图数据库 JanusGraph


知识图谱
###1.什么是知识图谱
知识图谱:是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
###2.知识图谱应用
知识图谱的应用场景非常广泛:
- 场景一 新闻事件的关联分析
- 场景二 识别反欺诈潜在风险
- 场景三 不一致性验证识别
- 场景四 失联客户管理
- 场景五 知识图谱的可视化展示
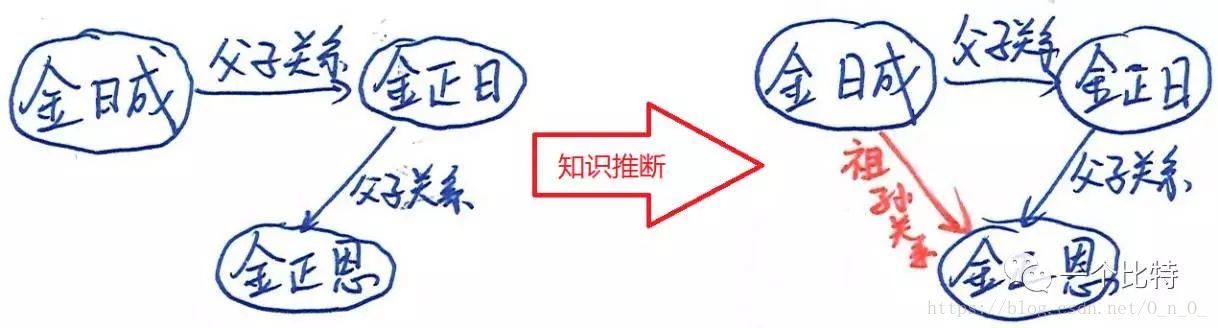
知识图谱可以自动推断出新的知识。假设下图左侧是原始的知识图谱,根据两层父子关系,图谱可以自动推断出缺失的祖孙关系,正所谓“爸爸的爸爸是爷爷”。
图数据库
图形数据库:是NoSQL数据库的一种类型,它应用图形理论存储实体之间的关系信息。
最常见例子就是社会网络中人与人之间的关系。关系型数据库用于存储“关系型”数据的效果并不好,其查询复杂、缓慢、超出预期,而图形数据库的独特设计恰恰弥补了这个缺陷。
图具有如下特征
包含节点和边;
- 节点上有属性(键值对);
- 边有名字和方向,并总是有一个开始节点和一个结束节点;
- 边也可以有属性;
| 图数据库名称 | 来源 | 了解 |
|---|---|---|
| Neo4j | 开源图形数据库 | 单机性能明显,企业版是集群模式(非分布式) |
| JanusGraph | 开源的分布式图数据库 | 好拓展,支持高并发复杂实时图遍历,支持多存储后端,支持多索引后端,支持事务 |
| OrientDB | 开源分布式图形-文档混合数据库 | 从社区的评论来看,性能和可扩展性是个问题,缺乏对纯图形操作的针对性 |
| ArangoDB | 多模型数据库 | 插入性能低,相关文档很少 ,对spark支持少 |
| HugeGraph | 百度开源图数据库 | 2018.8月发布,中文文档,与janusgraph 很相似,但不支持全文索引(见下图) |
JanusGraph简介
JanusGraph是一个可扩展的图数据库,可以把包含数千亿个顶点和边的图存储在多机集群上。它支持事务,支持数千用户实时、并发访问存储在其中的图。
我们可以将图数据库系统的应用领域划分成以下两部分:
用于联机事务图的持久化技术(通常直接实时地从应用程序中访问)。这类技术被称为图数据库,它们和“通常的”关系型数据库世界中的联机事务处理(Online Transactional Processing,OLTP)数据库是一样的。
用于离线图分析的技术(通常都是按照一系列步骤执行)。这类技术被称为图计算引擎。它们可以和其他大数据分析技术看做一类,如数据挖掘和联机分析处理(Online Analytical Processing,OLAP)。
JanusGraph的功能
JanusGraph最大的一个好处就是:可以扩展图数据的处理,能支持实时图遍历和分析查询(Scaling graph data processing for real time traversals and analytical queries is JanusGraph’s foundational benefit.)。
因为JanusGraph是分布式的,可以自由的扩展集群节点的,因此,它可以利用很大的集群,也就可以存储很大的包含数千亿个节点和边的图。由于它又支持实时、数千用户并发遍历图和分析查询图的功能。所以这两个特点是它显著的优势。
它支持以下功能:
(1)分布式部署,因此,支持集群。
(2)可以存储大图,比如包含数千亿Vertices和edges的图。
(3)支持数千用户实时、并发访问。
(4)集群节点可以线性扩展,以支持更大的图和更多的并发访问用户。
(5)数据分布式存储,并且每一份数据都有多个副本,因此,有更好的计算性能和容错性。
(6)支持在多个数据中心做高可用,支持热备份。
(7)支持各种后端存储系统,目前标准支持以下四种,当然也可以增加第三方的存储系统:
- Apache Cassandra®
- Apache HBase®
- Google Cloud Bigtable
- Oracle BerkeleyDB
(8)通过集成大数据平台,比如Apache Spark、Apache Giraph、Apache Hadoop等,支持全局图数据分析、报表、ETL
(9)支持geo(Gene Expression Omnibus,基因数据分析)、numeric range(这个的含义不清楚)
(10) 集成ElasticSearch、Apache Solr、Apache Lucene等系统后,可以支持全文搜索。
(11) 原生集成Apache TinkerPop图技术栈,包括Gremlin graph query language、Gremlin graph server、Gremin applications。
(12) 开源,基于Apache 2 Licence。
(13) 通过使用以下系统可以可视化存储在JanusGraph中的图数据:
- Cytoscape
- Gephi plugin for Apache TinkerPop
- Graphexp
- KeyLines by Cambridge Intelligence
- Linkurious
Graph
- schema由edge labels, property keys和vertex labels组成
- 显式(推荐)或隐式创建
- 在使用过程中修改的,而且不会导致服务宕机,也不会拖慢查询速度
- 一个 Graph 用于一个 Scheam
- Schema Type首次创建时被赋予元素,且不能修改
Edge多样性:
- MULTI 在一对vertex间可以有任意多个同样label的edge
- SIMPLE 在一对vertex间最多只能有一个同样label的edge
- MANY2ONE 多对一
- ONE2MANY 一对多
- ONE2ONE 某verex中具有同样Label的edge,只能有最多一个incoming edge和最多一个outgoing edge
Vertex value的基数:
- SINGLE 每个KEY只允许一个VALUE (默认)
- LIST 以LIST形式保存VALUE,也即可以有重复值
- SET 以SET形式保存VALUE,不能有重复值
Property Key Data Type:
索引类型:
- Composite Index 通过一个或多个固定的key组合来获取Vertex Key或Edge Mixed Index
- Mixed Index 支持通过其中的任意key的组合查询Vertex或者Edge,使用灵活,效率要比Composite Index低,需要索引后端
第五章:数据模型
Chapter 5. Schema and Data Modeling
每个JanusGraph图都是由边标签(edge label)、属性key、顶点标签(vertex label)构成。JanusGraph图模型(schema)可以显示定义也可以隐示定义。在实际应用开发过程中图模型定义是强烈建议采用显示定义的。一个显示的图模型定义对构建一个稳定的图应用非常重要并且可以提升协同开发效率。值得注意的是,随着时间的推移图模型演进是不需要对图进行任何中断操作的。扩展图模型定义不会使查询变慢并且也不需要停机操作。
图元素(边、属性、顶点)在图中被第一次创建的时候其模型定义(即边标签、属性key、顶点标签)是需要明确指定的,并且指定后不可改变。这样更容易使模型保持稳定。
除了本章介绍的模型定义选项外,将在30章高级模型中继续讨论模型定义的优化选项。
5.1 边标签定义
5.1. Defining Edge Labels
连接2个顶点的边的标签被定义为这2个顶点之间的具体关联关系。例如顶点A和顶点B间的边的标签类型为朋友,则表明A、B两人之间存在友谊。
定义边标签需要在一个打开的图或者管理事物中调用makeEdgeLabel(String)方法,参数即为边标签名。边标签名在图中必须唯一。此方法返回一个允许定义其多样性边标签的生成器。多样性标签定义会约束所有该标签的边,也就是说,限制了两个顶点最多能够有多少条边。JanusGraph承认下面这些多样性约束:
边标签多样性
5.1.1. Edge Label Multiplicity
多样性设置
- 多对多(MULTI): 任意2个顶点相同标签的边允许有多条。换句话说,这种图是包含此类标签的多图。这在边的多样性上没有约束。
- 简单(SIMPLE): 任意2个顶点间相同边标签的边最多有一条,换句话说,这种图是包含此类标签的简单图。这确保任意2个顶点间这类边标签的边唯一。
- 多对一(MANY2ONE): 在图中此类边标签在任意顶点出边只能有一条,入边没有限制。++母亲++边标签就是这种多对一的例子,一个人只能有一个母亲,但是一个母亲可以有多个孩子。
- 一对多(ONE2MANY): 在图中此类边标签的边一个顶点只能有一个入边,出边不限制。++赢得比赛++边标签就是这样的例子,一场比赛最多只能被一个人赢得比赛,但是一个人可以赢得多场比赛。
- 一对一(ONE2ONE):在图中此类标签只能有一条入边和一条出边,++结婚++边标签就是这样的一对一的例子,表示一个人只能和另外一个人结婚。
默认的边多样性限制是多对多。在定义边标签的时候调用make()完成边标签定义并返回定义的边标签,就像下面这个例子。
mgmt = graph.openManagement()
follow = mgmt.makeEdgeLabel('follow').multiplicity(MULTI).make()
mother = mgmt.makeEdgeLabel('mother').multiplicity(MANY2ONE).make()
mgmt.commit()定义属性key
5.2. Defining Property Keys
边和顶点的属性是键值对,例如属性name='Daniel'具有属性键name,属性值Daniel。属性键是JanusGraph图模型的一部分并且只能是允许的数据类型和基准值。
定义属性性键,可以在打开的图或者管理事物上调用`makePropertyKey(String)方法,传递的参数就是图属性标签。图中属性key必须唯一,建议在图属性名中避免使用空格和特殊字符。这个方法返回一个图键构造器。
5.2.1属性key数据类型
5.2.1. Property Key Data Type
使用dataType(Class)定义属性key数据类型。JanusGraph将强制该属性key的数据的数据类型必须是这个方法定义的。这保证如图的数据都是有效的。例如可以定义namekey具有String类型。
数据类型定义为Object.class允许该key可以设置任何数据类型的值。然而,应尽量使用固定类型的值。配置的数据类型必须是具体的类,不能是结构和抽象类。JanusGraph强制类相等,所以配置数据类型是子类是不允许的。
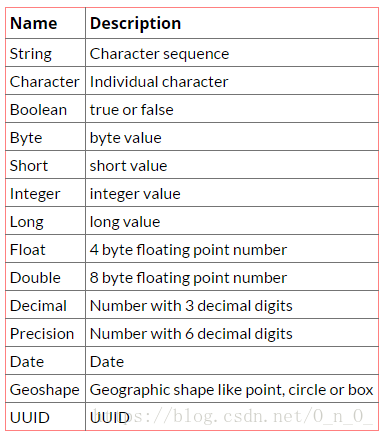
JanusGraph原生支持下面这些数据类型。
Table 5.1. Native JanusGraph Data Types
| Name | Description |
|---|---|
| String | Character sequence |
| Character | Individual character |
| Boolean | true or false |
| Byte | byte value |
| Short | short value |
| Integer | integer value |
| Long | long value |
| Float | 4 byte floating point number |
| Double | 8 byte floating point number |
| Date | Specific instant in time (java.util.Date) |
| Geoshape | Geographic shape like point, circle or box |
