一、简介
注意力(attention)是一个十分常见的现象,这在视觉领域尤为明显。比如在上课的时候,学生的注意力几乎都集中在老师身上,而对老师身边的讲台和身后的黑板不会关注(如果没有老师指挥的情况下关注了的话只能证明你在开小差...),此时可以认为除了老师以外,都被学生自动认为是背景(background)了。而计算机视觉中的注意力机制的基本思想就是让系统学会注意力——能够忽略无关信息而更多的关注我们希望它关注的重点信息。
这里主要讨论的是CV领域——CNN的注意力机制,关于自然语言处理(NLP)或视觉问答系统(VQA)中也有,有兴趣可以去自己查阅相关论文和博客。
二、参考文献与资料
参考论文:
1、CBAM: Convolutional Block Attention Module . Sanghyun Woo, Jongchan Park, Joon-Young Lee, In So Kweon.(ECCV, 2018)
2、Squeeze-and-Excitation Networks. Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu.(CVPR, 2017)
3、Wang, Fei, et al. "Residual attentionnetwork for image classification." arXiv preprint arXiv:1704.06904 (2017).
参考文章:
1、https://mp.weixin.qq.com/s/KKlmYOduXWqR74W03Kl-9A
2、https://blog.csdn.net/xjz18298268521/article/details/79078551(SE Block)
3、https://blog.csdn.net/wspba/article/details/73727469
参考代码:
1、CBAM : https://github.com/kobiso/CBAM-tensorflow-slim(tensorflow-slim版本)
2、SE BLOCK : https://github.com/taki0112/SENet-Tensorflow(tensorflow版本)
3、Residual Attention : https://github.com/fwang91/residual-attention-network(caffe)(其他版本可自行在github查找)
三、注意力的发展和分类
关于早期的注意力研究,是从大脑成像机制去分析的,采用的方法在深度学习发展的今天,并不适用,在此不做讨论。现在如何搭建具备注意力机制的神经网络更加重要:一方面是这种神经网络能够自主学习注意力机制,另一方面则是注意力机制能够反过来帮助我们去理解神经网络“看到的世界”。
近几年来,深度学习与视觉注意力机制结合的研究工作,大多数是集中于使用掩码(mask)来形成注意力机制。掩码的原理在于通过另一层新的权重,将图片数据中关键的特征标识出来,通过学习训练,让深度神经网络学到每一张新图片中需要关注的区域,也就形成了注意力。(可以注意到,本质是希望通过学习得到一组可以作用在原图上的权重分布)。
根据这种思想,注意力有两个大的分类:软注意力(soft attention)和强注意力(hard attention)。
