目录:
- Redis五大对象
- Redis持久化
- Redis主从复制
- 慢查询日志
- Redis Shell
- Pipeline
- 事务
- Bitmaps
- HyperLogLog
- 发布订阅
- GEO
- 哨兵
- 集群
- 缓存设计
1、Redis五大对象:
在Redis中有五大对象,分别是String、List、Hash、Set、Sorted Set。
这五大对象都有自己独特的编码方式,每个编码的实现都不一样,有自己独特的使用场景。
通过命令:object encoding keyName查看键的编码类型。
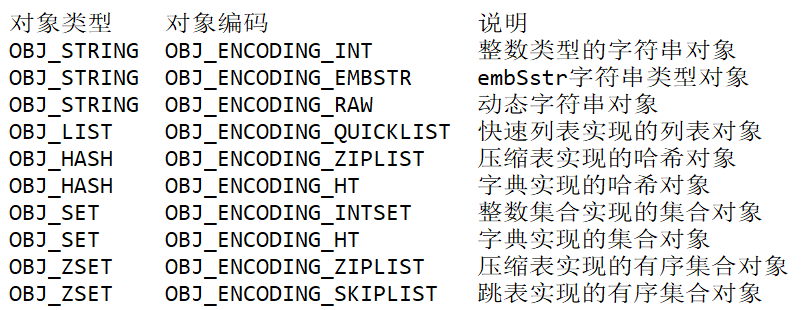

a、String(字符串类型):
INT:可以用long型保存的整数。
EMBSTR:除了字符串、long,还可以保存double这种浮点数,但长度需要<=44。
RAW:保存长度大于44的字符串、long、double。
b、List(列表):
quicklist包含多个ziplist,是对ziplist的优化。
list-max-ziplist-size,若值是整数则表示quicklist上ziplist的节点数量,负数则表示ziplist的大小(公式:KB = -1 * 2 ^ n)。
- -3:quicklist节点的ziplist大小不能超哥16KB。
- -2:quicklist节点的ziplist大小不能超哥8KB(默认值)。
- -1:quicklist节点的ziplist大小不能超哥4KB。
因为list被设计成两端获取效率高,中间数据获取效率低,若满足这个条件可以通过list-compress-depth配置来压缩中间数据,进一步节省内存。
- 0:特殊值,不是不压缩(默认值)。
- 1:quicklist两端各有1个节点不压缩,中间的节点压缩。
- 2:quicklist两端各有2个节点不压缩,中间的节点压缩。
- 以此类推。
c、Hash(字典):
当哈希对象同时满足一下两个条件时,使用ziplist编码:
- 所有键值元素长度小于64字节,可通过改变hash-max-ziplist-value修改默认值。
- 键值对数量小于512个,可通过改变hash-max-ziplst-entries修改默认值
d、Set(集合):
当集合对象同时满足以下两个条件时,集合对象使用intset编码
- 集合对象保存的所有元素都是整数值。
- 键值对数量不超过512个,可通过修改配置文件中的set-max-inset-entries属性改变默认值。
e、ZSet(有序集合):
当有序集合对象同时满足以下两个条件时,有序集合对象使用ziplist编码:
有序集合对象保存的所有成员长度小于64字节,可通过修改配置文件中的zset-max-ziplist-value属性改变默认值。
有序集合对象保存的所有元素数量小于128个,可通过修改配置文件中的zset-max-ziplist-entries属性改变默认值。
2、Redis持久化
a、RDB持久化:
RDB持久化方式就是把当前进程中的数据以快照形式保存到磁盘的过程,其分为手动和自动触发。
手动:
- save命令:save命令会阻塞主进程,若数据量较大则会影响正常的服务请求。
