能在生产后发生消息偏移吗?
在大多数队列系统中,作为生产者的类无法做到这一点,它的作用是触发并忘记消息。broker将完成剩下的工作,比如使用id进行适当的元数据处理、偏移量等。
作为消息的用户,你可以从Kafka broker中获得补偿。如果你注视SimpleConsumer类,你会注意到它会获取包括偏移量作为列表的MultiFetchResponse对象。此外,当你对Kafka消息进行迭代时,你会拥有包括偏移量和消息发送的MessageAndOffset对象。
kafaka生产数据时数据的分组策略,生产者决定数据产生到集群的哪个partition中
每一条消息都是以(key,value)格式 Key是由生产者发送数据传入 所以生产者(key)决定了数据产生到集群的哪个partition
消费者
消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1?
当前消费者需要提交的消费位移是offset+1
在新消费者客户端中,消费位移存储在 Kafka内部的主题 __consumer_offsets 中。
有哪些情形会造成重复消费?
- Rebalance
一个consumer正在消费一个分区的一条消息,还没有消费完,发生了rebalance(加入了一个consumer),从而导致这条消息没有消费成功,rebalance后,另一个consumer又把这条消息消费一遍。
- 消费者端手动提交
如果先消费消息,再更新offset位置,导致消息重复消费
- 消费者端自动提交
设置offset为自动提交,关闭kafka时,如果在close之前,调用 consumer.unsubscribe() 则有可能部分offset没提交,下次重启会重复消费。
- 生产者端
ack 设置为 -1 ,Leader收到数据follower同步数据后 ,brocker准备返回ack的时候挂掉了,新选出的Leader则会出现重复发送的情况
哪些情景下会造成消息丢失?
- 自动提交
设置offset为自动定时提交,当offset被自动定时提交时,数据还在内存中未处理,此时刚好把线程kill掉,那么offset已经提交,但是数据未处理,导致这部分内存中的数据丢失。
- 生产者发送消息
ack 设置为 0或者1时,没有设置为all
- 为0时,无状态返回,不知道是否收到
- 为1时,只有Leader收到就返回ack,此时Leader挂了,副本尚未同步,则会漏消费。
- 消费者端
先提交位移,但是消息还没消费完就宕机了,造成了消息没有被消费。自动位移提交同理
KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?
-
线程封闭,即为每个线程实例化一个 KafkaConsumer 对象。一个线程对应一个 KafkaConsumer实例,我们可以称之为消费线程。一个消费线程可以消费一个或多个分区中的消息,所有的消费线程都隶属于同一个消费组。

-
消费者程序使用单或多线程获取消息,同时创建多个消费线程执行消息处理逻辑。
获取消息的线程可以是一个,也可以是多个,每个线程维护专属的 KafkaConsumer实例,处理消息则交由特定的线程池来做,从而实现消息获取与消息处理的真正解耦。
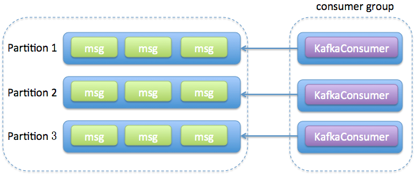

简述消费者与消费组之间的关系
- Consumer Group 下可以有一个或多个 Consumer 实例。这里的实例可以是一个单独的进程,也可以是同一进程下的线程。在实际场景中,使用进程更为常见一些。
- Group ID 是一个字符串,在一个 Kafka 集群中,它标识唯一的一个 Consumer Group。
- Consumer Group下所有实例订阅的主题的单个分区,只能分配给组内的某个 Consumer实例消费。这个分区当然也可以被其他的 Group 消费。
Kafka的旧版Scala的消费者客户端的设计有什么缺陷?
解释一:
老版本的 Consumer Group 把位移保存在 ZooKeeper 中。Apache ZooKeeper是一个分布式的协调服务框架,Kafka 重度依赖它实现各种各样的协调管理。将位移保存在 ZooKeeper 外部系统的做法,最显而易见的好处就是减少了 Kafka Broker 端的状态保存开销。
ZooKeeper 这类元框架其实并不适合进行频繁的写更新,而 Consumer Group的位移更新却是一个非常频繁的操作。这种大吞吐量的写操作会极大地拖慢 ZooKeeper集群的性能
解释二:

如上图,旧版消费者客户端每个消费组()在 ZooKeeper 中都维护了一个 /consumers/group n/ids 路径,在此路径下使用临时节点记录隶属于此消费组的消费者的唯一标识(consumerId),/consumers/group n/owner 路径下记录了分区和消费者的对应关系,/consumers/group n/offsets 路径下记录了此消费组在分区中对应的消费位移。
每个消费者在启动时都会在 /consumers/group n/ids 和 /brokers/ids 路径上注册一个监听器。当 /consumers/group n/ids 路径下的子节点发生变化时,表示消费组中的消费者发生了变化;当 /brokers/ids 路径下的子节点发生变化时,表示 broker 出现了增减。这样通过 ZooKeeper 所提供的 Watcher,每个消费者就可以监听消费组和 Kafka 集群的状态了。
这种方式下每个消费者对 ZooKeeper 的相关路径分别进行监听,当触发再均衡操作时,一个消费组下的所有消费者会同时进行再均衡操作,而消费者之间并不知道彼此操作的结果,这样可能导致 Kafka 工作在一个不正确的状态。与此同时,这种严重依赖于 ZooKeeper 集群的做法还有两个比较严重的问题。
-
羊群效应(Herd Effect):所谓的羊群效应是指ZooKeeper 中一个被监听的节点变化,大量的 Watcher 通知被发送到客户端,导致在通知期间的其他操作延迟,也有可能发生类似死锁的情况。
-
脑裂问题(Split Brain):消费者进行再均衡操作时每个消费者都与 ZooKeeper 进行通信以判断消费者或broker变化的情况,由于 ZooKeeper 本身的特性,可能导致在同一时刻各个消费者获取的状态不一致,这样会导致异常问题发生。
“消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果正确,那么有没有什么hack的手段?
通过自定义分区分配策略,可以将一个consumer指定消费所有partition
开发者也可以继承AbstractPartitionAssignor实现自定义消费策略,从而实现同一消费组内的任意消费者都可以消费订阅主题的所有分区
注意组内广播的这种实现方式会有一个严重的问题—默认的消费位移的提交会失效
public class BroadcastAssignor extends AbstractPartitionAssignor{
@Override
public String name() {
return "broadcast";
}
private Map<String, List<String>> consumersPerTopic(
Map<String, Subscription> consumerMetadata) {
(具体实现请参考RandomAssignor中的consumersPerTopic()方法)
}
@Override
public Map<String, List<TopicPartition>> assign(
Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
Map<String, List<String>> consumersPerTopic =
consumersPerTopic(subscriptions);
Map<String, List<TopicPartition>> assignment = new HashMap<>();
//Java8
subscriptions.keySet().forEach(memberId ->
assignment.put(memberId, new ArrayList<>()));
//针对每一个主题,为每一个订阅的消费者分配所有的分区
consumersPerTopic.entrySet().forEach(topicEntry->{
String topic = topicEntry.getKey();
List<String> members = topicEntry.getValue();
Integer numPartitionsForTopic = partitionsPerTopic.get(topic);
if (numPartitionsForTopic == null || members.isEmpty())
return;
List<TopicPartition> partitions = AbstractPartitionAssignor
.partitions(topic, numPartitionsForTopic);
if (!partitions.isEmpty()) {
members.forEach(memberId ->
assignment.get(memberId).addAll(partitions));
}
});
return assignment;
}
}
https://www.cnblogs.com/luozhiyun/p/11811835.html?utm_source=tuicool&utm_medium=referral
解释Kafka的用户如何消费信息?
