前言
Spark 提供的 webui 已经提供了很多信息,用户可以从上面了解到任务的 shuffle,任务运行等信息,但是运行时 Executor JVM 的状态对用户来说是个黑盒,
在应用内存不足报错时,初级用户可能不了解程序究竟是 Driver 还是 Executor 内存不足,从而也无法正确的去调整参数。
Spark 的度量系统提供了相关数据,我们需要做的只是将其采集并展示。
安装graphite_exporter
注:只需要在Spark的master节点上安装它
-
上传解压
从 https://github.com/prometheus/graphite_exporter 下载并上传graphite_exporter-0.6.2.linux-amd64.tar安装包并解压到/usr/local目录
tar -xvf graphite_exporter-0.6.2.linux-amd64.tar cd graphite_exporter-0.6.2.linux-amd64/
-
配置
上传graphite_exporter_mapping配置文件到../graphite_exporter-0.6.2.linux-amd64/目录下
graphite_exporter_mapping内容:


mappings: - match: '*.*.executor.filesystem.*.*' name: spark_app_filesystem_usage labels: application: $1 executor_id: $2 fs_type: $3 qty: $4 - match: '*.*.jvm.*.*' name: spark_app_jvm_memory_usage labels: application: $1 executor_id: $2 mem_type: $3 qty: $4 - match: '*.*.executor.jvmGCTime.count' name: spark_app_jvm_gcTime_count labels: application: $1 executor_id: $2 - match: '*.*.jvm.pools.*.*' name: spark_app_jvm_memory_pools labels: application: $1 executor_id: $2 mem_type: $3 qty: $4 - match: '*.*.executor.threadpool.*' name: spark_app_executor_tasks labels: application: $1 executor_id: $2 qty: $3 - match: '*.*.BlockManager.*.*' name: spark_app_block_manager labels: application: $1 executor_id: $2 type: $3 qty: $4 - match: '*.*.DAGScheduler.*.*' name: spark_app_dag_scheduler labels: application: $1 executor_id: $2 type: $3 qty: $4 - match: '*.