Prometheus 是什么?
Prometheus是一套开源的监控&报警&时间序列数据库的组合,起始是由SoundCloud公司开发的。随着发展,越来越多公司和组织接受采用Prometheus,社区也十分活跃,他们便将它独立成开源项目,并且有公司来运作。google SRE的书内也曾提到跟他们BorgMon监控系统相似的实现是Prometheus。现在最常见的Kubernetes容器管理系统中,通常会搭配Prometheus进行监控。
Prometheus 的优点
- 非常少的外部依赖,安装使用超简单
- 已经有非常多的系统集成 例如:docker HAProxy Nginx JMX等等
- 服务自动化发现
- 直接集成到代码
- 设计思想是按照分布式、微服务架构来实现的
Prometheus 的特性
- 自定义多维度的数据模型
- 非常高效的存储 平均一个采样数据占 ~3.5 bytes左右,320万的时间序列,每30秒采样,保持60天,消耗磁盘大概228G。
- 强大的查询语句
- 轻松实现数据可视化
等等
Prometheus 属于一站式监控告警平台,依赖少,功能齐全。Prometheus 支持对云的或容器的监控,其他系统主要对主机监控。Prometheus 数据查询语句表现力更强大,内置更强大的统计函数。Prometheus 在数据存储扩展性以及持久性上没有 InfluxDB,OpenTSDB,Sensu 好。
Prometheus Server, 主要用于抓取数据和存储时序数据,另外还提供查询和 Alert Rule 配置管理。client libraries,用于对接 Prometheus Server, 可以查询和上报数据。push gateway ,用于批量,短期的监控数据的汇总节点,主要用于业务数据汇报等。各种汇报数据的 exporters ,例如汇报机器数据的 node_exporter, 汇报 MongoDB 信息的 MongoDB exporter 等等。用于告警通知管理的 alertmanager 。

从这个架构图,也可以看出 Prometheus 的主要模块包含, Server, Exporters, Pushgateway, PromQL, Alertmanager, WebUI 等。
它大致使用逻辑是这样:
- Prometheus server 定期从静态配置的 targets 或者服务发现的 targets 拉取数据。
- 当新拉取的数据大于配置内存缓存区的时候,Prometheus 会将数据持久化到磁盘(如果使用 remote storage 将持久化到云端)。
- Prometheus 可以配置 rules,然后定时查询数据,当条件触发的时候,会将 alert 推送到配置的 Alertmanager。
- Alertmanager 收到警告的时候,可以根据配置,聚合,去重,降噪,最后发送警告。
- 可以使用 API, Prometheus Console 或者 Grafana 查询和聚合数据。
- 下载 prometheus-2.0.0.linux-amd64.tar.gz
- http://download.csdn.net/download/fly910905/10130519