- bgsave命令:bgsave会fork一个子进程,会阻塞fork子进程的时间(阻塞时间极短)。
自动触发条件:
- 根据单位时间(秒)内数据修改次数来触发,默认配置如下:
- save 900 1
- save 300 10
- save 60 10000
- 从节点进行全量复制时。
- 执行debug reload命令时。
- 执行shutdown命令时若没有开启aof时执行bgsave。
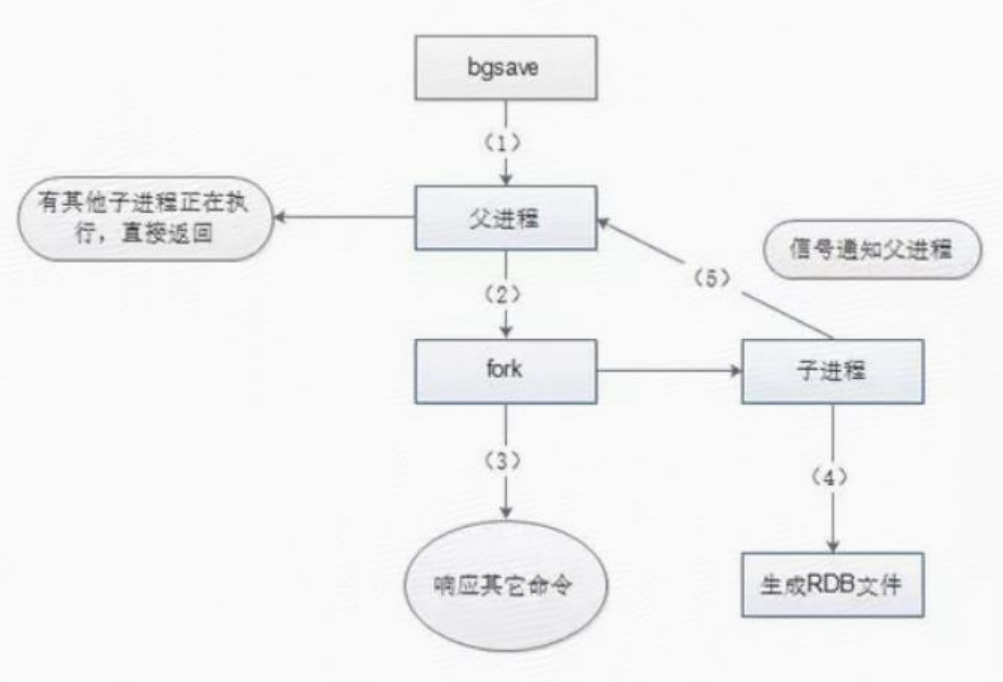
RDB持久化步骤:
- 执行bgsave命令,此时父进程会判断是否有正在执行的子进程(如RDB/AOP),如有直接返回。
- 父进程执行fork操作创建子进程,此时父进程会阻塞(可通过info stats命令查看latest_fork_usec选项查看最近一个fork操作耗时,单位微妙)。
- 父进程fork完后,bgsave会返回"Background saving started",并不再阻塞父进程。
- 子进程创建RDB文件。
RDB优缺点:
优点:
- RDB持久化的文件非常紧凑(有压缩),它会保存某个时间点的数据,可以方便的把数据传送远端数据中心,适用于灾难恢复。
- bgsave存储时用子进程执行操作,最大化的优化redis的性能。
- 与AOF相比,在恢复大量数据时会快些。
缺点:
- 因为不是实时存储数据,所以宕机时会丢失一部分数据。
- 数据量大时,fork的过程会非常耗时,如果fork阻塞,那么主线程也会受到影响。
- RDB方式的持久化的文件是特定的格式,可读性、兼容性差(不同版本的RDB格式都不一样)。
b、AOF持久化:
RDB与AOF两种持久化方式只能二选一,若需要使用AOF需要通过配置文件开启,因为默认是不开启的。
配置:
- 是否开启APO(默认false):appendonly yes。
- AOF文件名(默认appendonly.aof):appendfilename xxx.aof。
- 保存路径:通过dir配置指定。
AOF持久化是通过保存Redis服务器所执行的命令来记录数据库的状态,每执行一个命令就会往AOF文件后追加一个命令。
AOF采用RESP协议写入数据:

单行字符,+开头。
多行字符,$开头,后跟字符串长度。
整数值,:开头,后跟整数字符串形式。
错误消息,-开头。
数组,*开头,后跟数组长度。
AOF持久化流程:
- 首先每次追加直接操作磁盘的话,性能上肯定不高,所以Redis会先将命令追加到aof_buf中。
- 然后缓冲区再根据相应的策略将缓冲区的内容同步到磁盘。
- 并且Redis还会定期的对AOF文件进行重写,以达到压缩的目的。
- 服务器重启时可以通过AOF文件恢复数据。
为什么AOF文件能够重写:
- 过期的数据可以不写入。
- 无效的数据可以不写入。
- 多条命令可以合并成一个写入。
AOF持久化的优缺点:
优点:
- 支持秒级持久化。
- 可用于不同版本的Redis服务器,兼容性强。
- 可读性高。
缺点:
- 文件大,恢复数据慢。
3、Redis主从复制
a、主从复制是什么:
在绝大多数中间件中都会具有主动复制这一功能,而多数也就是为了服务的高可用罢了;Redis也不例外,它提供了复制功能,实现了相同数据的多个副本。