在Kafka中传递消息是通过使用sendfile API完成的。它支持将字节从套接口转移到磁盘,通过内核空间保存副本,并在内核用户之间调用内核。
Kafa consumer是否可以消费指定分区消息?
Kafa consumer消费消息时,向broker发出"fetch"请求去消费特定分区的消息,consumer指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,customer拥有了offset的控制权,可以向后回滚去重新消费之前的消息,这是很有意义的
consumer 是推还是拉?
Kafka遵循了一种大部分消息系统共同的传统的设计:producer将消息推送到broker,consumer从broker拉取消息 。
pull的好处
- 由broker决定消息推送的速率,对于不同消费速率的consumer就不太好处理了。消息系统都致力于让consumer以最大的速率最快速的消费消息,但不幸的是,push模式下,当broker推送的速率远大于consumer消费的速率时,consumer恐怕就要崩溃了。
- consumer可以自主决定是否批量的从broker拉取数据。Push模式必须在不知道下游consumer消费能力和消费策略的情 况下决定是立即推送每条消息还是缓存之后批量推送。如果为了避免consumer崩溃而采用较低的推送速率,将可能导致 一次只推送较少的消息而造成浪费。Pull模式下,consumer 就可以根据自己的消费能力去决定这些策略。
Pull的缺点:
- 如果broker没有可供消费的消息,导致consumer不断在循环中轮询,直到新消息到达。为了避免这点,Kafka有个参 数可以让consumer阻塞直到新消息到达(当然也可以阻塞直到消息的数量,达到某个特定的量,这样就可以批量发送)。
什么是消费者组?
消费者组的概念是Apache Kafka独有的。基本上,每个Kafka消费群体都由一个或多个共同消费一组订阅主题的消费者组成。
讲讲kafka维护消费状态跟踪的方法
Kafka中Topic被分成了若干分区,每个分区在同一时间只被一个consumer消费。这意味着每个分区被消费的消息在日志 中的位置仅仅是一个简单的整数:offset。这样就很容易标 记每个分区消费状态,仅仅需要一个整数而已。
这带来了另外一个好处:consumer可以把offset调成一个较老的值,去重新消费老的消息。这对传统的消息系统来说看起来有些不可思议,但确实是非常有用的,谁规定了一条消息只能被消费一次呢?
大部分消息系统在broker端的维护消息被消费的记录:一 个消息被分发到consumer后broker就马上进行标记或者等待 customer的通知后进行标记。这样也可以在消息在消费后立马就删除以减少空间占用。
但是这样会不会有什么问题呢?如果一条消息发送出去之后就立即被标记为消费过的,一旦consumer处理消息时失败 了(比如程序崩溃)消息就丢失了。为了解决这个问题,很多消息系统提供了另外一个个功能:当消息被发送出去之后仅仅被标记为已发送状态,当接到consumer已经消费成功的 通知后才标记为已被消费的状态.这虽然解决了消息丢失的问题但产生了新问题,首先如果consumer处理消息成功了但 是向broker发送响应时失败了,这条消息将被消费两次。第 二个问题时,broker必须维护每条消息的状态,并且每次都 要先锁住消息然后更改状态然后释放锁。这样麻烦又来了,且不说要维护大量的状态数据,比如如果消息发送出去但没有收到消费成功的通知,这条消息将一直处于被锁定的状态
消费者如何不自动提交偏移量,由应用提交?
将auto.commit.offset设为false,然后在处理一批消息后 commitSync( )或者异步提交commitAsync(), 即:
ConsumerRecords<> records = consumer.poll();
for (ConsumerRecord<> record: records){
...
tyr{
consumer.commitSync();
}
...
}
消费者故障,出现活锁问题如何解决?
岀现“活锁”的情况,是它持续的发送心跳,但是没有处理。为了预防消费者在这种情况下一直持有分区,我们使用max.poll.interval.ms活跃检测机制。在此基础上,如果你调用的poll的频率大于最大间隔,则客户端将主动地离开组,以便其他消费者接管该分区。发生这种情况时,你会看到offset提交失败。这是一种安全机制,保障只有活动成员能够提交offsets,所以要留在组中,你必须持续调用polL消费者提供两个配置设置来控制poll循环:
- max.poll.interval.ms: 増大poll的间隔,可以为消费者提供更多的时间去处理返回 的消息(调用pollQong)返回的消息,通常返回的消息都是一批)。缺点是此值越 大将会延迟组重新平衡。
- max.poll.records:此设置限制每次调用poll返回的消息数,这样可以更容易的预测W poll间隔要处理的最大值。通过调整此值,可以减少poll间隔,减少重新平衡分组的
对于消息处理时间不可预测地的情况,这些选项是不够的。处理这种情况的推荐方法是将消息处理移到另一个进程中,让消费者继续调用poll。但是必须注意确保已提交的offset不超过实际位置。另外,你必须禁用自动提交,并只有在进程完 成处理后才为记录手动提交偏移量(取决于你)。还要注意,你需要pause暂停分区,不会从poll接收到新消息,让进程处理完之前返回的消息(如果你的处理能力比拉取消息的慢,那创建新进程将导致你机器内存溢岀)。
如何控制消费的位置?
kafka使用seek(TopicPartition, long)指定新的消费位置。
用于查找服务器保留的最早和最新的offset的特殊的方法也可用(seekToBeginning(Collection)和seekToEnd(Collection))
kafka 分布式(不是单机)的情况下,如何保证消息的顺序消费?
Kafka分布式的单位是partition分区,同一个partition用一个write ahead log组织,所以可以保证FIFO的顺序。不同partition之间不能保证顺序。但是绝大多数 用户都可以通过message key来定义,因为同一个key的message可以保证只发送 到同一个 partition
Kafka中发送1条消息的时候,可以指定(topic,partition, key)3个参数。partiton和key是可选的。如果指定了 partition,那就是所有消息发往同1个partition,就是有序的。并且在消费端,Kafka保证,1个partition只能被1个 consumer消费。或者你指定key(比如order id),具有同1个key的所有消息,会发往同1个partition
rebalance
kafka什么情况下会rebalance
rebalance 的触发条件有五个:
- 条件1:有新的consumer加入
- 条件2:旧的consumer挂了
- 条件3:coordinator挂了,集群选举出新的coordinator
- 条件4:topic的partition新加
- 条件5:consumer调用unsubscrible(),取消topic的订阅
rebalance 发生时,Group 下所有 consumer 实例都会协调在一起共同参与,kafka 能够保证尽量达到最公平的分配。但是 Rebalance 过程对 consumer group 会造成比较严重的影响。在 Rebalance 的过程中 consumer group 下的所有消费者实例都会停止工作,等待 Rebalance 过程完成。
kafka consumer 什么情况会触发再平衡reblance?