tar -zxvf prometheus-2.0.0.linux-amd64.tar.gzcd prometheus-2.0.0.linux-amd64.tar.gz./prometheus
global:scrape_interval: 15s # By default, scrape targets every 15 seconds.evaluation_interval: 15s # By default, scrape targets every 15 seconds.# scrape_timeout is set to the global default (10s).# Attach these labels to any time series or alerts when communicating with# external systems (federation, remote storage, Alertmanager).external_labels:monitor: 'codelab-monitor'# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.rule_files:# - "first.rules"# - "second.rules"# A scrape configuration containing exactly one endpoint to scrape:# Here it's Prometheus itself.scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: 'prometheus'# Override the global default and scrape targets from this job every 5 seconds.scrape_interval: 5s# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ['localhost:9090']- job_name: 'mydemo'# Override the global default and scrape targets from this job every 5 seconds.scrape_interval: 5smetrics_path: '/prometheus'# scheme defaults to 'http'.static_configs:- targets: ['192.168.60.207:8088']
- 最关键的配置就是targets,就是web应用的ip和端口
http://localhost:9090/targets
相对于Graphite这种产品,还是有不少优点的。最让我觉得不错的是非常优秀的写性能和读取性能,它数据结构实现和OpenTSDB是有相似之处,有兴趣可以看看这个文档。解密OpenTSDB的表存储优
Prometheus 的系统架构
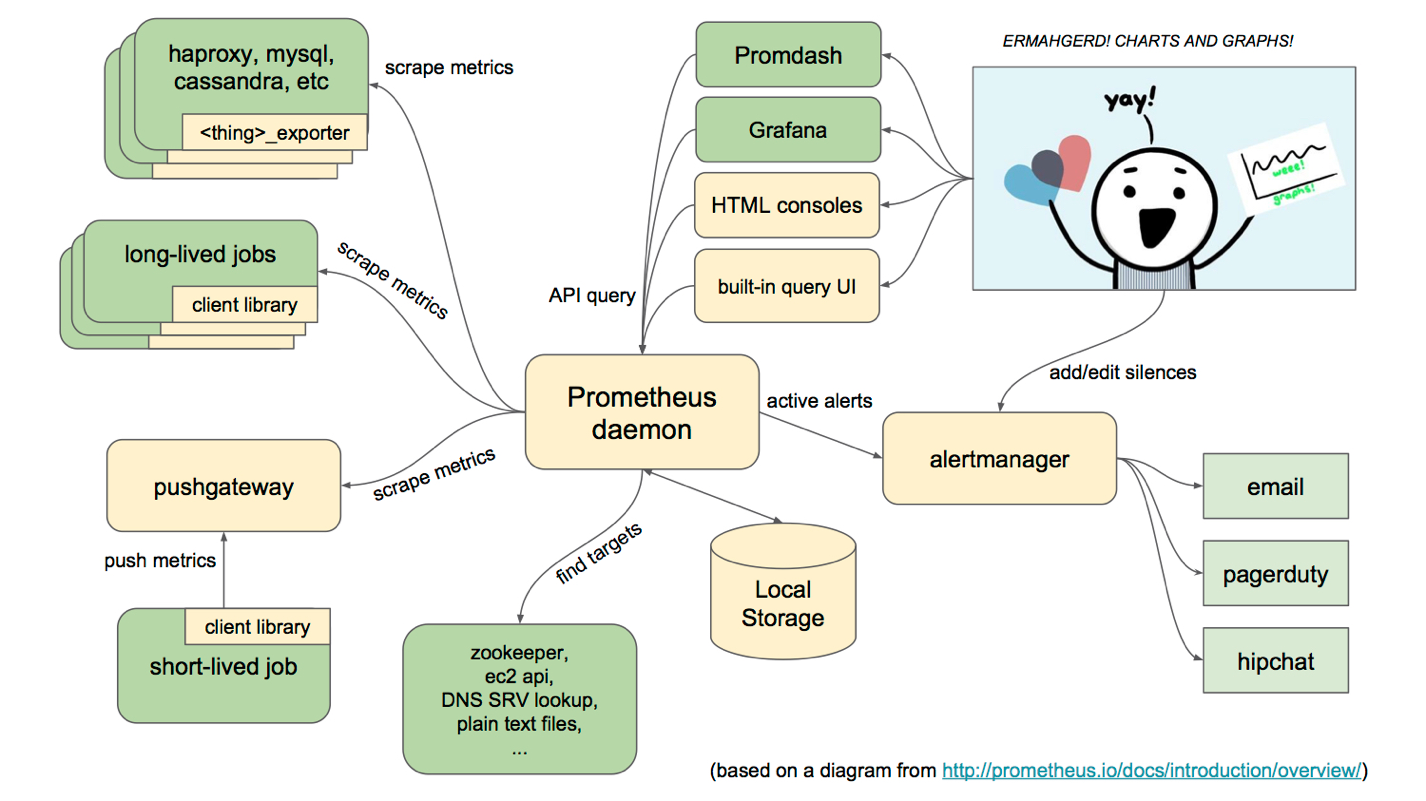