b、搭建复制三种方式:
- 从节点配置文件中加入slaveof <masterIp> <masterPort>
- 启动命令后加入--slaveof <masterIp> <masterPort>
- 通过命令laveof <masterIp> <masterPort>
注意:
- slaveof是异步命令,节点保存主节点信息后便返回,后续复制就从在节点异步进行。
- 由于复制模式是单向的,从节点接收写命令的话无法让主节点感知,这样会造成数据不一致的情况,所以从节点需要配置成只读模式(slave-read-only=yes)。
c、主动复制原理:
流程:
- 保存主节点信息:从节点保存主节点信息(ip、port)。
- job网络连接主节点:从节点内部通过job来维护复制相关逻辑,当job发现新的主节点后会尝试与该节点建立网络连接;若无法连接job会无限重试直到连接成功,或执行slaveof no one命令取消复制。
- 发送ping给主节点:从节点会发送ping命令,检测主动之间套接字是否可用,和主节点当前是否可接受处理命令。
- 权限验证:如果主节点设置了requirepass则需要密码验证,且从节点需要有相同的配置才能通过验证;如果验证失败复制终止,从节点断开连接。
- 连接成功:发送从节点的ip、port给主节点。
- 数据同步:依据情况主从之间进行全量或部分复制。
- 命令传播:当上述步骤完成后,也算是完成了复制的建立流程,接下来主节点会持续地把命令发送给从节点来保证主从数据的一致性。
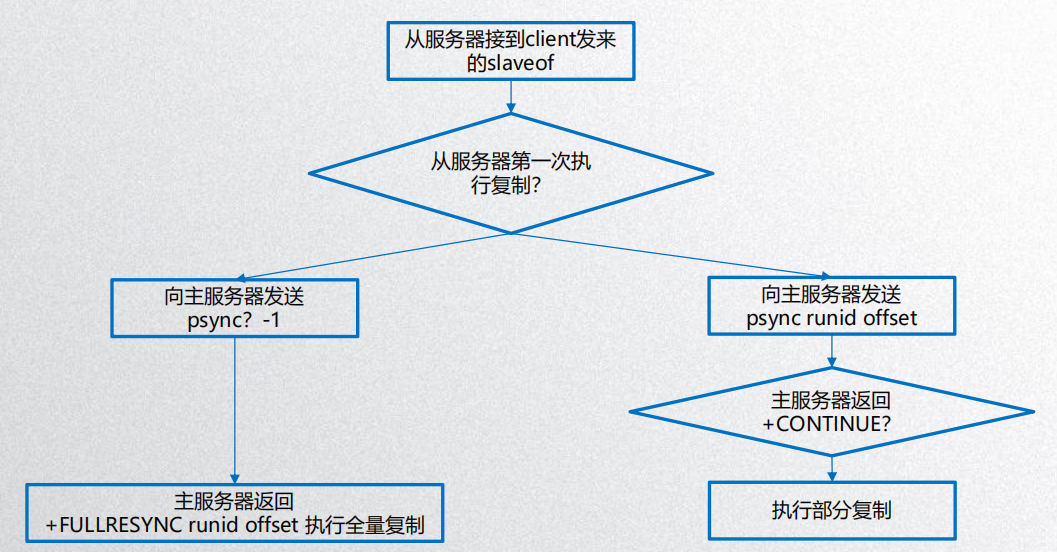
全量复制于部分复制:
)全量:psync ? -1
一般用于初次复制的场景(虽然早期的Redis也仅支持全量复制),它会一次性的打包所有的数据给从节点,当数据量较大时会主从节点和网络造成很大的开销。
)部分:psync <runid> <offset>
用于复制过程中宕机或网络闪断的场景,主节点会补发数据给从节点。因补发数据远小于全量数据,所以可以有效的避免全量复制的开销。
部分复制的三要素:
- 复制偏移量:参与复制的主从节点都会维护自身的偏移量,主节点在处理完写命令后会累加这个偏移量,从节点会每秒的上报偏移量,因此主节点就拥有了主从的偏移量。
- 温馨提示:可以通过主节点master_repl_offset信息判断主动节点相差的数据量,从而得知复制的健康度。
- 复制积压缓冲区:主节点执行写命令时不但会将数据同步给从节点,还会写入到复制积压缓冲区。部分复制时会根据缓冲区的偏移量来判断从哪开始复制。
- 运行ID:若主从runid相同,则表示此主从之前同步过,进行部分复制即可;若不同则表示从节点之前同步的主节点并非此主节点,所以要进行全量复制。

psync命令流程图:
4、慢查询日志
慢查询阀值设置(单位:微秒,默认10000,也就是0.1秒):slowlog-log-slower-than;0为记录所有,小于0都不记录。
Redis用一个列表存储慢查询日志,可用slowlog-max-len指定日志存储的最大长度。
相关命令:
- 获取慢查询日志列表,可执行返回条数:slowlog get <n>。
- 获取慢查询日志列表当前长度:slowlog len。
