测试题目:
1、数据导入:
要求将样表文件中的(AA_GXJSQYDC2019)数据导入HIVE数据仓库中。
分别将四个标准维度表导入数据仓库中。
2、数据清洗:
根据标准维度将国民经济行业维度、地域维度、高新技术领域维度、企业所属领域维度四个维度字段清洗完成。
3、数据可视化展示:
尝试按照某一维度实现数据下钻展示。(例如地域维度,按照市——县两级展示)
今天的测试题目,我不知道怎么用hive去做多表的数据清洗我按步骤尽量完成
导入原始表
1.
create table hb(id string,QA04 string,QA05 string,QA07 string,QA15 string,QA19 string,QB string,QB03 string,QB03ONE string,QB03TWO string,QB03_1 string,QB06 string,QB16J string,QB16V string,QB16 string,QB16_1 string,QB16_1V string,QC02 string,QC05_0 string,QC24 string,QC40 string,QD01 string,QD28 string,QJ09 string,QJ20 string,QJ55 string,QJ74 string,QA string,SYEAR string)Row format delimited fields terminated by ',';
2.
load data local inpath '/opt/software/apache-hive-2.3.9-bin/211.csv' into table hb;
导入行政地区划分代码表
3.
create table pl(pid string,pname string,pxx string)Row format delimited fields terminated by ',';
load data local inpath '/opt/software/apache-hive-2.3.9-bin/xingzheng.csv' into table pl;
导入企业维度划分表
4.
create table qy(qyid string,qywd string)Row format delimited fields terminated by ',';
load data local inpath '/opt/software/apache-hive-2.3.9-bin/qiyeweidu.csv' into table qy;
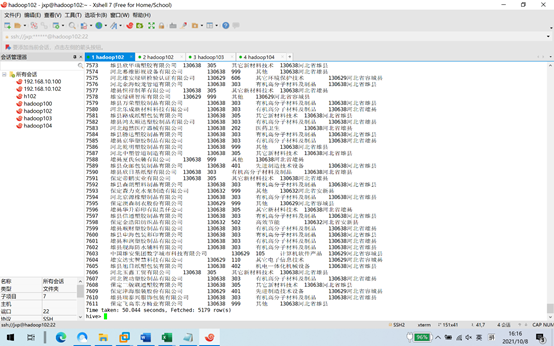
5.关联行政地区表
elect hb.id ,hb.QA04,hb.QA19,
concat(pl.pid,pl.pname) as ppname
from hb join pl on hb.QA19=pl.pid ;
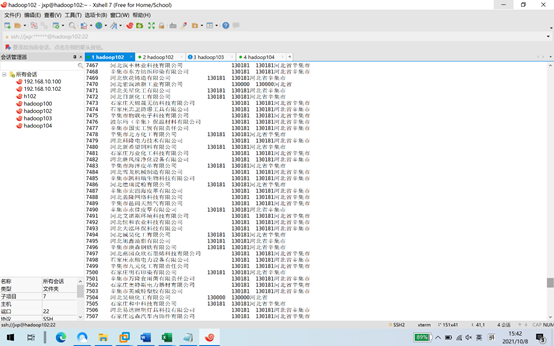
6.
关联企业维度表
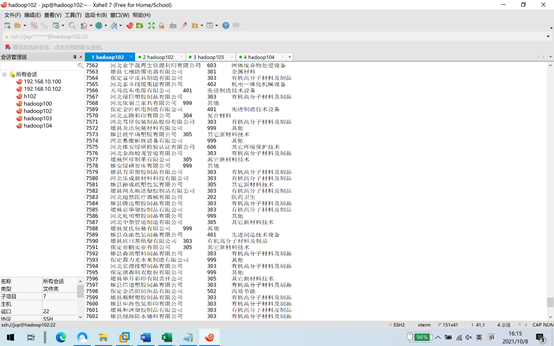
7.关联两个表