| UUID | Universally unique identifier (java.util.UUID) |
全局配置
JanusGraph区分本地和全局配置选项。本地配置选项适用于单个JanusGraph实例。全局配置选项适用于群集中的所有实例。更具体地说,JanusGraph区分了以下五个配置选项范围:
LOCAL:这些选项仅适用于单个JanusGraph实例,并在初始化JanusGraph实例时提供的配置中指定。
MASKABLE:可以通过本地配置文件为单个JanusGraph实例重写这些配置选项。如果本地配置文件未指定该选项,则从全局JanusGraph集群配置中读取其值。
GLOBAL:始终从群集配置中读取这些选项,并且不能在实例的基础上重写这些选项。
GLOBAL_OFFLINE:与 GLOBAL一样,但更改这些选项需要重新启动群集以确保整个群集中的值相同。
FIXED:与 GLOBAL一样,但是一旦初始化JanusGraph集群,就无法更改该值。
启动集群中的第一个JanusGraph实例时,将从本地配置文件初始化全局配置选项。随后,通过JanusGraph的管理API完成更改全局配置选项。要访问管理API,请在一个打开的JanusGraph instance handle g.上调用g.getManagementSystem()。例如,要更改JanusGraph集群上的默认缓存行为:
mgmt = graph.openManagement()
mgmt.get('cache.db-cache')
// Prints the current config setting
mgmt.set('cache.db-cache', true)
// Changes option
mgmt.get('cache.db-cache')
// Prints 'true'
mgmt.commit()
7 使用示例
7.1. Getting Started
7.1.1 使用默认包部署
7.1.1. Using the Pre-Packaged Distribution
JanusGraph发行版预先默认配置了Cassandra作为后端存储,Elasticsearch作为索引服务,以使用户能够快速的使用JanusGraph服务。这些默认配置允许客户端通过WebSocket协议连接到JanusGraph服务。已经有一些支持该协议的不同语言开发的客户端。大家都熟悉的使用WebSocket客户端就是Gremlin控制台。快速启动配置不代表生产安装配置,但是提供了一个快速试用JanusGraph服务的方法,运行测试、看各个组件是如何在一起工作的。
快速上手步骤:
从发布页面下载janusgraph-$VERSION.zip包 解压进入janusgraph-$VERSION目录 执行bin/janusgraph.sh start命令,这个步骤启动Gremlin服务同时分别启动Cassandra和ES,出于安全考虑,Elasticsearch要求执行janusgraph.sh脚本的时候必须是在非root账号下执行。
你可以在消息头加上token进行认证,例如:
curl -v http://localhost:8182/session -XPOST -d '{"gremlin": "g.V().count()"}' -H "Authorization: Token dXNlcjoxNTA5NTQ2NjI0NDUzOkhrclhYaGhRVG9KTnVSRXJ5U2VpdndhalJRcVBtWEpSMzh5WldqRTM4MW89"HMAC设计用户HTTP认证,首先调用/session接口获取token,该token默认一个小时过期。这个过期时间可以通过authentication.config配置组的tokenTimeout配置项修改,这个值是长整型,单位是毫秒。
通过调用/session获取token,例如:
curl http://localhost:8182/session -XGET -u user:password
{"token": "dXNlcjoxNTA5NTQ2NjI0NDUzOkhrclhYaGhRVG9KTnVSRXJ5U2VpdndhalJRcVBtWEpSMzh5WldqRTM4MW89"}7.6.3 HTTP和WebSocket同时启用认证
7.6.3. Authentication over HTTP and WebSocket
如果通信管道协议同时使用HTTP和WebSocket,可以使用SaslAndHMACAuthenticator进行认证,WebSocket使用的是SASL,HTTP使用的是基础认证,HTTP基于HASH消息的认证(HMAC)。HMAC是一种基于令牌的身份验证,设计用于HTTP。第一次使用的时候通过调用/session接口获取一个token,然后用这个token进行认证。这被用于分摊密码加密认证所花费的时间。
gremlin-server.yaml配置文件需要加如下配置:
authentication: {
authenticator: org.janusgraph.graphdb.tinkerpop.gremlin.server.auth.SaslAndHMACAuthenticator,
authenticationHandler: org.janusgraph.graphdb.tinkerpop.gremlin.server.handler.SaslAndHMACAuthenticationHandler,
config: {
defaultUsername: user,
defaultPassword: password,
hmacSecret: secret,
credentialsDb: conf/janusgraph-credentials-server.properties
}
}如果通过gremlin控制台连接,remote yaml文件需要添加username和password配置项,
username: user
password: password如果已启用认证配置,响应码会是200,返回值是4。