- 清空慢查询日志列表:slowlog reset。
5、Redis Shell
redis-cli:Redis客户端shell。
redis-server:Redis服务端shell。
redis-benchmark:测试并发。
6、Pipeline
为了改善多个命令的RTT,Pipeline会一次性将命令打包给Redis服务器,Redis服务器再将这些命令的结果依次返回。
注意:虽然Pipeline好用,但一次传输的量也不能无节制,数据量过大时一方面会造成客户端阻塞,一方面会造成一定的网络阻塞;可以将一次大的包拆分成多个小包传输。
7、事务
a、事务的三个阶段:
- 事务的开始:multi命令标识事务的开始。
- 事务的入队:当客户端为事务模式时,除了执行exec、discard、watch、multi命令之外的命令都会返回给客户端queued状态。
- 事务的执行:当对客户端发送exec命令时,服务端会依次执行事务队列的所有命令,并返回最终结果给客户端。
b、事务中的错误处理:
- 入队错误:入队错误是指在事务队列中出现了错误的命令,此时Redis将拒绝这次事务,但这在使用客户端操作时是不存在的。
- 执行错误:因为有些命令只有在执行的时候才能发现(如:set key value、hget key等等),这种情况Redis不会拒绝这次事务,而是忽略错误命令。
c、watch命令:
watch命令是一个乐观锁,它可以在exec命令执行前监视一个或多个key,若这个key在执行事务期间被修改的话,那么在执行exec命令后便会拒绝这次事务。
8、Bitmaps
Bitmaps并不是一种数据结构,它的实质其实就是字符串,但它可以对字符串做位操作(转换成二进制做位操作)。
命令:
- 获取key指定偏移量的位数:getbit key <offset>。
- 获取指定偏移量在哪个字节中:byte,byte = offset / 8。
- 获取指定偏移量在byte字节的第几位:bit = (offset % 8) + 1。
- 根据byte、bit返回位数的值(0或1)。
- 设置指定key的偏移量:setbit key <offset> <value>。
- 计算所需字节数,len = (offset / 8) + 1。
- 检查key保存的字节数是否小于len,小于则扩展,其余部分补0。
- 同getbit key <offset>的步骤a、b。
- 将指定value设置到key中。
- 返回给客户端原值。
- 获取key中二进制数值为1的数量:bigcount key。
- Bitmaps逻辑运算:bitop op destkey key [key ...]。
- 交集 op = and:0组合0 >>> 0、0组合1 >>> 0、1组合1 >>> 1。
- 并集 op = or:0组合0 >>> 0、0组合1 >>> 1、1组合1 >>> 1
- 非 op = not。
- 异或 op = xor。
- 返回字符串里第一个被设置为1或0的bit位:bitpos key targetBit [start] [end]。
应用场景:适用于快速、简单、实时统计,如独立访客、日活用户等等。
9、HyperLogLog