- 一旦消费者加入或退出消费组,导致消费组成员列表发生变化,消费组中的所有消费者都要执行再平衡。
- 订阅主题分区发生变化,所有消费者也都要再平衡
消费再均衡的原理是什么?(提示:消费者协调器和消费组协调器)
就目前而言,一共有如下几种情形会触发再均衡的操作:
有新的消费者加入消费组。
有消费者宕机下线。消费者并不一定需要真正下线,例如遇到长时间的GC、网络延迟导致消费者长时间未向 GroupCoordinator 发送心跳等情况时,GroupCoordinator 会认为消费者已经下线。
有消费者主动退出消费组(发送 LeaveGroupRequest 请求)。比如客户端调用了 unsubscrible() 方法取消对某些主题的订阅。
消费组所对应的 GroupCoorinator 节点发生了变更。
消费组内所订阅的任一主题或者主题的分区数量发生变化。
GroupCoordinator 是 Kafka 服务端中用于管理消费组的组件。而消费者客户端中的 ConsumerCoordinator 组件负责与 GroupCoordinator 进行交互。
第一阶段(FIND_COORDINATOR)
消费者需要确定它所属的消费组对应的 GroupCoordinator 所在的 broker,并创建与该 broker 相互通信的网络连接。如果消费者已经保存了与消费组对应的 GroupCoordinator 节点的信息,并且与它之间的网络连接是正常的,那么就可以进入第二阶段。否则,就需要向集群中的某个节点发送 FindCoordinatorRequest 请求来查找对应的 GroupCoordinator,这里的“某个节点”并非是集群中的任意节点,而是负载最小的节点。
第二阶段(JOIN_GROUP)
在成功找到消费组所对应的 GroupCoordinator 之后就进入加入消费组的阶段,在此阶段的消费者会向 GroupCoordinator 发送 JoinGroupRequest 请求,并处理响应。
选举消费组的leader
如果消费组内还没有 leader,那么第一个加入消费组的消费者即为消费组的 leader。如果某一时刻 leader 消费者由于某些原因退出了消费组,那么会重新选举一个新的 leader
选举分区分配策略
收集各个消费者支持的所有分配策略,组成候选集 candidates。
每个消费者从候选集 candidates 中找出第一个自身支持的策略,为这个策略投上一票。
计算候选集中各个策略的选票数,选票数最多的策略即为当前消费组的分配策略。
第三阶段(SYNC_GROUP)
leader 消费者根据在第二阶段中选举出来的分区分配策略来实施具体的分区分配,在此之后需要将分配的方案同步给各个消费者,通过 GroupCoordinator 这个“中间人”来负责转发同步分配方案的。

第四阶段(HEARTBEAT)
进入这个阶段之后,消费组中的所有消费者就会处于正常工作状态。在正式消费之前,消费者还需要确定拉取消息的起始位置。假设之前已经将最后的消费位移提交到了 GroupCoordinator,并且 GroupCoordinator 将其保存到了 Kafka 内部的 __consumer_offsets 主题中,此时消费者可以通过 OffsetFetchRequest 请求获取上次提交的消费位移并从此处继续消费。
消费者通过向 GroupCoordinator 发送心跳来维持它们与消费组的从属关系,以及它们对分区的所有权关系。只要消费者以正常的时间间隔发送心跳,就被认为是活跃的,说明它还在读取分区中的消息。心跳线程是一个独立的线程,可以在轮询消息的空档发送心跳。如果消费者停止发送心跳的时间足够长,则整个会话就被判定为过期,GroupCoordinator 也会认为这个消费者已经死亡,就会触发一次再均衡行为。
描述下kafka consumer 再平衡步骤?
- 关闭数据拉取线程,清空队列和消息流,提交偏移量;
- 释放分区所有权,删除zk中分区和消费者的所有者关系;
- 将所有分区重新分配给每个消费者,每个消费者都会分到不同分区;
- 将分区对应的消费者所有关系写入ZK,记录分区的所有权信息;
- 重启消费者拉取线程管理器,管理每个分区的拉取线程。
Rebalance有什么影响
Rebalance本身是Kafka集群的一个保护设定,用于剔除掉无法消费或者过慢的消费者,然后由于我们的数据量较大,同时后续消费后的数据写入需要走网络IO,很有可能存在依赖的第三方服务存在慢的情况而导致我们超时。Rebalance对我们数据的影响主要有以下几点:
数据重复消费: 消费过的数据由于提交offset任务也会失败,在partition被分配给其他消费者的时候,会造成重复消费,数据重复且增加集群压力
Rebalance扩散到整个ConsumerGroup的所有消费者,因为一个消费者的退出,导致整个Group进行了Rebalance,并在一个比较慢的时间内达到稳定状态,影响面较大
频繁的Rebalance反而降低了消息的消费速度,大部分时间都在重复消费和Rebalance
数据不能及时消费,会累积lag,在Kafka的TTL之后会丢弃数据 上面的影响对于我们系统来说,都是致命的。
怎么解决rebalance中遇到的问题呢
要避免 Rebalance,还是要从 Rebalance 发生的时机入手。我们在前面说过,Rebalance 主要发生的时机有三个:
组成员数量发生变化
订阅主题数量发生变化
订阅主题的分区数发生变化
后两个我们大可以人为的避免,发生rebalance最常见的原因是消费组成员的变化。
消费者成员正常的添加和停掉导致rebalance,这种情况无法避免,但是时在某些情况下,Consumer 实例会被 Coordinator 错误地认为 “已停止” 从而被“踢出”Group。从而导致rebalance。
当 Consumer Group 完成 Rebalance 之后,每个 Consumer 实例都会定期地向 Coordinator 发送心跳请求,表明它还存活着。如果某个 Consumer 实例不能及时地发送这些心跳请求,Coordinator 就会认为该 Consumer 已经 “死” 了,从而将其从 Group 中移除,然后开启新一轮 Rebalance。这个时间可以通过Consumer 端的参数 session.timeout.ms进行配置。默认值是 10 秒。
除了这个参数,Consumer 还提供了一个控制发送心跳请求频率的参数,就是 heartbeat.interval.ms。这个值设置得越小,Consumer 实例发送心跳请求的频率就越高。频繁地发送心跳请求会额外消耗带宽资源,但好处是能够更加快速地知晓当前是否开启 Rebalance,因为,目前 Coordinator 通知各个 Consumer 实例开启 Rebalance 的方法,就是将 REBALANCE_NEEDED 标志封装进心跳请求的响应体中。
除了以上两个参数,Consumer 端还有一个参数,用于控制 Consumer 实际消费能力对 Rebalance 的影响,即 max.poll.interval.ms 参数。它限定了 Consumer 端应用程序两次调用 poll 方法的最大时间间隔。它的默认值是 5 分钟,表示你的 Consumer 程序如果在 5 分钟之内无法消费完 poll 方法返回的消息,那么 Consumer 会主动发起 “离开组” 的请求,Coordinator 也会开启新一轮 Rebalance。
通过上面的分析,我们可以看一下那些rebalance是可以避免的:
第一类非必要 Rebalance 是因为未能及时发送心跳,导致 Consumer 被 “踢出”Group 而引发的。这种情况下我们可以设置 session.timeout.ms 和 heartbeat.interval.ms 的值,来尽量避免rebalance的出现。(以下的配置是在网上找到的最佳实践,暂时还没测试过)
设置 session.timeout.ms = 6s。设置 heartbeat.interval.ms = 2s。要保证 Consumer 实例在被判定为 “dead” 之前,能够发送至少 3 轮的心跳请求,即 session.timeout.ms >= 3 * heartbeat.interval.ms。将 session.timeout.ms 设置成 6s 主要是为了让 Coordinator 能够更快地定位已经挂掉的 Consumer,早日把它们踢出 Group。
第二类非必要 Rebalance 是 Consumer 消费时间过长导致的。此时,max.poll.interval.ms 参数值的设置显得尤为关键。如果要避免非预期的 Rebalance,你最好将该参数值设置得大一点,比你的下游最大处理时间稍长一点。
总之,要为业务处理逻辑留下充足的时间。这样,Consumer 就不会因为处理这些消息的时间太长而引发 Rebalance 。
kafka一次reblance大概要多久
1个Topic,10个partition,3个consumer 测试结果 经过几轮测试发现每次rebalance所消耗的时间大概在 80ms~100ms平均耗时在87ms左右。
事务
数据传输的事务定义有哪三种?