7.6.2 WebSocket认证
7.6.2. Authentication over WebSocket
WebSocket认证通过简单认证和安全层(SASL)机制实现。
启用SASL认证通过修改gremlin-server.yaml配置文件下面配置项实现。
authentication: {
authenticator: org.janusgraph.graphdb.tinkerpop.gremlin.server.auth.JanusGraphSimpleAuthenticator,
authenticationHandler: org.apache.tinkerpop.gremlin.server.handler.SaslAuthenticationHandler,
config: {
defaultUsername: user,
defaultPassword: password,
credentialsDb: conf/janusgraph-credentials-server.properties
}
}如果已经启用认证配置,将会返回401。
curl -v -XPOST http://localhost:8182 -d '{"gremlin": "g.V().count()"}' -u user:password验证基础认证配置生效。
curl -v -XPOST http://localhost:8182 -d '{"gremlin": "g.V().count()"}'7.6 JanusGraph服务高级配置
7.6. Advanced JanusGraph Server Configurations
7.6.1 使用HTTP协议需认证
7.6.1. Authentication over HTTP
在下面的例子中,你所使用的图认证数据库可能不一样,根据当前的后端存储选择合适的keyspace、table、存储目录。这个图将被用于存储用户名和密码。
7.6.1.1 HTTP基础认证
7.6.1.1. HTTP Basic authentication
启用JanusGraph服务基础认证需要在gremlin-server.yaml配置文件中加如下配置项。
authentication: {
authenticator: org.janusgraph.graphdb.tinkerpop.gremlin.server.auth.JanusGraphSimpleAuthenticator,
authenticationHandler: org.apache.tinkerpop.gremlin.server.handler.HttpBasicAuthenticationHandler,
config: {
defaultUsername: user,
defaultPassword: password,
credentialsDb: conf/janusgraph-credentials-server.properties
}
}7.5 JanusGraph服务同时支持WebSocket和HTTP
7.5. JanusGraph Server as Both a WebSocket and HTTP Endpoint
在JanusGraph0.2.0版本后,可以修改gremlin-server.yaml使在一个端口同时支持WebSocket和HTTP。这可以修改前面提到的channelizer配置项实现。
channelizer: org.apache.tinkerpop.gremlin.server.channel.WsAndHttpChannelizercurl -XPOST -Hcontent-type:application/json -d '{"gremlin":"g.V().count()"}' http://[IP for JanusGraph server host]:8182bin/gremlin-server.sh ./conf/gremlin-server/http-gremlin-server.yamlgraphs: {
graph: conf/gremlin-server/http-janusgraph-hbase-server.properties}channelizer: org.apache.tinkerpop.gremlin.server.channel.HttpChannelizerhost: 10.10.10.100cp conf/gremlin-server/gremlin-server.yaml conf/gremlin-server/http-gremlin-server.yamlcp conf/janusgraph-hbase.properties conf/gremlin-server/http-janusgraph-hbase-server.propertiesgremlin.graph=org.janusgraph.core.JanusGraphFactory注意: 不要使用bin/janusgraph.sh启动,这个启动脚本会启用默认配置使用本地Cassandra和Elasticsearch环境。
6. 至此JanusGraph服务已经跑在了WebSocket模式下,可以通过7.1.1.1节提到的方法进行测试了。
7.4JanusGraph服务启用HTTP协议
7.4. JanusGraph Server as a HTTP Endpoint
7.1节快速开始默认配置的协议是WebSocket,如果想更改配使JanusGraph服务支持HTTP协议,跟着下面步骤操作:
配置JanusGraph服务以支持HTTP协议
bin/gremlin-server.sh ./conf/gremlin-server/socket-gremlin-server.yamlgraphs: {
