环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop-3.1.1
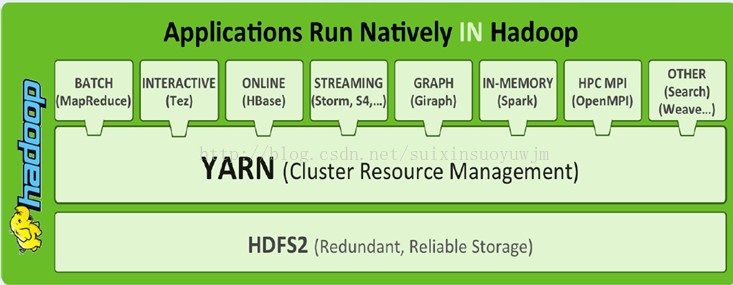
YARN:Yet Another Resource Negotiator
一、Yarn框架


1、概念
由于MRv1存在的问题,Hadoop 2.0新引入的资源管理系统
核心思想:将MRv1中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现。
(1)ResourceManager(RM):管理和分配集群的资源,是集群的一个单点,通过zookeeper来保存状态以便failover(容错)。RM主要包含两个功能组件:Applications Manager(AM)和Resource Scheduler(RS),其中AM负责接收client的作业提交的请求,为AppMaster请求Container,并且处理AppMaster的fail;RS负责在多个application之间分配资源,存在queue capacity的限制,RS调度的单位是Resource Container,一个Container是memory,cpu,disk,network的组合。Yarn支持可插拔的调度器!(处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度)
(2)ApplicationMaster(AM):每个application的master,负责和Resource Manager协商资源,将相应的Task分配到合适的Container上,并监测Task的执行情况。
(3)NodeManager(NM):部署在每个节点上的slave,负责启动container,并且检测进程组资源使用情况,单个节点上的资源管理、处理来自ResourceManager、ApplicationMaster的命令。
(4)Container:对任务运行环境的抽象。它描述一系列信息:任务运行资源(包括节点、内存、CPU)、任务启动命令、任务运行环境
2、运行过程
(1)用户通过JobClient向RM提交作业
(2)RM为AM分配Container,并请求NM启动AM
(3)AM启动后向RM协商Task的资源
(4)获得资源后AM通知NM启动Task
(5)Task启动后向AM发送心跳,更新进度、状态和出错信息

3、YARN容器框架能够支撑多种计算引擎运行,包括传统的Hadoop MR和现在的比较新的SPARK。 为各种框架进行资源分配和提供运行时环境。
(1)配置hadoop-env.sh
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
(2)配置etc/hadoop/mapred-site.xml
mapreduce.framwork.name:代表mapreduce的运行时环境,默认是local,需配置成yarn
mapreduce.application.classpath:Task的classpath
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value> </property> </configuration>
etc/hadoop/yarn-site.xml:
yarn.nodemanager.aux-services:代表附属服务的名称,如果使用mapreduce则需要将其配置为mapreduce_shuffle
yarn.nodemanager.env-whitelist:环境变量白名单,container容器可能会覆盖的环境变量,而不是使用NodeManager的默认值
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>
(3)修改workers配置nodemanager的节点
node1
(4)启动
[root@node1 hadoop]# /usr/local/hadoop-3.1.1/sbin/start-yarn.sh Starting resourcemanager Starting nodemanagers [root@node1 hadoop]# jps 1824 Jps 1557 ResourceManager 1663 NodeManager
验证:

(5)关闭
[root@node1 hadoop]# /usr/local/hadoop-3.1.1/sbin/stop-yarn.sh Stopping nodemanagers Stopping resourcemanager
(1)配置hadoop-env.sh(node1)
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
(2)配置etc/hadoop/mapred-site.xml (node1)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
etc/hadoop/yarn-site.xml(node1):
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用HA集群-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--YARN HA集群标识-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<!--YARN HA集群里Resource Managers清单-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--YARN HA集群里Resource Manager 对应节点-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node3</value>
</property>
<!--YARN HA集群里Resource Manager 对应节点-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node4</value>
</property>
<!--YARN HA集群里Resource Manager WEB 主机端口-->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node3:8088</value>
</property>
<!--YARN HA集群里Resource Manager WEB 主机端口-->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node4:8088</value>
</property>
<!--YARN HA集群里ZK清单-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>
</configuration>
(3)修改workers配置nodemanager的节点
node2
node3
node4
将以上三步修改的文件分发到node2、node3、node4
(4)启动
(4.1)node1启动node2、node3、node4上的NodeManager [root@node1 hadoop]# /usr/local/hadoop-3.1.1/sbin/start-yarn.sh (4.2)node3、node4启动ResourceManager [root@node3 hadoop]# /usr/local/hadoop-3.1.1/sbin/yarn-daemon.sh start resourcemanager [root@node4 hadoop]# /usr/local/hadoop-3.1.1/sbin/yarn-daemon.sh start resourcemanager
验证:
http://node3:8088

NM只和Active RM交互资源信息

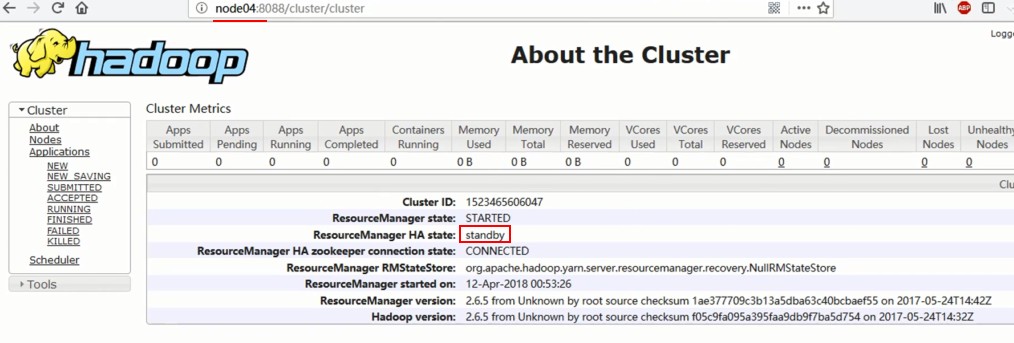
http://node4:8088 会跳转到node3

http://node4:8088/cluster/cluster (会显示node4为备机)
(5)关闭
[root@node1 hadoop]# /usr/local/hadoop-3.1.1/sbin/stop-yarn.sh
[root@node3 hadoop]# /usr/local/hadoop-3.1.1/sbin/yarn-daemon.sh stop resourcemanager
[root@node4 hadoop]# /usr/local/hadoop-3.1.1/sbin/yarn-daemon.sh stop resourcemanager
参考:
https://blog.csdn.net/suixinsuoyuwjm/article/details/22984087
https://www.cnblogs.com/sammyliu/p/4396162.html
HA搭建:https://blog.csdn.net/afgasdg/article/details/79277926