*.CodeGenerator.*.*' name: spark_app_code_generator labels: application: $1 executor_id: $2 type: $3 qty: $4 - match: '*.*.HiveExternalCatalog.*.*' name: spark_app_hive_external_catalog labels: application: $1 executor_id: $2 type: $3 qty: $4 - match: '*.*.*.StreamingMetrics.*.*' name: spark_app_streaming_metrics labels: application: $1 executor_id: $2 app_name: $3 type: $4 qty: $5
上述文件会将数据转化成 metric name 为 jvm_memory_usage,label 为 application,executor_id,mem_type,qty 的格式
application_1533838659288_1030_1_jvm_heap_usage -> jvm_memory_usage{application="application_1533838659288_1030",executor_id="driver",mem_type="heap",qty="usage"}
-
启动
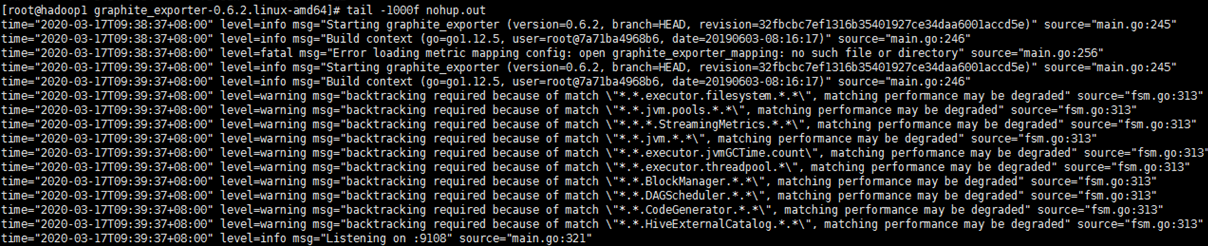
进入根目录下,输入以下命令:
cd /usr/local/graphite_exporter-0.6.2.linux-amd64/ nohup ./graphite_exporter --graphite.mapping-config=graphite_exporter_mapping & #启动 graphite_exporter 时加载配置文件 tail -1000f nohup.out
Spark 配置
-
配置
注:spark 集群下的所有节点都要进行如下配置
进入$SPARK_HOME/conf/目录下,修改metrics.properties 配置文件:
cp metrics.properties.template metrics.properties
vi metrics.properties
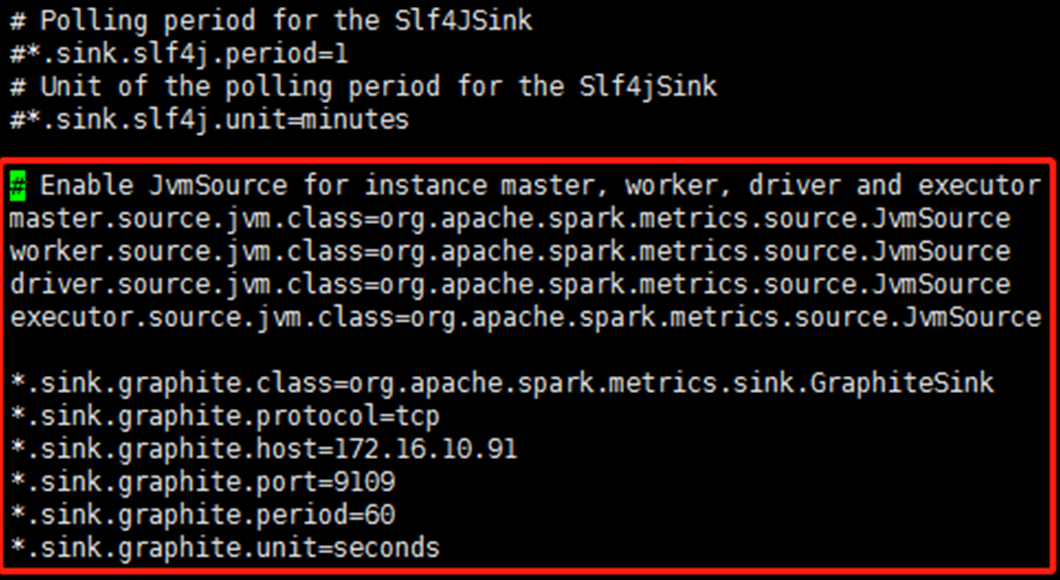
# Enable JvmSource for instance master, worker, driver and executor master.source.jvm.class=org.apache.spark.metrics.source.JvmSource worker.source.jvm.class=org.apache.spark.metrics.source.JvmSource driver.source.jvm.class=org.apache.spark.metrics.source.JvmSource executor.source.jvm.class=org.apache.spark.metrics.source.JvmSource *.sink.graphite.class=org.apache.spark.metrics.sink.GraphiteSink *.sink.graphite.protocol=tcp *.sink.graphite.host=172.16.10.91 # 部署graphite_exporter服务地址 *.sink.graphite.port=9109 # graphite_exporter服务默认端口9109 *.sink.graphite.period=60 *.sink.graphite.unit=seconds
-
启动spark集群
进入Spark 的 Master 节点服务器来启动集群
cd /usr/local/spark-2.3.3-bin-hadoop2.7/sbin ./start-all.sh
- 启动应用
spark-submit --class org.apache.spark.examples.SparkPi --name SparkPi --master yarn --deploy-mode cluster --executor-memory 1G --executor-cores 1 --num-executors 1 /usr/hdp/2.6.2.0-205/spark2/examples/jars/spark-examples_2.11-2.1.1.2.6.2.0-205.jar 1000
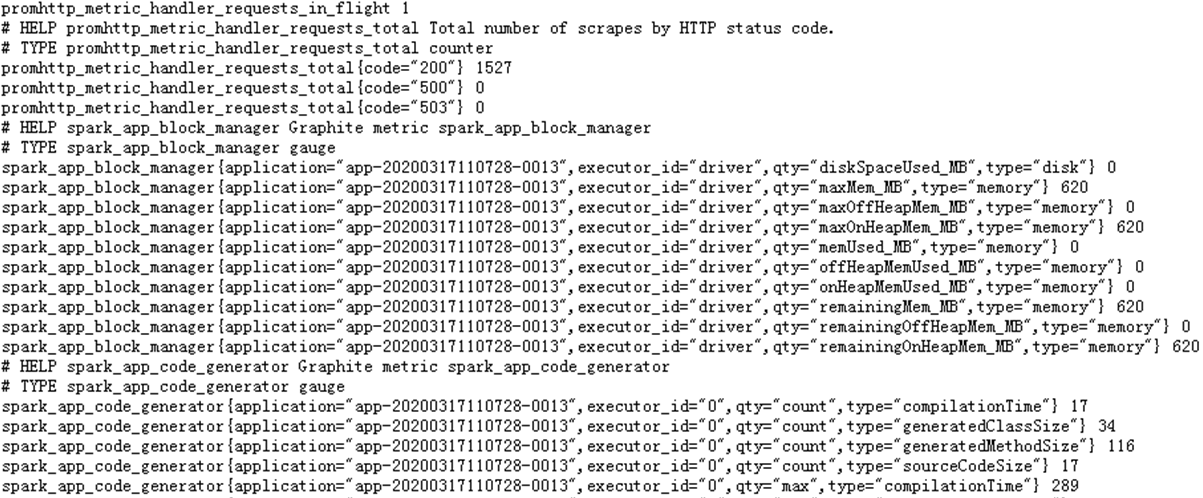
启动成功后,打开(graphite_exporter)服务地址查看收集的指标信息:
http://172.xx.xx.91:9108/metrics
Prometheus配置
-
配置
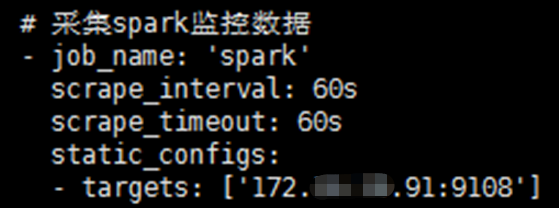
修改prometheus组件的prometheus.yml加入spark监控:
vi /usr/local/prometheus-2.15.1/prometheus.yml
-
启动验证
先kill掉Prometheus进程,用以下命令重启它,然后查看targets:
cd /usr/local/prometheus-2.15.1 nohup ./prometheus --config.file=prometheus.yml &
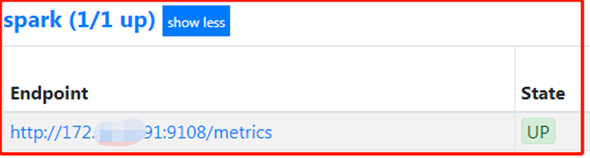
注:State=UP,说明成功
Grafana配置
-
导入仪表盘模板
导入附件提供的模板文件(Spark-dashboard.json)
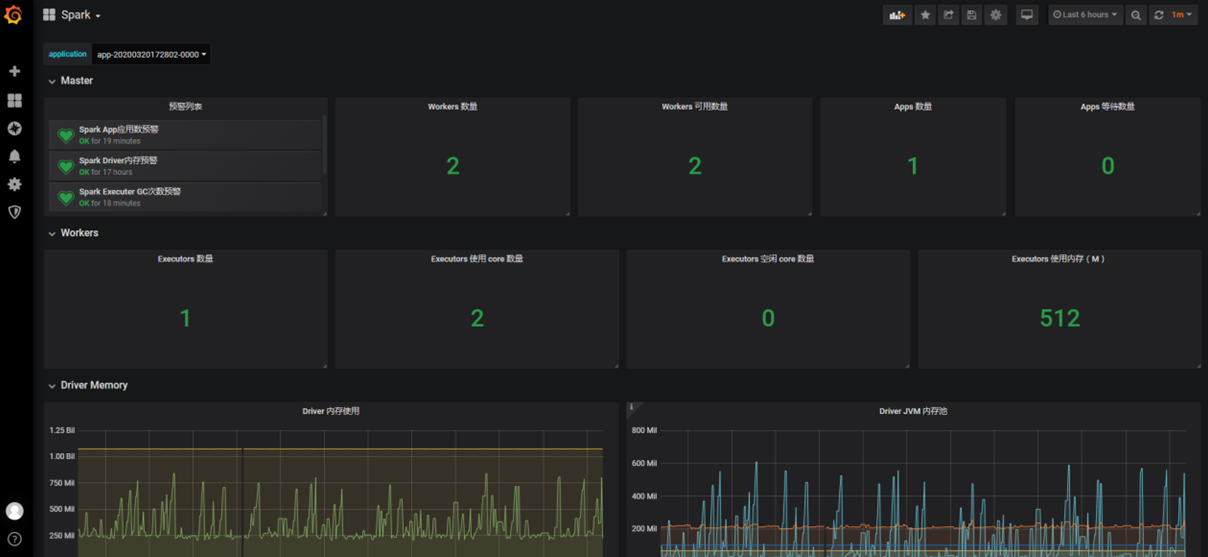
-
预警指标
|
序号 |
预警名称 |
预警规则 |
描述 |
|
1 |
Worker节点数预警 |
当集群中的Worker节点数达到阈值【<2】时进行预警 |
|
|
2 |
App 应用数预警 |
当集群中的App数量达到阈值【<1】时进行预警 |
|
|
3 |
Driver内存预警 |
当内存使用达到阈值【>80%】时进行预警 |
|
|
4 |
Executor内存预警 |
当内存使用达到阈值【>80%】时进行预警 |
|
|
5 |
Executor Gc次数预警 |
当每秒Gc次数达到阈值【>5】时进行预警 |