graph: conf/gremlin-server/socket-janusgraph-hbase-server.properties}host: 10.10.10.100cp conf/gremlin-server/gremlin-server.yaml conf/gremlin-server/socket-gremlin-server.yamlcp conf/janusgraph-hbase.properties conf/gremlin-server/socket-janusgraph-hbase-server.propertiesgremlin.graph=org.janusgraph.core.JanusGraphFactory7.3JanusGraph服务作为WebSocket终端
7.3. JanusGraph Server as a WebSocket Endpoint
在7.1节已经说明了默认WebSocket配置。如果你想更改配置以使用自己的Cassandra或者HBase环境,而不是快速上手的默认配置环境,跟着执行下面操作步骤:
配置JanusGraph服务以支持WebSocket
7.2清理部署程序包
7.2. Cleaning up after the Pre-Packaged Distribution
如果想删除数据库和日志使用一个干净的库,可以使用janusgraph.sh的clean命令,在执行clean命令前得先停止服务。
$ cd /Path/to/janusgraph/janusgraph-0.2.0-hadoop2/
$ ./bin/janusgraph.sh stop
Killing Gremlin-Server (pid 91505)...
Killing Elasticsearch (pid 91402)...
Killing Cassandra (pid 91219)...
$ ./bin/janusgraph.sh clean
Are you sure you want to delete all stored data and logs? [y/N] y
Deleted data in /Path/to/janusgraph/janusgraph-0.2.0-hadoop2/db
Deleted logs in /Path/to/janusgraph/janusgraph-0.2.0-hadoop2/log:remote命令告诉控制台使用conf/remote.yaml配置文件连接Gremlin服务端。这会触使连接到本地运行的Gremlin服务实例。:>提示服务下输入的命令将被发送到当前连接的远程gremlin服务上执行。默认情况下,远程连接是无状态的,意思就是说每一行命名都会被当做一个单独的请求进行提交。可以使用分号作为定界符在单行上发送多个语句。另外,在创建连接时,可以通过指定会话来建立具有会话的控制台。控制台会话允许您在多个输入行上重用变量。
gremlin> :remote connect tinkerpop.server conf/remote.yaml
==>Configured localhost/127.0.0.1:8182
gremlin> graph
==>standardjanusgraph[cql:[127.0.0.1]]
gremlin> g
==>graphtraversalsource[standardjanusgraph[cql:[127.0.0.1]], standard]
gremlin> g.V()
gremlin> user = "Chris"
==>Chris
gremlin> graph.addVertex("name", user)
No such property: user for class: Script21
Type ':help' or ':h' for help.
Display stack trace? [yN]
gremlin> :remote connect tinkerpop.server conf/remote.yaml session
==>Configured localhost/127.0.0.1:8182-[9acf239e-a3ed-4301-b33f-55c911e04052]
gremlin> g.V()
gremlin> user = "Chris"
==>Chris
gremlin> user
==>Chris
gremlin> graph.addVertex("name", user)
==>v[4344]
gremlin> g.V().values('name')
==>Chris7.1.1.1连接到Gremlin服务
7.1.1.1. Connecting to Gremlin Server
执行janusgraph.sh后,Gremlin将会监听WebSocket连接。最方便的测试连接的方式是使用Gremlin的控制台。
运行bin/gremlin.sh进入Gremlin控制台,使用:remote和:>命令在Gremlin控制台操作Gremlin服务端。
$ bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
plugin activated: tinkerpop.server
plugin activated: tinkerpop.hadoop
plugin activated: tinkerpop.utilities
plugin activated: janusgraph.imports
plugin activated: tinkerpop.tinkergraph
gremlin> :remote connect tinkerpop.server conf/remote.yaml
==>Connected - localhost/127.0.0.1:8182
gremlin> :> graph.addVertex("name", "stephen")
==>v[256]
gremlin> :> g.V().values('name')
==>stephen$ bin/janusgraph.sh start
Forking Cassandra...