HyperLogLog和Bitmaps非常相似,其使用一种概率算法,这种算法非常节约磁盘空间,但缺点是并不是非常精确(误差在0.81%左右),且不能获取单条数据,只能拿到一个统计的总数;所以仅适用于类似统计在线人数这种需求。
命令:
- 添加:pfadd key element [element ...](添加成功返回1,失败返回0)。
- 统计数量:pfcount key [key ...](返回数量)。
- 合并:pfmerge destkey sourcekey [sourcekey ...]。
10、发布订阅
。。。。。。
11、GEO
GEO是redis中对地理位置功能的支持;其使用geohash存储地址位置的坐标,使用有序集合(zset)存储地址位置的集合。
12、哨兵
顾名思义哨兵就是监视某事或某物,并在发送异常情况下及时做出反馈的兵种。在Redis中哨兵就是在主从复制架构下,主节点宕机了,系统自动故障转移的角色。
故障转移的过程:
- 选举新节点:当主节点发生故障且无法正常重启时,就需要在从节点中选出一个新的主节点,并执行slaveof no one。
- 更新应用方:待新的主节点选举出来后,便通知应用方更新应用方的主节点信息,重启应用方。
- 重新复制:客户端命令其它的从节点和原来的主节点去复制这个新的主节点,slaveof host port。
故障转移原理:
- 定期监控:每个sentinel都会监控redis节点,若发现主节点出现了故障则标记。
- 节点决策:当多个sentinel节点都认为主节点故障后,则会选举一个领导来执行这次故障转移。
- 执行转移:被选举出的那个sentinel执行故障转移。
哨兵实现原理:
- 三个job:获取节点信息、获取其它sentinel节点对主节点的判断、心跳检测。
- 获取节点信息:每隔10秒,sentinel节点会向主节点发送info命令获取节点信息。
- 获取其它sentinel节点对主节点的判断:每隔2秒,每个sentinel节点会向__sentinel__:hello频道上发送自己对主节点的判断以及自己的信息,同时每个sentinel会订阅这个频道来获取其它sentinel节点对主节点的判断。
- 心跳检测:每隔1秒,每个sentinel节点会向其它sentinel节点以及主从节点发送ping命令,来检测其它节点是否可达。
- 主观、客观下线:sentinel并不会自己觉得主节点有问题就执行转移,而是满足主观和客观两个条件才会对主节点转移。
- 主观(自己的判断):sentinel通过心跳检测,当主节点超过配置时间未响应,则会认为主节点有问题。
- 客观(公共的判断):sentinel会像其它sentinel节点询问对主节点的判断,如果超过配置数量的节点数认为主节点也有问题,则会做客观下线处理。
- 选举一个领导者执行故障转移:在sentinel对主节点做出主观、客观下线后便会从众多sentinel节点中选出一个领导者执行故障转移。
13、集群
为什么要集群:主从复制架构下全量复制时若数据量太大,复制数据时可能会导致网络阻塞,严重时可能会导致Redis进程阻塞从而无法对外提供服务。
解决办法:采用集群架构,将数据分片;将全量数据拆分到不同的分区中,每个节点有一个或多个分区数据。
分区规则:
- Redis cluster中采用虚拟槽分区,所有的键根据哈希函数映射到编号为0 - 16383的槽内。