它的服务过程是这样的 Prometheus daemon 负责定时去目标上抓取 metrics(指标) 数据,每个抓取目标需要暴露一个http服务的接口给它定时抓取。Prometheus支持通过配置文件、文本文件、zookeeper、Consul、DNS SRV lookup等方式指定抓取目标。Alertmanager 是独立于Prometheus的一个组件,可以支持Prometheus的查询语句,提供十分灵活的报警方式。Prometheus支持很多方式的图表可视化,例如十分精美的Grafana,自带的Promdash,以及自身提供的模版引擎等等,还提供HTTP API的查询方式,自定义所需要的输出。PushGateway这个组件是支持Client主动推送 metrics 到PushGateway,而Prometheus只是定时去Gateway上抓取数据。
如果有使用过statsd的用户,则会觉得这十分相似,只是statsd是直接发送给服务器端,而Prometheus主要还是靠进程主动去抓取。
Prometheus 的数据模型
Prometheus 从根本上所有的存储都是按时间序列去实现的,相同的 metrics(指标名称) 和 label(一个或多个标签) 组成一条时间序列,不同的label表示不同的时间序列。为了支持一些查询,有时还会临时产生一些时间序列存储。
metrics name & label 指标名称和标签
每条时间序列是由唯一的 指标名称 和 一组 标签 (key=value)的形式组成。指标名称 一般是给监测对像起一名字,例如 http_requests_total 这样,它有一些命名规则,可以包字母数字_之类的的。通常是以应用名称开头_监测对像_数值类型_单位这样。例如:
- push_total
- userlogin_mysql_duration_seconds
- app_memory_usage_bytes
标签 就是对一条时间序列不同维度的识别了,例如 一个http请求用的是POST还是GET,它的endpoint是什么,这时候就要用标签去标记了。最终形成的标识便是这样了
http_requests_total{method="POST",endpoint="/api/tracks"}
记住,针对http_requests_total这个metrics name 无论是增加标签还是删除标签都会形成一条新的时间序列。查询语句就可以跟据上面标签的组合来查询聚合结果了。如果以传统数据库的理解来看这条语句,则可以考虑 http_requests_total是表名,标签是字段,而timestamp是主键,还有一个float64字段是值了。(Prometheus里面所有值都是按float64存储)
Prometheus 的四种数据类型
Counter
- Counter 用于累计值,例如 记录 请求次数、任务完成数、错误发生次数。
- 一直增加,不会减少。
- 重启进程后,会被重置。
例如:http_response_total{method="GET",endpoint="/api/tracks"} 10010秒后抓取 http_response_total{method="GET",endpoint="/api/tracks"} 100
Gauge
- Gauge 常规数值,例如 温度变化、内存使用变化。
- 可变大,可变小。
- 重启进程后,会被重置