Running `nodetool statusthrift`.. OK (returned exit status 0 and printed string "running").
Forking Elasticsearch...
Connecting to Elasticsearch (127.0.0.1:9300)... OK (connected to 127.0.0.1:9300).
Forking Gremlin-Server...
Connecting to Gremlin-Server (127.0.0.1:8182)... OK (connected to 127.0.0.1:8182).
Run gremlin.sh to connect.JanusGraph当前已经跑在HTTP模式下并且可以进行测试了。curl命令可以用于验证服务服务已正常工作。
指定刚刚的配置yaml配置文件,启动JanusGraph服务。
c. 修改新配置文件的graphs部分,以使JanusGraph服务能够找到并连接上JanusGraph实例。
b. 更新channelizer配置项为HttpChannelizer
更新http-gremlin-server.yaml配置文件的下面这些配置项:
a. 如果您打算从本地主机以外的其他设备连接到JanusGraph服务器,更新host的IP地址:
复制./conf/gremlin-server/gremlin-server.yaml到一个新的文件http-gremlin-server.yaml。如果需要引用文件的原始版本,请执行此操作。
一旦本地配置文件测试通过得到一个可正常工作的配置文件,复制./conf目录下的配置到./conf/gremlin-server目录。
首先尝试连接本地JanusGraph数据库,这一步可以在Gremlin客户端实现,也可以通过程序实现。在./conf目录下配置文件中做适当修改,例如编辑./conf/janusgraph-hbase.properties,确保storage.backend、storage.hostname、storage.hbase.table是被显示指定的。更多的JanusGraph后端存储配置请参考 第三章:后端存储。确保配置文件中包含下面配置项:
指定刚刚的配置yaml配置文件,启动JanusGraph服务。
b. 修改新配置文件的graphs部分,以使JanusGraph服务能够找到并连接上JanusGraph实例。
修改socket-gremlin-server.yaml配置中下面配置项。
a. 如果您打算从本地主机以外的其他设备连接到JanusGraph服务器,更新host的IP地址:
复制./conf/gremlin-server/gremlin-server.yaml重命名为socket-gremlin-server.yaml如果需要引用文件的原始版本,请执行此操作。
一旦本地配置文件测试通过得到一个可正常工作的配置文件,复制./conf目录下的配置到./conf/gremlin-server目录。
首先测试本地连接到JanusGraph数据库。这步可以使用Gremlin控制台实现也可以通过程序实现。更改你自己环境下./conf目录下的配置文件,例如,编辑./conf/janusgraph-hbase.properties配置文件,确认storage.backend、storage.hostname、storage.hbase.table这些参数被正确指定。- 更多的
JanusGraph后端存储配置请参考 第三章:后端存储。 - 示例:
import com.google.common.base.Preconditions;
import org.janusgraph.core.EdgeLabel;
import org.janusgraph.core.Multiplicity;
import org.janusgraph.core.PropertyKey;
import org.janusgraph.core.JanusGraphFactory;
import org.janusgraph.core.JanusGraph;
import org.janusgraph.core.JanusGraphTransaction;
import org.janusgraph.core.attribute.Geoshape;
import org.janusgraph.core.schema.ConsistencyModifier;
import org.janusgraph.core.schema.JanusGraphIndex;
import org.janusgraph.core.schema.JanusGraphManagement;
import org.janusgraph.graphdb.database.StandardJanusGraph;
import org.apache.tinkerpop.gremlin.process.traversal.Order;
import org.apache.tinkerpop.gremlin.structure.Direction;
import org.apache.tinkerpop.gremlin.structure.Edge;
import org.apache.tinkerpop.gremlin.structure.T;
import org.apache.tinkerpop.gremlin.structure.Vertex;
/**
* Example Graph factory that creates a {@link JanusGraph} based on roman mythology.
* Used in the documentation examples and tutorials.