- 计算公式:slot = CRC16(key) & 16383。
- 每个主节点可以拥有一到多个从节点,当主节点宕机或是不可用时从节点将自动晋升为主节点。
集群与单机相比存在的一些功能限制:
- 对于批量操作的命令支持有限:仅支持分配到相同槽的批量key操作,如mget、mset。
- 对于事务支持有限:仅支持分配到相同槽的key进行事务操作。
- 大键值对象:因分配的最小粒度为key,所以不支持将大键值的对象,如hash、list映射到不同节点上。
- 数据空间:单机下可使用16个DB,而集群架构下只能使用db0。
- 复制结构:只支持一层复制结构,不支持嵌套树状复制结构。
14、缓存设计
a、缓存更新策略:
- 内存溢出淘汰策略:当使用内存达到配置内存上线后触发。
- 拒绝写入:noevication(默认策略);不删除任何数据,拒绝所有写入操作,并返回给客户端OOM,此时只响应读操作。
- 过期LRU:volatile-lru;根据LRU算法删除设置了过期时间的键,如果没有可删除的,回退到noevication。
- 过期随机:volatile-random;随机删除过期间,直到腾出足够的空间为止。
- 全部LRU:allkeys-lru;根据LRU算法删除所有键,直到腾出足够的空间为止。
- 全部随机:allkeys-random:随机删除所有键,直到腾出足够的空间为止。
- ttl:根据对象ttl属性,删除最近将要过期的数据。如没有回退到noevication。
- 过期删除策略:
- 惰性删除:Redis内部维护了一个过期字典,当客户的获取键时首先会判断是否过期,如果过期了会先执行删除操作然后再返回空。这种方式虽然节省CPU成本,但可能会造成内存泄漏的问题(如果一直没有获取这些key就会导致内存不能及时释放)。
- 定时删除:Redis内部维护一个job,每秒运行10次。
- 应用方更新策略:
- 读数据:先读缓存,后读数据库。
- 写数据:先写数据库,后写缓存。
- 每次更新数据都要把缓存清掉。
- 缓存设置过期时间,保持与数据库的最终一致性。
b、缓存穿透:
- 什么是缓存穿透:缓存穿透查询一个根本不存在的数据,导致每次请求都不会命中缓存,请求都进到DB,导致DB压力过大而降低DB吞吐量,严重时可能会让DB宕机;一般是自身业务代码或数据出现问题,或是一个恶意攻击、爬虫等造成的。
- 怎么解决:
- 缓存null值,将那些不可能存在的数据也做一层缓存,如缓存值为null;这样便不会将这些数据命中到DB层了。
- 布隆过滤器。
c、缓存雪崩:
- 什么是缓存雪崩:大量key在同一时间失效,导致大量请求同时打到DB,导致DB宕机。
- 如何解决:
- 缓存层设计成高可用了,如sentinel、cluster架构。
- 采用多级缓存,本地一级缓存,redis作为二级缓存。
- 缓存时间采用随机值,让key不在同一时间失效。
d、缓存击穿:
- 什么是缓存击穿:高并发场景下,当缓存即将失效时有大量线程来重构缓存,且重构缓存无法在短时间内完成。
- 如何解决:
- 分布式互斥锁:仅允许一个线程重构缓存,其它线程等待重构完成后再返回数据。
- 永不过期:要么不设置过期时间,要么就另起一个线程,在缓存即将过期时更新数据。