- 最多一次(at most once): 消息不会被重复发送,最多被传输一次,但也有可能一次不传输
最少一次(at least once): 消息不会被漏发送,最少被传输一次,但也有可能被重复传输 - 精确的一次(Exactly once): 不会漏传输也不会重复传输 ,每个消息都传输被一次而且仅仅被传输一次,这是大家所期望的
Kafka中的事务是怎么实现的?
Kafka中的事务可以使应用程序将消费消息、生产消息、提交消费位移当作原子操作来处理,同时成功或失败,即使该生产或消费会跨多个分区。
生产者必须提供唯一的transactionalId,启动后请求事务协调器获取一个PID,transactionalId与PID一一对应。
每次发送数据给<Topic, Partition>前,需要先向事务协调器发送AddPartitionsToTxnRequest,事务协调器会将该<Transaction, Topic, Partition>存于__transaction_state内,并将其状态置为BEGIN。
在处理完 AddOffsetsToTxnRequest 之后,生产者还会发送 TxnOffsetCommitRequest 请求给 GroupCoordinator,从而将本次事务中包含的消费位移信息 offsets 存储到主题 __consumer_offsets 中
一旦上述数据写入操作完成,应用程序必须调用KafkaProducer的commitTransaction方法或者abortTransaction方法以结束当前事务。无论调用 commitTransaction() 方法还是 abortTransaction() 方法,生产者都会向 TransactionCoordinator 发送 EndTxnRequest 请求。
TransactionCoordinator 在收到 EndTxnRequest 请求后会执行如下操作:
将 PREPARE_COMMIT 或 PREPARE_ABORT 消息写入主题 __transaction_state
通过 WriteTxnMarkersRequest 请求将 COMMIT 或 ABORT 信息写入用户所使用的普通主题和 __consumer_offsets
将 COMPLETE_COMMIT 或 COMPLETE_ABORT 信息写入内部主题 __transaction_state表明该事务结束
在消费端有一个参数isolation.level,设置为“read_committed”,表示消费端应用不可以看到尚未提交的事务内的消息。如果生产者开启事务并向某个分区值发送3条消息 msg1、msg2 和 msg3,在执行 commitTransaction() 或 abortTransaction() 方法前,设置为“read_committed”的消费端应用是消费不到这些消息的,不过在 KafkaConsumer 内部会缓存这些消息,直到生产者执行 commitTransaction() 方法之后它才能将这些消息推送给消费端应用。反之,如果生产者执行了 abortTransaction() 方法,那么 KafkaConsumer 会将这些缓存的消息丢弃而不推送给消费端应用。
Kafka中的幂等是怎么实现的?
为了实现生产者的幂等性,Kafka 为此引入了 producer id(以下简称 PID)和序列号(sequence number)这两个概念。
每个新的生产者实例在初始化的时候都会被分配一个 PID,这个 PID 对用户而言是完全透明的。对于每个 PID,消息发送到的每一个分区都有对应的序列号,这些序列号从0开始单调递增。生产者每发送一条消息就会将 <PID,分区> 对应的序列号的值加1。
broker 端会在内存中为每一对 <PID,分区> 维护一个序列号。对于收到的每一条消息,只有当它的序列号的值(SN_new)比 broker 端中维护的对应的序列号的值(SN_old)大1(即 SN_new = SN_old + 1)时,broker 才会接收它。如果 SN_new< SN_old + 1,那么说明消息被重复写入,broker 可以直接将其丢弃。如果 SN_new> SN_old + 1,那么说明中间有数据尚未写入,出现了乱序,暗示可能有消息丢失,对应的生产者会抛出 OutOfOrderSequenceException,这个异常是一个严重的异常,后续的诸如 send()、beginTransaction()、commitTransaction() 等方法的调用都会抛出 IllegalStateException 的异常。
kafka进阶
解释如何提高远程用户的吞吐量?
如果用户位于与broker不同的数据中心,则可能需要调优套接口缓冲区大小,以对长网络延迟进行摊销。
解释一下,在数据制作过程中,你如何能从Kafka得到准确的信息?
在数据中,为了精确地获得Kafka的消息,你必须遵循两件事:
- 在数据消耗期间避免重复
- 在数据生产过程中避免重复
这里有两种方法,可以在数据生成时准确地获得一个语义:
- 每个分区使用一个单独的写入器,每当你发现一个网络错误,检查该分区中的最后一条消息,以查看您的最后一次写入是否成功
- 在消息中包含一个主键(UUID或其他),并在用户中进行反复制
聊一聊你对Kafka底层存储的理解
- 页缓存
页缓存是操作系统实现的一种主要的磁盘缓存,以此用来减少对磁盘 I/O的操作。具体来说,就是把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问。
当一个进程准备读取磁盘上的文件内容时,操作系统会先查看待读取的数据所在的页(page)是否在页缓存(pagecache)中,如果存在(命中)则直接返回数据,从而避免了对物理磁盘的 I/O操作;如果没有命中,则操作系统会向磁盘发起读取请求并将读取的数据页存入页缓存,之后再将数据返回给进程。
同样,如果一个进程需要将数据写入磁盘,那么操作系统也会检测数据对应的页是否在页缓存中,如果不存在,则会先在页缓存中添加相应的页,最后将数据写入对应的页。被修改过后的页也就变成了脏页,操作系统会在合适的时间把脏页中的数据写入磁盘,以保持数据的一致性。
用过 Java 的人一般都知道两点事实:对象的内存开销非常大,通常会是真实数据大小的几倍甚至更多,空间使用率低下;Java 的垃圾回收会随着堆内数据的增多而变得越来越慢。基于这些因素,使用文件系统并依赖于页缓存的做法明显要优于维护一个进程内缓存或其他结构,至少我们可以省去了一份进程内部的缓存消耗,同时还可以通过结构紧凑的字节码来替代使用对象的方式以节省更多的空间。
此外,即使 Kafka 服务重启,页缓存还是会保持有效,然而进程内的缓存却需要重建。这样也极大地简化了代码逻辑,因为维护页缓存和文件之间的一致性交由操作系统来负责,这样会比进程内维护更加安全有效。
- 零拷贝
除了消息顺序追加、页缓存等技术,Kafka 还使用零拷贝(Zero-Copy)技术来进一步提升性能。所谓的零拷贝是指将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之手。零拷贝大大提高了应用程序的性能,减少了内核和用户模式之间的上下文切换。对 Linux 操作系统而言,零拷贝技术依赖于底层的 sendfile() 方法实现。对应于 Java 语言,FileChannal.transferTo() 方法的底层实现就是 sendfile() 方法。
聊一聊Kafka的延时操作的原理
Kafka 中有多种延时操作,比如延时生产,还有延时拉取(DelayedFetch)、延时数据删除(DelayedDeleteRecords)等。
延时操作创建之后会被加入延时操作管理器(DelayedOperationPurgatory)来做专门的处理。延时操作有可能会超时,每个延时操作管理器都会配备一个定时器(SystemTimer)来做超时管理,定时器的底层就是采用时间轮(TimingWheel)实现的。
聊一聊Kafka控制器的作用
在 Kafka 集群中会有一个或多个 broker,其中有一个 broker 会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态。当某个分区的 leader 副本出现故障时,由控制器负责为该分区选举新的 leader 副本。当检测到某个分区的 ISR 集合发生变化时,由控制器负责通知所有broker更新其元数据信息。当使用 kafka-topics.sh 脚本为某个 topic 增加分区数量时,同样还是由控制器负责分区的重新分配
Kafka的缓冲池满了怎么办?