*
* @author Marko A. Rodriguez (http://markorodriguez.com)
*/
public class GraphOfTheGodsFactory {
public static final String INDEX_NAME = "search";
private static final String ERR_NO_INDEXING_BACKEND =
"The indexing backend with name "%s" is not defined. Specify an existing indexing backend or " +
"use GraphOfTheGodsFactory.loadWithoutMixedIndex(graph,true) to load without the use of an " +
"indexing backend.";
public static JanusGraph create(final String directory) {
JanusGraphFactory.Builder config = JanusGraphFactory.build();
config.set("storage.backend", "cql");
config.set("storage.directory", directory);
config.set("index." + INDEX_NAME + ".backend", "elasticsearch");
JanusGraph graph = config.open();
GraphOfTheGodsFactory.load(graph);
return graph;
}
public static void loadWithoutMixedIndex(final JanusGraph graph, boolean uniqueNameCompositeIndex) {
load(graph, null, uniqueNameCompositeIndex);
}
public static void load(final JanusGraph graph) {
load(graph, INDEX_NAME, true);
}
private static boolean mixedIndexNullOrExists(StandardJanusGraph graph, String indexName) {
return indexName == null || graph.getIndexSerializer().containsIndex(indexName);
}
public static void load(final JanusGraph graph, String mixedIndexName, boolean uniqueNameCompositeIndex) {
if (graph instanceof StandardJanusGraph) {
Preconditions.checkState(mixedIndexNullOrExists((StandardJanusGraph)graph, mixedIndexName),
ERR_NO_INDEXING_BACKEND, mixedIndexName);
}
//Create Schema
JanusGraphManagement management = graph.openManagement();
final PropertyKey name = management.makePropertyKey("name").dataType(String.class).make();
JanusGraphManagement.IndexBuilder nameIndexBuilder = management.buildIndex("name", Vertex.class).addKey(name);
if (uniqueNameCompositeIndex)
nameIndexBuilder.unique();
JanusGraphIndex nameIndex = nameIndexBuilder.buildCompositeIndex();
management.setConsistency(nameIndex, ConsistencyModifier.LOCK);
final PropertyKey age = management.makePropertyKey("age").dataType(Integer.class).make();
if (null != mixedIndexName)
management.buildIndex("vertices", Vertex.class).addKey(age).buildMixedIndex(mixedIndexName);
final PropertyKey time = management.makePropertyKey("time").dataType(Integer.class).make();
final PropertyKey reason = management.makePropertyKey("reason").dataType(String.class).make();
final PropertyKey place = management.makePropertyKey("place").dataType(Geoshape.class).make();
if (null != mixedIndexName)
management.buildIndex("edges", Edge.class).addKey(reason).addKey(place).buildMixedIndex(mixedIndexName);
management.makeEdgeLabel("father").multiplicity(Multiplicity.MANY2ONE).make();
management.makeEdgeLabel("mother").multiplicity(Multiplicity.MANY2ONE).make();
EdgeLabel battled = management.makeEdgeLabel("battled").signature(time).make();
management.buildEdgeIndex(battled, "battlesByTime", Direction.BOTH, Order.decr, time);
management.makeEdgeLabel("lives").signature(reason).make();
management.makeEdgeLabel("pet").make();
management.makeEdgeLabel("brother").make();
management.makeVertexLabel("titan").make();//太阳神
management.makeVertexLabel("location").make();//场景
management.makeVertexLabel("god").make();//上帝
management.makeVertexLabel("demigod").make();//小神
management.makeVertexLabel("human").make();//人类
management.makeVertexLabel("monster").make();//怪物
management.commit();
JanusGraphTransaction tx = graph.newTransaction();
// vertices
Vertex saturn = tx.addVertex(T.label, "titan", "name", "saturn", "age", 10000);
Vertex sky = tx.addVertex(T.label, "location", "name", "sky");
Vertex sea = tx.addVertex(T.label, "location", "name", "sea");
Vertex jupiter = tx.addVertex(T.label, "god", "name", "jupiter", "age", 5000);
Vertex neptune = tx.addVertex(T.label, "god", "name", "neptune", "age", 4500);
Vertex hercules = tx.addVertex(T.label, "demigod", "name", "hercules", "age", 30);
Vertex alcmene = tx.addVertex(T.label, "human", "name", "alcmene", "age", 45);
Vertex pluto = tx.addVertex(T.label, "god", "name", "pluto", "age", 4000);
Vertex nemean = tx.addVertex(T.label, "monster", "name", "nemean");
Vertex hydra = tx.addVertex(T.label, "monster", "name", "hydra");
Vertex cerberus = tx.addVertex(T.label, "monster", "name", "cerberus");
Vertex tartarus = tx.addVertex(T.label, "location", "name", "tartarus");
// edges
jupiter.addEdge("father", saturn);
jupiter.addEdge("lives", sky, "reason", "loves fresh breezes");
jupiter.addEdge("brother", neptune);
jupiter.addEdge("brother", pluto);
neptune.addEdge("lives", sea).property("reason", "loves waves");
neptune.addEdge("brother", jupiter);
neptune.addEdge("brother", pluto);
hercules.addEdge("father", jupiter);
hercules.addEdge("mother", alcmene);
hercules.addEdge("battled", nemean, "time", 1, "place", Geoshape.point(38.1f, 23.7f));
hercules.addEdge("battled", hydra, "time", 2, "place", Geoshape.point(37.7f, 23.9f));
hercules.addEdge("battled", cerberus, "time", 12, "place", Geoshape.point(39f, 22f));
pluto.addEdge("brother", jupiter);
pluto.addEdge("brother", neptune);
pluto.addEdge("lives", tartarus, "reason", "no fear of death");
pluto.addEdge("pet", cerberus);
cerberus.addEdge("lives", tartarus);
// commit the transaction to disk
tx.commit();
}
/**
* Calls {@link JanusGraphFactory#open(String)}, passing the JanusGraph configuration file path
* which must be the sole element in the {@code args} array, then calls
* {@link #load(org.janusgraph.core.JanusGraph)} on the opened graph,
* then calls {@link org.janusgraph.core.JanusGraph#close()}
* and returns.