例如: memory_usage_bytes{host="master-01"} 100 < 抓取值memory_usage_bytes{host="master-01"} 30memory_usage_bytes{host="master-01"} 50memory_usage_bytes{host="master-01"} 80 < 抓取值
Histogram
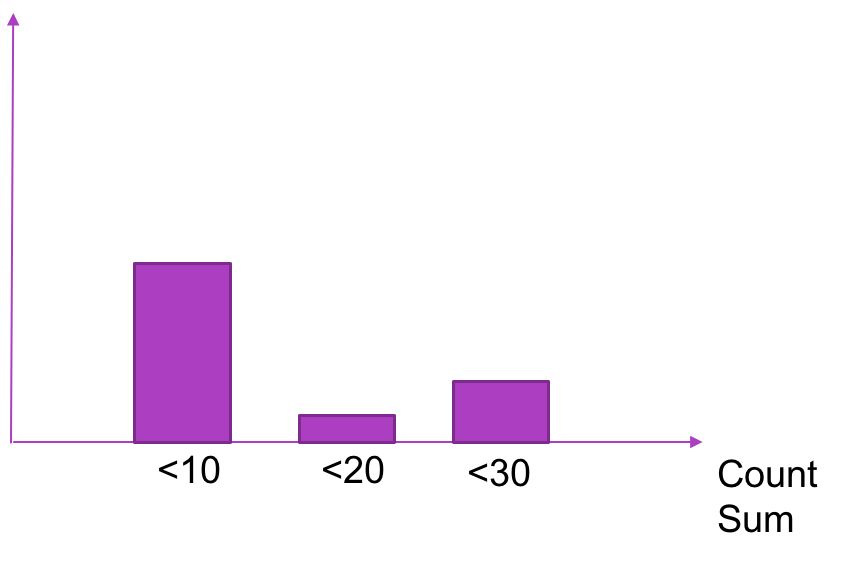
Histogram 可以理解为柱状图的意思,常用于跟踪事件发生的规模,例如:请求耗时、响应大小。它特别之处是可以对记录的内容进行分组,提供 count 和 sum 全部值的功能。
例如:{小于10=5次,小于20=1次,小于30=2次},count=7次,sum=7次的求和值
Summary
- Summary和Histogram十分相似,常用于跟踪事件发生的规模,例如:请求耗时、响应大小。同样提供 count 和 sum 全部值的功能。
- 例如:count=7次,sum=7次的值求值
- 它提供一个quantiles的功能,可以按%比划分跟踪的结果。例如:quantile取值0.95,表示取采样值里面的95%数据。
简介
prometheus 是一个开源的系统监控和告警的工具包,其采用pull方式采集时间序列,通过http协议传输。
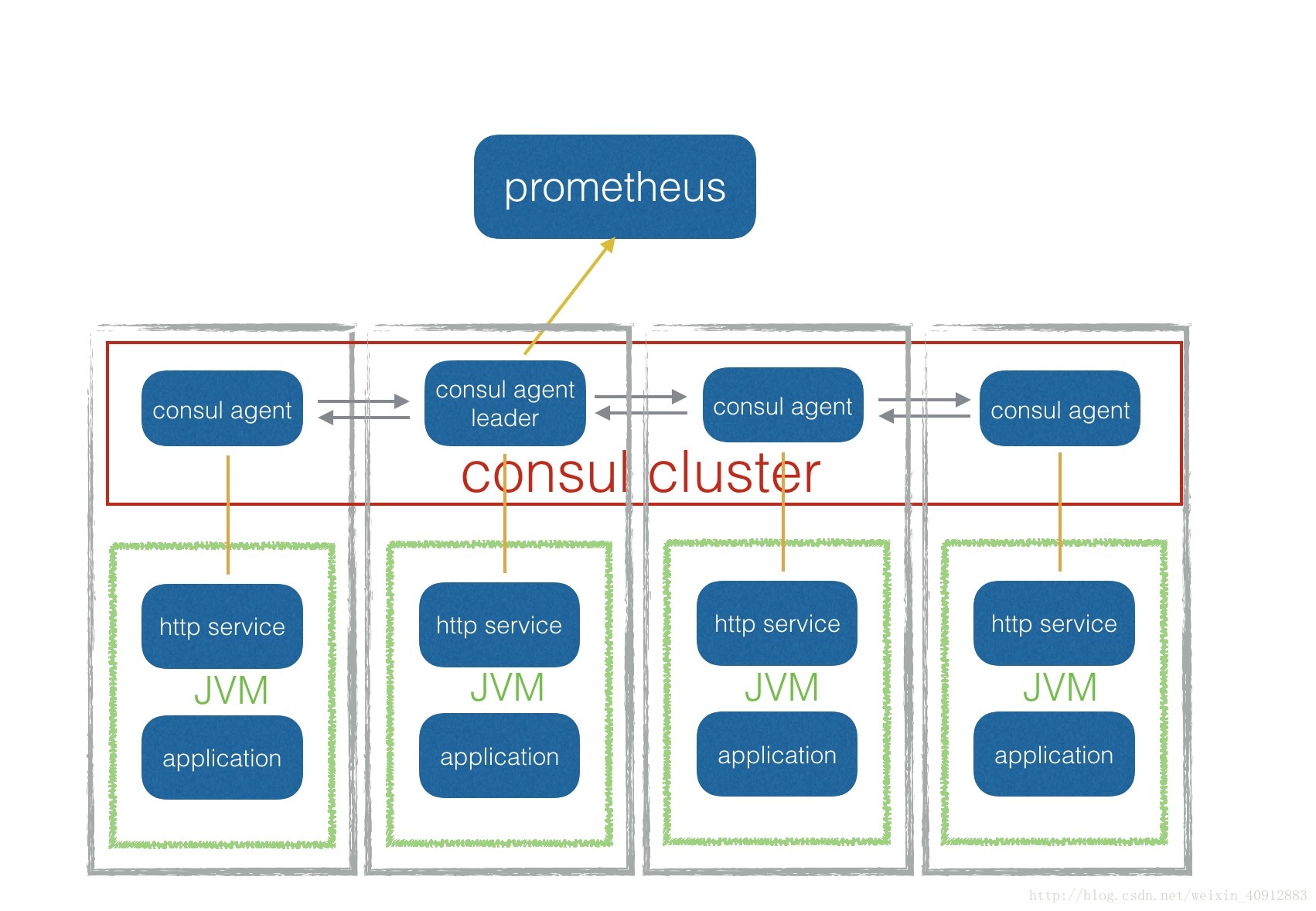
架构
每个应用都通过javaagent向外提供一个http服务暴露出自己的JMX信息。当应用启动的时候就会向consul注册服务,注册成功后,prometheus就能把这个应用加入监控对象列表,进行数据收集并跟踪服务的状态。
部署
prometheus
官网下载prometheus-1.2.1.linux-amd64.tar.gz, 解压到/services/apps/目录下,修改配置文件 prometheus.yml,在 scrape_config节点下增加以下内容:
- job_name: 'consul-node'
consul_sd_configs:
- server: 'localhost:8500'
services: ['scorer','file-proxy','....']- 1
- 2
- 3
- 4
services如果不配置默认会显示出所有的服务,包含了consul agent服务。
运行,默认端口9090
./prometheus -config.file=prometheus.yml &- 1
prometheus jmx exporter
jmx exporter是prometheus和JMX的桥梁。
在我们的工程里面,它是以Java Agent的方式运行,它的功能是收集本地的JVM信息,并通过HTTP服务暴露出来。引用的方式为:
1. 在pom.xml中增加依赖
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>jmx_prometheus_javaagent</artifactId>
<version>0.7</version>
</dependency> - 1
- 2
- 3
- 4
- 5
该工程已经把consul的服务注册功能整合进去。没有注销服务功能。
2. 增加启动参数
-javaagent:${WORK_DIR}/lib/jmx_prometheus_javaagent-0.7.jar=scorer:1234:${WORK_DIR}/bin/scorer.yaml- 1