无论消息是否被消费,kafka都会保留所有消息。而当消息的大小,大于设置的最大值log.retention.bytes(默认为1073741824)的值,也就是说这个缓冲池满了的时候,Kafka便会清除掉旧消息
那么它每次删除多少消息呢?
topic的分区partitions,被分为一个个小segment,按照segment为单位进行删除(segment的大小也可以进行配置,默认log.segment.bytes = 1024 * 1024 * 1024),由时间从远到近的顺序进行删除
此外,Kafka还支持基于时间策略进行删除数据,过期时间默认为:log.retention.hours=168
注意:因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高 Kafka 性能无关
Kafka在什么情况下会出现消息丢失?
以下几个阶段,都有可能会出现消息丢失的情况
1)消息发送的时候,如果发送出去以后,消息可能因为网络问题并没有发送成功
2)消息消费的时候,消费者在消费消息的时候,若还未做处理的时候,服务挂了,那这个消息不就丢失了
3)分区中的leader所在的broker挂了之后
我们知道,Kafka的Topic中的分区Partition是leader与follower的主从机制,发送消息与消费消息都直接面向leader分区,并不与follower交互,follower则会去leader中拉取消息,进行消息的备份,这样保证了一定的可靠性
但是,当leader副本所在的broker突然挂掉,那么就要从follower中选举一个leader,但leader的数据在挂掉之前并没有同步到follower的这部分消息肯定就会丢失掉
能说一下leader选举过程吗
Kafka的Leader选举是通过在ZooKeeper上创建/controller临时节点来实现leader选举,并在该节点中写入当前broker的信息 {“version”:1,”brokerid”:1,”timestamp”:”1512018424988”}
利用ZooKeeper的强一致性特性,一个节点只能被一个客户端创建成功,创建成功的broker即为leader,即先到先得原则,leader也就是集群中的controller,负责集群中所有大小事务。当leader和ZooKeeper失去连接时,临时节点会删除,而其他broker会监听该节点的变化,当节点删除时,其他broker会收到事件通知,重新发起leader选举。
分区Leader选举策略有几种?
分区的Leader副本选举对用户是完全透明的,它是由Controller独立完成的。你需要回答的是,在哪些场景下,需要执行分区Leader选举。每一种场景对应于一种选举策略。
OfflinePartition Leader选举:每当有分区上线时,就需要执行Leader选举。所谓的分区上线,可能是创建了新分区,也可能是之前的下线分区重新上线。这是最常见的分区Leader选举场景。
ReassignPartition Leader选举:当你手动运行kafka-reassign-partitions命令,或者是调用Admin的alterPartitionReassignments方法执行分区副本重分配时,可能触发此类选举。假设原来的AR是[1,2,3],Leader是1,当执行副本重分配后,副本集合AR被设置成[4,5,6],显然,Leader必须要变更,此时会发生Reassign Partition Leader选举。
PreferredReplicaPartition Leader选举:当你手动运行kafka-preferred-replica-election命令,或自动触发了Preferred Leader选举时,该类策略被激活。所谓的Preferred Leader,指的是AR中的第一个副本。比如AR是[3,2,1],那么,Preferred Leader就是3。
ControlledShutdownPartition Leader选举:当Broker正常关闭时,该Broker上的所有Leader副本都会下线,因此,需要为受影响的分区执行相应的Leader选举。
这4类选举策略的大致思想是类似的,即从AR中挑选首个在ISR中的副本,作为新Leader。
Kafka能手动删除消息吗?
Kafka不需要用户手动删除消息。它本身提供了留存策略,能够自动删除过期消息。当然,它是支持手动删除消息的。
- 对于设置了Key且参数cleanup.policy=compact的主题而言,我们可以构造一条 的消息发送给Broker,依靠Log Cleaner组件提供的功能删除掉该 Key 的消息。
- 对于普通主题而言,我们可以使用kafka-delete-records命令,或编写程序调用Admin.deleteRecords方法来删除消息。这两种方法殊途同归,底层都是调用Admin的deleteRecords方法,通过将分区Log Start Offset值抬高的方式间接删除消息。
Kafka的哪些场景中使用了零拷贝(Zero Copy)?
其实这道题对于SRE来讲,有点超纲了,不过既然Zero Copy是Kafka高性能的保证,我们需要了解它。
Zero Copy是特别容易被问到的高阶题目。在Kafka中,体现Zero Copy使用场景的地方有两处:基于mmap的索引和日志文件读写所用的TransportLayer。
先说第一个。索引都是基于MappedByteBuffer的,也就是让用户态和内核态共享内核态的数据缓冲区,此时,数据不需要复制到用户态空间。不过,mmap虽然避免了不必要的拷贝,但不一定就能保证很高的性能。在不同的操作系统下,mmap的创建和销毁成本可能是不一样的。很高的创建和销毁开销会抵消Zero Copy带来的性能优势。由于这种不确定性,在Kafka中,只有索引应用了mmap,最核心的日志并未使用mmap机制。
再说第二个。TransportLayer是Kafka传输层的接口。它的某个实现类使用了FileChannel的transferTo方法。该方法底层使用sendfile实现了Zero Copy。对Kafka而言,如果I/O通道使用普通的PLAINTEXT,那么,Kafka就可以利用Zero Copy特性,直接将页缓存中的数据发送到网卡的Buffer中,避免中间的多次拷贝。相反,如果I/O通道启用了SSL,那么,Kafka便无法利用Zero Copy特性了
如何调优Kafka?
对于Kafka来讲,常见的调优方向基本为:吞吐量、延时、持久性和可用性,每种目标之前都是由冲突点,这也就要求了,我们在对业务接入使用时,要进行业务场景的了解,以对业务进行相对的集群隔离,因为每一个方向的优化思路都是不同的,甚至是相反的。
确定了目标之后,还要明确优化的维度。有些调优属于通用的优化思路,比如对操作系统、JVM等的优化;有些则是有针对性的,比如要优化Kafka的TPS。我们需要从3个方向去考虑:
- Producer端:增加batch.size和linger.ms,启用压缩,关闭重试
- Broker端:增加num.replica.fetchers提升Follower同步TPS,避免Broker Full GC等。
- Consumer:增加fetch.min.bytes
Controller发生网络分区(Network Partitioning)时,Kafka会怎么样?
这道题目能够诱发我们对分布式系统设计、CAP理论、一致性等多方面的思考。
一旦发生Controller网络分区,那么,第一要务就是查看集群是否出现“脑裂”,即同时出现两个甚至是多个Controller组件。这可以根据Broker端监控指标ActiveControllerCount来判断。
不过,通常而言,我们在设计整个部署架构时,为了避免这种网络分区的发生,一般会将broker节点尽可能的防止在一个机房或者可用区。
由于Controller会给Broker发送3类请求,LeaderAndIsrRequest,StopReplicaRequest,UpdateMetadataRequest,因此,一旦出现网络分区,这些请求将不能顺利到达Broker端。
这将影响主题的创建、修改、删除操作的信息同步,表现为集群仿佛僵住了一样,无法感知到后面的所有操作。因此,网络分区通常都是非常严重的问题,要赶快修复
Java Consumer为什么采用单线程来获取消息?