* <p>
* This method may call {@link System#exit(int)} if it encounters an error, such as
* failure to parse its arguments. Only use this method when executing main from
* a command line. Use one of the other methods on this class ({@link #create(String)}
* or {@link #load(org.janusgraph.core.JanusGraph)}) when calling from
* an enclosing application.
*
* @param args a singleton array containing a path to a JanusGraph config properties file
*/
public static void main(String args[]) {
if (null == args || 1 != args.length) {
System.err.println("Usage: GraphOfTheGodsFactory <janusgraph-config-file>");
System.exit(1);
}
JanusGraph g = JanusGraphFactory.open(args[0]);
load(g);
g.close();
}
} 
JanusGraph提供多种后端存储和后端索引,使其能够更灵活的部署。本章介绍了几种可能的部署场景,以帮助解决这种灵活性带来的复杂性。
在讨论部署场景之前,理解JanusGraph本身的角色定位和后端存储的角色定位是非常重要的。首先,应用程序与JanusGraph进行交互大多数情况下都是进行Gremlin遍历,然后,JanusGraph把遍历请求发给配置好的后端(存储后端、索引后端)执行遍历处理。当JanusGraph以服务的形式被使用的时候,将不会有主服务(master JanusGraph Server)。应用程序可以连接任何一个JanusGraph服务实例。这样就可以使用负载均衡把请求分配到不同的实例上。JanusGraph服务实例之间本身是没有之间联系的,当遍历处理增大的时候这更容易扩容。
对如下每张图从左往右进行标号
1客户端 、2 janusGraph集群+gremlinServer(janusGraph server)、3存储集群(后端)
8.1 快速上手方案
8.1. Getting Started Scenario
这种场景是大多数用户在刚开始使用JanusGraph时可能要选择的场景。它提供了可伸缩性和容错性所需要的最少服务数量。每个JanusGraph服务运行在单独的存储后端和可选的索引后端。

8.2 建议部署方案
8.2. Advanced Scenario
建议部署方案也是由8.1节 快速上手部署方案进化来的。JanusGraph服务实例集群不和存储后端集群和索引后端集群部署在一起,他们被分配到不同的服务器上集群上。建议不同的组件集群(JanusGraph服务、索引后端、存储后端)部署到不同的服务器集群上,这样能够方便扩容和管理,相互之间也互不依赖。这为维护更多的服务器提供了更高的灵活性。


对每张图从左往右进行标号 1客户端 、2 janusGraph集群+gremlinServer(janusGraph server)、3存储集群(后端)
该方案提供了不同组件的独立可伸缩性,当然,使用可伸缩的后端也是非常有意义的。
8.3 极简方案
8.3. Minimalist Scenario
JanusGraph服务也可以和后端存储/索引部署在一台机器上。这对于测试或者单应用来说,部署在一台服务器上是非常具有吸引力的。

与上面方案相反,这种部署方案不可伸缩。内存后端可用于测试,Berkeley DB用于生产,Lucene作为可选索引后端。
8.4嵌入式JanusGraph
8.4. Embedded JanusGraph
基于JVM的应用程序可以直接嵌入一个JanusGraph包,而不用连接到JanusGraph服务。虽然这样可以减少管理开销,这导致不能对JanusGraph进行单独扩容。JanusGraph嵌入式部署方案是其他部署方案的变种,JanusGraph只是从服务器直接移动到应用程序中,因为它现在只是用作库,而不是独立的服务。
参考资料:
[1] http://janusgraph.org/ JanusGraph官方网址
[2] https://github.com/JanusGraph/janusgraph JanusGraph的github源码网址
[3] https://docs.janusgraph.org/latest/index.html JanusGraph的官方文档