环境
spark-1.6
python3.5
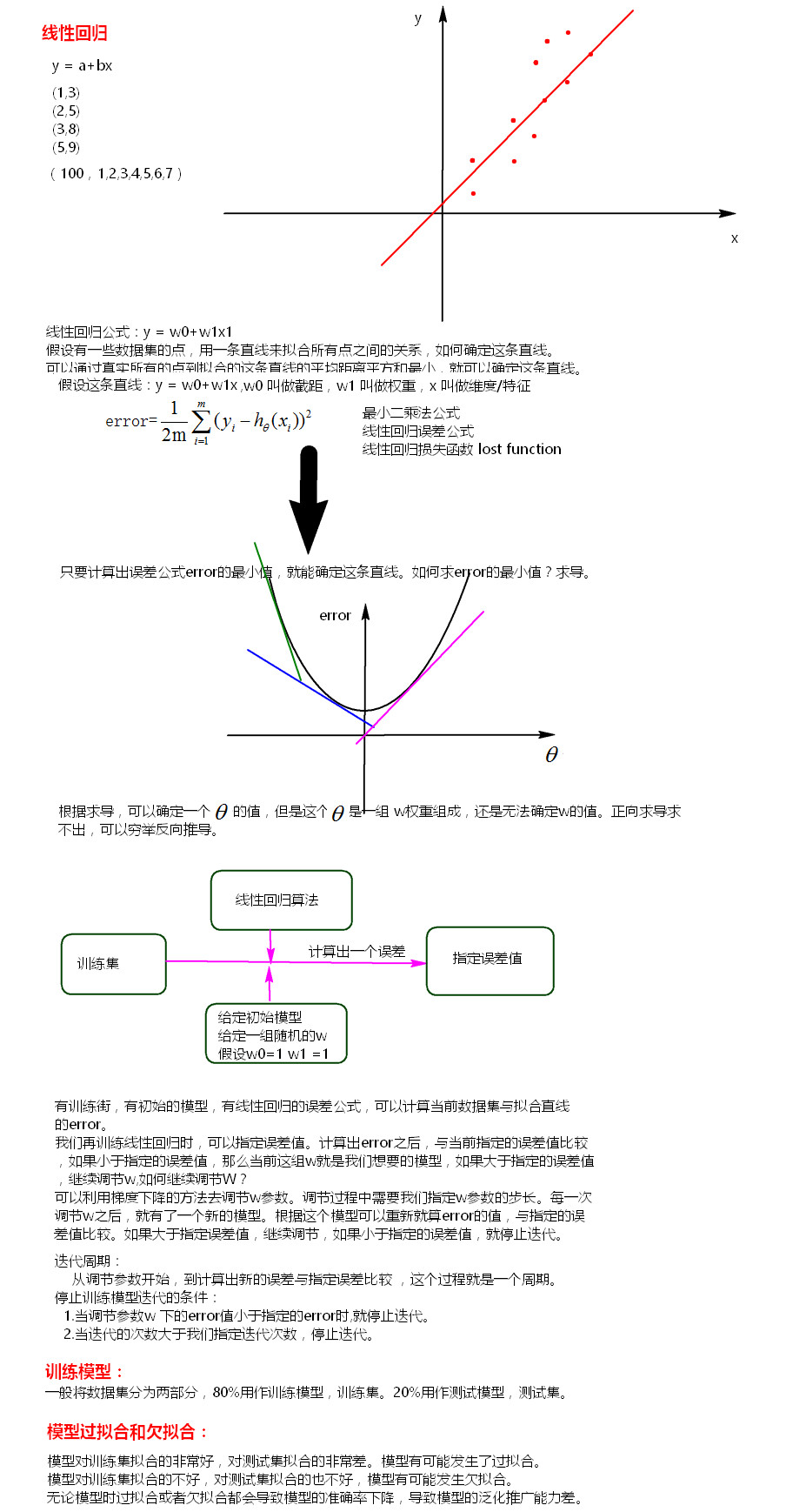
一、线性回归
二、spark MLLIB案例
package com.wjy.df import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.ml.regression.LinearRegressionModel import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.mllib.regression.LabeledPoint import org.apache.spark.mllib.regression.LinearRegressionWithSGD /** * @author Administrator * 线性回归案例 */ object LinearRegression { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local").setAppName("LinearRegressionWithSGD") val sc = new SparkContext(conf) sc.setLogLevel("WARN") //读取样本数据 官方样例文件 val data = sc.textFile("./data/lpsa.data") val examples = data.map{ line => val parts = line.split(",") val y = parts(0) val xs = parts(1) LabeledPoint(parts(0).toDouble,Vectors.dense(parts(1).split(" ").map(_.toDouble))) }.cache() val train2TestData = examples.randomSplit(Array(0.8, 0.2), 1) val lsr = new LinearRegressionWithSGD() //让训练出来的模型有w0参数,就是有截距 lsr.setIntercept(true) //在每次迭代的过程中 梯度下降算法的下降步长大小 0.1 0.2 0.3 0.4 val stepSize = 1 //设置步长 lsr.optimizer.setStepSize(stepSize) /* * 迭代次数 * 训练一个多元线性回归模型收敛(停止迭代)条件: * 1、error值小于用户指定的error值 * 2、达到一定的迭代次数 */ val numIterations = 100 //设置迭代次数 lsr.optimizer.setNumIterations(numIterations) //每一次下山后,是否计算所有样本的误差值,1代表所有样本,默认就是1.0 val miniBatchFraction = 1 lsr.optimizer.setMiniBatchFraction(miniBatchFraction) //使用80%数据训练 val model = lsr.run(train2TestData(0)) println(model.weights) println(model.intercept) //使用20%数据对样本进行测试 val prediction = model.predict(train2TestData(1).map(_.features)) val predictionAndLabel = prediction.zip(train2TestData(1).map(_.label)) //打印前20条数据 val print_predict = predictionAndLabel.take(20) println("prediction" + " " + "label") for(i <- 0 to print_predict.length-1){ println(print_predict(i)._1+" "+print_predict(i)._2) } //计算测试集平均误差 val loss = predictionAndLabel.map{ case(p,v) => val err = p-v Math.abs(err) }.reduce(_+_) val error = loss / train2TestData(1).count println("Test RMSE = " + error) // 模型保存 val ModelPath = "model" model.save(sc, ModelPath) //val sameModel = LinearRegressionModel.load(sc,ModelPath) sc.stop() } }
结果:
[0.7296067051590363,0.23094665849041549,-0.1359562285885802,0.19004800201024025,0.2745413011485292,-0.31515879010131637,-0.04672248486523373,0.30883491480399367] 2.4764583366071977 prediction label 1.749456972317874 0.3715636 1.8633537772490665 1.3480731 2.6325111666721064 1.7137979 2.3720657017536393 1.8484548 1.011168768081166 2.0476928 2.6730070097763634 2.5533438 3.011702574063707 2.7180005 2.2693119088733686 2.8063861 2.4416666667211793 2.8419982 3.1092859129401047 2.9626924 3.3123201208597277 3.2752562 2.6098535244026935 3.5876769 Test RMSE = 0.5736895056295152