在回答之前,如果先把这句话说出来,一定会加分:Java Consumer是双线程的设计。一个线程是用户主线程,负责获取消息;另一个线程是心跳线程,负责向Kafka汇报消费者存活情况。将心跳单独放入专属的线程,能够有效地规避因消息处理速度慢而被视为下线的“假死”情况。
单线程获取消息的设计能够避免阻塞式的消息获取方式。单线程轮询方式容易实现异步非阻塞式,这样便于将消费者扩展成支持实时流处理的操作算子。因为很多实时流处理操作算子都不能是阻塞式的。另外一个可能的好处是,可以简化代码的开发。多线程交互的代码是非常容易出错的。
简述Follower副本消息同步的完整流程
首先,Follower发送FETCH请求给Leader。
接着,Leader会读取底层日志文件中的消息数据,再更新它内存中的Follower副本的LEO值,更新为FETCH请求中的fetchOffset值。
最后,尝试更新分区高水位值。Follower接收到FETCH响应之后,会把消息写入到底层日志,接着更新LEO和HW值。
Leader和Follower的HW值更新时机是不同的,Follower的HW更新永远落后于Leader的HW。这种时间上的错配是造成各种不一致的原因。
因此,对于消费者而言,消费到的消息永远是所有副本中最小的那个HW。
消费者负载均衡策略
结合consumer的加入和退出进行再平衡策略。
讲一下主从同步?
如何设置Kafka能接收的最大消息的大小?
对于SRE来讲,该题简直是送分题啊,但是,最大消息的设置通常情况下有生产者端,消费者端,broker端和topic级别的参数,我们需要正确设置,以保证可以正常的生产和消费。
Broker端参数:message.max.bytes,max.message.bytes(topic级别),replica.fetch.max.bytes(否则follow会同步失败)
Consumer端参数:fetch.message.max.bytes
Broker的Heap Size如何设置?
其实对于SRE还是送分题,因为目前来讲大部分公司的业务系统都是使用Java开发,因此SRE对于基本的JVM相关的参数应该至少都是非常了解的,核心就在于JVM的配置以及GC相关的知识。
标准答案:任何Java进程JVM堆大小的设置都需要仔细地进行考量和测试。一个常见的做法是,以默认的初始JVM堆大小运行程序,当系统达到稳定状态后,手动触发一次Full GC,然后通过JVM工具查看GC后的存活对象大小。之后,将堆大小设置成存活对象总大小的1.5~2倍。对于Kafka而言,这个方法也是适用的。不过,业界有个最佳实践,那就是将Broker的Heap Size固定为6GB。经过很多公司的验证,这个大小是足够且良好的。
如何估算Kafka集群的机器数量?
该题也算是SRE的送分题吧,对于SRE来讲,任何生产的系统第一步需要做的就是容量预估以及集群的架构规划,实际上也就是机器数量和所用资源之间的关联关系,资源通常来讲就是CPU,内存,磁盘容量,带宽。但需要注意的是,Kafka因为独有的设计,对于磁盘的要求并不是特别高,普通机械硬盘足够,而通常的瓶颈会出现在带宽上。
在预估磁盘的占用时,你一定不要忘记计算副本同步的开销。如果一条消息占用1KB的磁盘空间,那么,在有3个副本的主题中,你就需要3KB的总空间来保存这条消息。同时,需要考虑到整个业务Topic数据保存的最大时间,以上几个因素,基本可以预估出来磁盘的容量需求。
需要注意的是:对于磁盘来讲,一定要提前和业务沟通好场景,而不是等待真正有磁盘容量瓶颈了才去扩容磁盘或者找业务方沟通方案。
对于带宽来说,常见的带宽有1Gbps和10Gbps,通常我们需要知道,当带宽占用接近总带宽的90%时,丢包情形就会发生。
Leader总是-1,怎么破?
对于有经验的SRE来讲,早期的Kafka版本应该多多少少都遇到过该种情况,通常情况下就是Controller不工作了,导致无法分配leader,那既然知道问题后,解决方案也就很简单了。重启Controller节点上的Kafka进程,让其他节点重新注册Controller角色,但是如上面ZooKeeper的作用,你要知道为什么Controller可以自动注册。
当然了,当你知道controller的注册机制后,你也可以说:删除ZooKeeper节点/controller,触发Controller重选举。Controller重选举能够为所有主题分区重刷分区状态,可以有效解决因不一致导致的 Leader 不可用问题。但是,需要注意的是,直接操作ZooKeeper是一件风险很大的操作,就好比在Linux中执行了rm -rf /xxx一样,如果在/和xxx之间不小心多了几个空格,那”恭喜你”,今年白干了。
Kafka在可靠性方面做了哪些改进?(HW, LeaderEpoch)
Kafka中的延迟队列怎么实现
在发送延时消息的时候并不是先投递到要发送的真实主题(real_topic)中,而是先投递到一些 Kafka 内部的主题(delay_topic)中,这些内部主题对用户不可见,然后通过一个自定义的服务拉取这些内部主题中的消息,并将满足条件的消息再投递到要发送的真实的主题中,消费者所订阅的还是真实的主题。
如果采用这种方案,那么一般是按照不同的延时等级来划分的,比如设定5s、10s、30s、1min、2min、5min、10min、20min、30min、45min、1hour、2hour这些按延时时间递增的延时等级,延时的消息按照延时时间投递到不同等级的主题中,投递到同一主题中的消息的延时时间会被强转为与此主题延时等级一致的延时时间,这样延时误差控制在两个延时等级的时间差范围之内(比如延时时间为17s的消息投递到30s的延时主题中,之后按照延时时间为30s进行计算,延时误差为13s)。虽然有一定的延时误差,但是误差可控,并且这样只需增加少许的主题就能实现延时队列的功能。

发送到内部主题(delay_topic_*)中的消息会被一个独立的 DelayService 进程消费,这个 DelayService 进程和 Kafka broker 进程以一对一的配比进行同机部署(参考下图),以保证服务的可用性。

针对不同延时级别的主题,在 DelayService 的内部都会有单独的线程来进行消息的拉取,以及单独的 DelayQueue(这里用的是 JUC 中 DelayQueue)进行消息的暂存。与此同时,在 DelayService 内部还会有专门的消息发送线程来获取 DelayQueue 的消息并转发到真实的主题中。从消费、暂存再到转发,线程之间都是一一对应的关系。如下图所示,DelayService 的设计应当尽量保持简单,避免锁机制产生的隐患。

为了保障内部 DelayQueue 不会因为未处理的消息过多而导致内存的占用过大,DelayService 会对主题中的每个分区进行计数,当达到一定的阈值之后,就会暂停拉取该分区中的消息。
因为一个主题中一般不止一个分区,分区之间的消息并不会按照投递时间进行排序,DelayQueue的作用是将消息按照再次投递时间进行有序排序,这样下游的消息发送线程就能够按照先后顺序获取最先满足投递条件的消息。
Kafka中怎么实现死信队列和重试队列?
死信可以看作消费者不能处理收到的消息,也可以看作消费者不想处理收到的消息,还可以看作不符合处理要求的消息。比如消息内包含的消息内容无法被消费者解析,为了确保消息的可靠性而不被随意丢弃,故将其投递到死信队列中,这里的死信就可以看作消费者不能处理的消息。再比如超过既定的重试次数之后将消息投入死信队列,这里就可以将死信看作不符合处理要求的消息。
重试队列其实可以看作一种回退队列,具体指消费端消费消息失败时,为了防止消息无故丢失而重新将消息回滚到 broker 中。与回退队列不同的是,重试队列一般分成多个重试等级,每个重试等级一般也会设置重新投递延时,重试次数越多投递延时就越大。
理解了他们的概念之后我们就可以为每个主题设置重试队列,消息第一次消费失败入重试队列 Q1,Q1 的重新投递延时为5s,5s过后重新投递该消息;如果消息再次消费失败则入重试队列 Q2,Q2 的重新投递延时为10s,10s过后再次投递该消息。
然后再设置一个主题作为死信队列,重试越多次重新投递的时间就越久,并且需要设置一个上限,超过投递次数就进入死信队列。重试队列与延时队列有相同的地方,都需要设置延时级别。
Kafka中怎么做消息审计?