javaagent参数解释如下:
-javagent:path/agent.jar=serviceName:servicePort:path/conf.yaml- 1
service 指的是http service,如指定servicePort为1234,在应用启动之后,可以在http://host:1234/metrics获取到metrics信息。在conf.yaml里配置JMX的收集策略,完整的yaml配置。
consul agent
prometheus可以静态的配置监控对象,也可以采用动态的服务发现机制。为了部署更方便,我们采用的是现在更为流行的服务发现解决方案consul。其只包含了一个二进制的命令文件,把它拷贝到PATH( echo $PATH 可以查看 )就可以运行。
运行命令为:
consul agent -server -data-dir data &- 1
解释如下:
consul agent 启动一个consul agent进程。 该进程负责维护集群成员信息、注册服务、运行检查、查询响应等等。而且,consul集群的每一个节点上都必须有agent进程运行。
-server **agent有两种模式:server与client。**server模式包含了一致性的工作:保证一致性和可用性(在部分失败的情况下),响应RPC,同步数据到其他节点代理。client 模式用于与server进行通信,转发RPC到服务的代理agent,它仅保存自身的少量一些状态,是非常轻量化的东西。本身是相对无状态的。
-data-dir 指定一个文件夹用于存储该agent的状态,在以server模式运行时,尤其重要。
一些其他的可选参数
- -node 指定该节点的名称,默认为主机名
- -http-port 指定端口接收http请求,用于默认端口8500被占用的情况。
- -config-dir 指定一个或多个文件夹用于agent启动时加载配置文件,加载顺序由文件名的字母顺序决定。
consul 运行起来后,server会通过8500端口与prometheus通信。
使用
consul 启动
consul agent -server –data-dir=/services/data/consul/ –join 10.18.1.12&
注销服务
curl http://localhost:8500/v1/agent/service/deregister/172.17.42.1
查询该agent上面注册的服务
curl http://localhost:8500/v1/agent/services?pretty
查询集群上面所有的服务
curl http://localhost:8500/v1/catalog/services?pretty
查询
参见prometheus官网提供的查询表达式,简而言之,标签过滤用{},时间范围选择用[],如下例。
http_request_total{job="prometheus"}[5m]- 1
可视化
prometheus官方的dashboard不怎么给力,目前将grafana集成了进去。grafana可以自定义数据源,并且保存多个dashboard,针对不同的系统可以使用不同的dashboard来进行监控。