消息审计是指在消息生产、存储和消费的整个过程之间对消息个数及延迟的审计,以此来检测是否有数据丢失、是否有数据重复、端到端的延迟又是多少等内容。
目前与消息审计有关的产品也有多个,比如 Chaperone(Uber)、Confluent Control Center、Kafka Monitor(LinkedIn),它们主要通过在消息体(value 字段)或在消息头(headers 字段)中内嵌消息对应的时间戳 timestamp 或全局的唯一标识 ID(或者是两者兼备)来实现消息的审计功能。
内嵌 timestamp 的方式主要是设置一个审计的时间间隔 time_bucket_interval(可以自定义设置几秒或几分钟),根据这个 time_bucket_interval 和消息所属的 timestamp 来计算相应的时间桶(time_bucket)。
内嵌 ID 的方式就更加容易理解了,对于每一条消息都会被分配一个全局唯一标识 ID。如果主题和相应的分区固定,则可以为每个分区设置一个全局的 ID。当有消息发送时,首先获取对应的 ID,然后内嵌到消息中,最后才将它发送到 broker 中。消费者进行消费审计时,可以判断出哪条消息丢失、哪条消息重复。
Kafka中怎么做消息轨迹?
消息轨迹指的是一条消息从生产者发出,经由 broker 存储,再到消费者消费的整个过程中,各个相关节点的状态、时间、地点等数据汇聚而成的完整链路信息。生产者、broker、消费者这3个角色在处理消息的过程中都会在链路中增加相应的信息,将这些信息汇聚、处理之后就可以查询任意消息的状态,进而为生产环境中的故障排除提供强有力的数据支持。
对消息轨迹而言,最常见的实现方式是封装客户端,在保证正常生产消费的同时添加相应的轨迹信息埋点逻辑。无论生产,还是消费,在执行之后都会有相应的轨迹信息,我们需要将这些信息保存起来。
我们同样可以将轨迹信息保存到 Kafka 的某个主题中,比如下图中的主题 trace_topic。

生产者在将消息正常发送到用户主题 real_topic 之后(或者消费者在拉取到消息消费之后)会将轨迹信息发送到主题 trace_topic 中。
怎么计算Lag?(注意read_uncommitted和read_committed状态下的不同)
如果消费者客户端的 isolation.level 参数配置为“read_uncommitted”(默认),它对应的 Lag 等于HW – ConsumerOffset 的值,其中 ConsumerOffset 表示当前的消费位移。
如果这个参数配置为“read_committed”,那么就要引入 LSO 来进行计算了。LSO 是 LastStableOffset 的缩写,它对应的 Lag 等于 LSO – ConsumerOffset 的值。
首先通过 DescribeGroupsRequest 请求获取当前消费组的元数据信息,当然在这之前还会通过 FindCoordinatorRequest 请求查找消费组对应的 GroupCoordinator。
接着通过 OffsetFetchRequest 请求获取消费位移 ConsumerOffset。
然后通过 KafkaConsumer 的 endOffsets(Collection partitions)方法(对应于 ListOffsetRequest 请求)获取 HW(LSO)的值。
最后通过 HW 与 ConsumerOffset 相减得到分区的 Lag,要获得主题的总体 Lag 只需对旗下的各个分区累加即可。
Kafka有哪些指标需要着重关注?
比较重要的 Broker 端 JMX 指标:
BytesIn/BytesOut:即 Broker 端每秒入站和出站字节数。你要确保这组值不要接近你的网络带宽,否则这通常都表示网卡已被“打满”,很容易出现网络丢包的情形。
NetworkProcessorAvgIdlePercent:即网络线程池线程平均的空闲比例。通常来说,你应该确保这个 JMX 值长期大于 30%。如果小于这个值,就表明你的网络线程池非常繁忙,你需要通过增加网络线程数或将负载转移给其他服务器的方式,来给该 Broker 减负。
RequestHandlerAvgIdlePercent:即 I/O 线程池线程平均的空闲比例。同样地,如果该值长期小于 30%,你需要调整 I/O 线程池的数量,或者减少 Broker 端的负载。
UnderReplicatedPartitions:即未充分备份的分区数。所谓未充分备份,是指并非所有的 Follower 副本都和 Leader 副本保持同步。一旦出现了这种情况,通常都表明该分区有可能会出现数据丢失。因此,这是一个非常重要的 JMX 指标。
ISRShrink/ISRExpand:即 ISR 收缩和扩容的频次指标。如果你的环境中出现 ISR 中副本频繁进出的情形,那么这组值一定是很高的。这时,你要诊断下副本频繁进出 ISR 的原因,并采取适当的措施。
ActiveControllerCount:即当前处于激活状态的控制器的数量。正常情况下,Controller 所在 Broker 上的这个 JMX 指标值应该是 1,其他 Broker 上的这个值是 0。如果你发现存在多台 Broker 上该值都是 1 的情况,一定要赶快处理,处理方式主要是查看网络连通性。这种情况通常表明集群出现了脑裂。脑裂问题是非常严重的分布式故障,Kafka 目前依托 ZooKeeper 来防止脑裂。但一旦出现脑裂,Kafka 是无法保证正常工作的。
如何配置Kafka的机器数据量、副本数和日志保存时间
Kafka机器数量(经验公式)=2(峰值生产速度副本数/100)+1
先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量。
比如我们的峰值生产速度是50M/s。副本数为2。
Kafka机器数量=2(502/100)+ 1=3台
数据副本数一般我们设置成2个或3个,很多企业设置为2个。
副本的优势:提高可靠性;副本劣势:增加了网络IO传输。
日志默认保存7天;生产环境建议3天。
Kafka中数据量计算及硬盘大小确定
每天总数据量100g,每天产生1亿条日志, 10000万/24/60/60=1150条/每秒钟
平均每秒钟:1150条
低谷每秒钟:50条
高峰每秒钟:1150条*(2-20倍)=2300条-23000条
每条日志大小:0.5k-2k(取1k)
每秒多少数据量:2.0M - 20MB
每天的数据量100g * 2个副本 * 3天 / 70%
Kafka消息数据积压,Kafka消费能力不足怎么处理?
1)如果是Kafka消费能力不足,则可以考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数 = 分区数。(两者缺一不可)
2)如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间 < 生产速度),使处理的数据小于生产的数据,也会造成数据积压。
Kafka单条日志传输大小
Kafka对于消息体的大小默认为单条最大值是1M但是在我们应用场景中,常常会出现一条消息大于1M,如果不对Kafka进行配置。则会出现生产者无法将消息推送到Kafka或消费者无法去消费Kafka里面的数据,这时我们就要对Kafka进行以下配置:server.properties
replica.fetch.max.bytes:1048576 broker可复制的消息的最大字节数, 默认为1M
message.max.bytes:1000012 kafka 会接收单个消息size的最大限制, 默认为1M左右
注意:message.max.bytes必须小于等于replica.fetch.max.bytes,否则就会导致replica之间数据同步失败。
Kafka的分区分配策略
在 Kafka内部存在三种默认的分区分配策略:Range、RoundRobin和Sticky。
- Range是默认策略。Range是对每个Topic而言的(即一个Topic一个Topic分),首先对同一个Topic里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。然后用Partitions分区的个数除以消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。
例如:我们有10个分区,两个消费者(C1,C2),3个消费者线程,10 / 3 = 3而且除不尽。
C1-0 将消费 0, 1, 2, 3 分区
C2-0 将消费 4, 5, 6 分区
C2-1 将消费 7, 8, 9 分区
- RoundRobin策略:将所有主题分区组成TopicAndPartition列表,然后对TopicAndPartition列表按照hashCode进行排序,最后按照轮询的方式发给每一个消费线程。
如果同一个消费组内所有的消费者的订阅信息都是相同的,那么 RoundRobinAssignor 策略的分区分配会是均匀的。
举例,假设消费组中有 2 个消费者 c0 和 c1,都订阅了主题 t0 和 t1,并且每个主题都有 3 个分区,那么所订阅的所有分区可以标识为:t0p0、t0p1、t0p2、t1p0、t1p1、t1p2。最终的分配结果为:
- 消费者c0:t0p0、t0p2、t1p1
- 消费者c1:t0p1、t1p0、t1p2
如果同一个消费组内的消费者所订阅的信息是不相同的,那么在执行分区分配的时候就不是完全的轮询分配,有可能会导致分区分配的不均匀。如果某个消费者没有订阅消费组内的某个 Topic,那么在分配分区的时候此消费者将分配不到这个 Topic 的任何分区。
举例,假设消费组内有 3 个消费者 c0、c1和c2,它们共订阅了3个主题:t0、t1、t2,这3个主题分别有1、2、3个分区,即整个消费组订阅了 t0p0、t1p0、t1p1、t2p0、t2p1、t2p2 这 6 个分区。具体而言,消费者 c0 订阅的是主题 t0,消费者 c1 订阅的是主题 t0和 t1,消费者 c2 订阅的是主题 t0、t1和t2,那么最终的分配结果为:
- 消费者c0:t0p0
- 消费者c1:t1p0
- 消费者c2:t1p1、t2p0、t2p1、t2p2
可以看到 RoundRobinAssignor 策略也不是十分完美,这样分配其实并不是最优解,因为完全可以将分区 t1p1 分配给消费者 c1。
- “Sticky”这个单词可以翻译为“粘性的”,Kafka从0.11.x版本开始引入这种分配策略,它主要有两个目的:
分区的分配要尽可能的均匀。
分区的分配尽可能的与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标。鉴于这两个目标,StickyAssignor 策略的具体实现要比 RangeAssignor 和 RoundRobinAssignor 这两种分配策略要复杂很多。
我们举例来看一下 StickyAssignor 策略的实际效果。
假设消费组内有 3 个消费者:c0、c1 和 c2,它们都订阅了4个主题:t0、t1、t2、t3,并且每个主题有 2 个分区,也就是说整个消费组订阅了 t0p0、t0p1、t1p0、t1p1、t2p0、t2p1、t3p0、t3p1 这 8 个分区。最终的分配结果如下:
-
消费者c0:t0p0、t1p1、t3p0
-
消费者c1:t0p1、t2p0、t3p1
-
消费者c2:t1p0、t2p1
这样初看上去似乎与采用 RoundRobinAssignor 策略所分配的结果相同,但事实是否真的如此呢?再假设此时消费者 c1 脱离了消费组,那么消费组就会执行再平衡操作,进而消费分区会重新分配。如果采用 RoundRobinAssignor 策略,那么此时的分配结果如下: -
消费者c0:t0p0、t1p0、t2p0、t3p0
-
消费者c2:t0p1、t1p1、t2p1、t3p1
如分配结果所示,RoundRobinAssignor 策略会按照消费者 c0和 c2 进行重新轮询分配。
而如果此时使用的是 StickyAssignor 策略,那么分配结果为:
- 消费者c0:t0p0、t1p1、t3p0、t2p0
- 消费者c2:t1p0、t2p1、t0p1、t3p1
可以看到分配结果中保留了上一次分配中对于消费者 c0 和 c2 的所有分配结果,并将原来消费者 c1 的“负担”分配给了剩余的两个消费者 c0 和 c2,最终 c0 和 c2 的分配还保持了均衡。
如果发生分区重分配,那么对于同一个分区而言有可能之前的消费者和新指派的消费者不是同一个,对于之前消费者进行到一半的处理还要在新指派的消费者中再次复现一遍,这显然很浪费系统资源。
StickyAssignor 策略如同其名称中的“sticky”一样,让分配策略具备一定的“粘性”,尽可能地让前后两次分配相同,进而减少系统资源的损耗以及其它异常情况的发生。
到目前为止所分析的都是消费者的订阅信息都是相同的情况,我们来看一下订阅信息不同的情况下的处理。
举例,同样消费组内有 3 个消费者:c0、c1 和 c2,集群中有3个主题:t0、t1 和 t2,这3个主题分别有 1、2、3 个分区,也就是说集群中有 t0p0、t1p0、t1p1、t2p0、t2p1、t2p2 这 6 个分区。消费者 c0 订阅了主题 t0,消费者 c1 订阅了主题 t0 和 t1,消费者 c2 订阅了主题 t0、t1 和 t2。
如果此时采用 RoundRobinAssignor 策略,那么最终的分配结果如下所示(和讲述RoundRobinAssignor策略时的一样,这样不妨赘述一下):
-
消费者c0:t0p0
-
消费者c1:t1p0
-
消费者c2:t1p1、t2p0、t2p1、t2p2
如果此时采用的是 StickyAssignor 策略,那么最终的分配结果为: -
消费者C0:t0p0
-
消费者C1:t1p0、t1p1
-
消费者C2:t2p0、t2p1、t2p2
可以看到这是一个最优解(消费者 c0 没有订阅主题 t1 和t2,所以不能分配主题 t1 和 t2 中的任何分区给它,对于消费者 c1 也可同理推断)。
假如此时消费者c0脱离了消费组,那么RoundRobinAssignor策略的分配结果为:
- 消费者c1:t0p0、t1p1
- 消费者c2:t1p0、t2p0、t2p1、t2p2
可以看到 RoundRobinAssignor 策略保留了消费者 c1 和 c2 中原有的 3 个分区的分配:t2p0、t2p1 和 t2p2(针对结果集1)。
而如果采用的是StickyAssignor策略,那么分配结果为:
- 消费者C1:t1p0、t1p1、t0p0
- 消费者C2:t2p0、t2p1、t2p2
可以看到 StickyAssignor 策略保留了消费者 c1 和 c2 中原有的 5 个分区的分配:t1p0、t1p1、t2p0、t2p1、t2p2。
从结果上看 StickyAssignor 策略比另外两者分配策略而言显得更加的优异,这个策略的代码实现也是异常复杂。
Kafka中有那些配置参数比较有意思?聊一聊你的看法
Kafka中有那些命名比较有意思?聊一聊你的看法
Kafka有哪些指标需要着重关注?
参考:
《深入理解kafka:核心设计与实践原理》
《Java核心面试知识整理》
《1000道互联网大厂java面试题》
http://www.vipshare8.com/wechat/406.html
https://www.cnblogs.com/x-x-736880382/p/11511221.html
https://mp.weixin.qq.com/s/MMNV78WfLCW4jhWT6FO5HQ
https://mp.weixin.qq.com/s/zH5LUO_C6lgMpa3EfDoaLw
https://mp.weixin.qq.com/s/LAXrK6WT1bv7I63BmvpXQg
https://mp.weixin.qq.com/s/j03gU5DxcgAmfZOKtoUziA
https://mp.weixin.qq.com/s/vgN55zHHsDcHuqPMzbiWCQ
https://blog.csdn.net/qq_28900249/article/details/90346599
https://mp.weixin.qq.com/s/YyrvNwwS1EcUpfhK73OV7w