强注意力是一个随机的预测过程,更强调动态变化,同时其不可微,训练往往需要通过增强学习来完成。(没接触过,不是研究的重点)。
软注意力的关键在于其是可微的,也就意味着可以计算梯度,利用神经网络的训练方法获得。这也是本文着重关注的对象。
四、软注意力
为了更具体的理解不同的注意力,本文从注意力域(attention domain)的角度来分析几种注意力的实现方法。其中主要是三种注意力域,空间域(spatial domain),通道域(channel domain),混合域(mixed domain),每种都会举出在论文中使用的真实模块来辅助理解。
1、空间域(Spatial Domain)—— CBAM Block(Convolutional Block Attention Module)(Image Caption)
注意力主要分布在空间中,又被称为空间注意力,表现在图像上就是对图像上不同位置的关注程度不同。反映在数学上就是指:针对某个大小为H×W×C的特征图,有效的一个空间注意力对应一个大小为H×W的矩阵,每个位置对原特征图对应位置的像素来说就是一个权重,计算时做pixel-wise multiply。
Spatial attention module: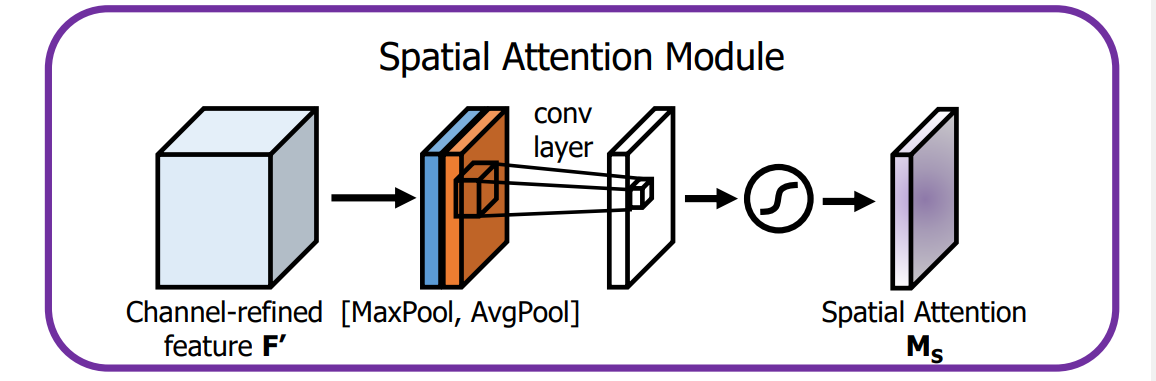
输入的是一个特征图,
(1)基于channel进行global max pooling和global average pooling;
(2)将上述的结果基于channel做concat;
(3)将concat后的结果经过一个卷积操作,channel降为1;
(4)将结果经过sigmoid生成spatial attention feature,可以与输入的特征图做乘法,为feature增加空间注意力。
公式: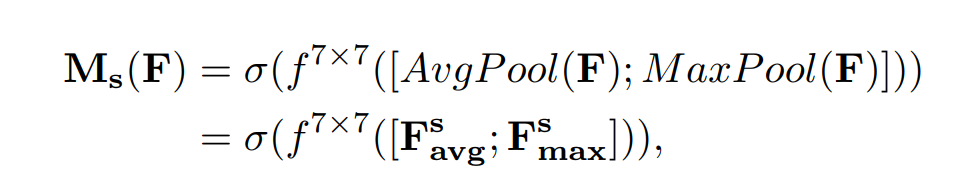
结果示例:
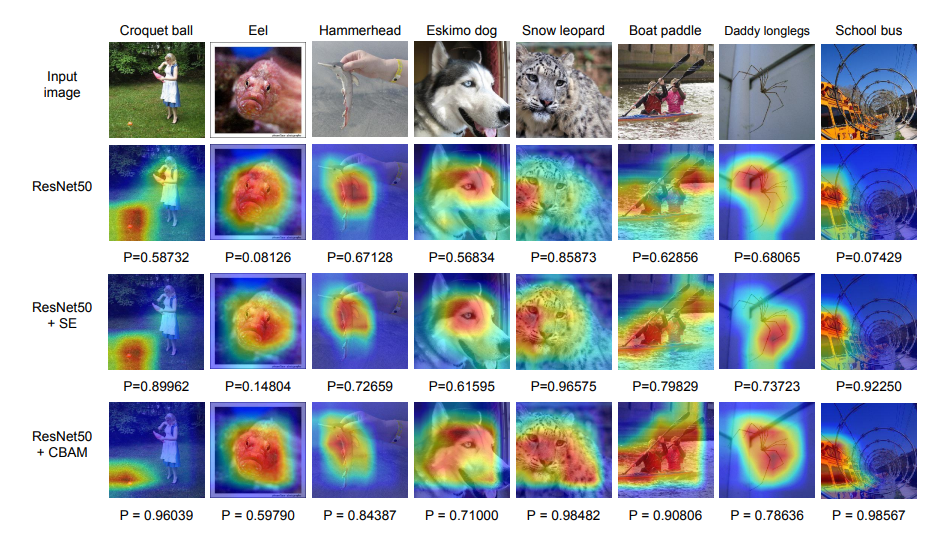
2、通道域(Channel Domain)—— SE Block(Image Classification)
这种注意力主要分布在channel中,表现在图像上就是对不同的图像通道的关注程度不同。反映在数学上就是指:针对某个大小为H×W×C的特征图,有效的一个通道注意力对应一个大小为1×1×C的矩阵,每个位置对原特征图对应channel的全部像素是一个权重,计算时做channel-wise multiply。
Channel Attention Module:
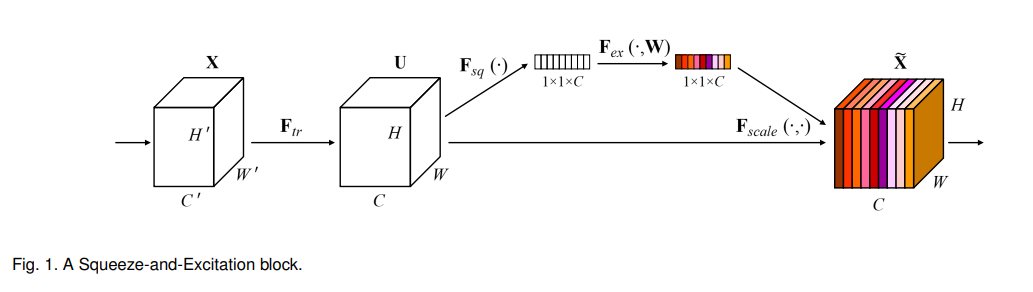
输入是一个特征图,
(1)Squeeze(挤压),本质就是全局均值池化,使得H×W×C的特征图变为1×1×C的实数序列;
公式:
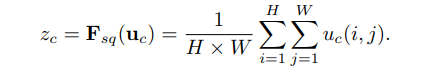
一般CNN中每个通道学习到的滤波器都对局部感受野进行操作,也就意味着U中每个feature map都无法利用其它feature map的上下文信息,而且网络较低的层次上其感受野尺寸都是很小的,这样情况就会更严重。
U(多个feature map)可以被解释为局部描述子的集合,这些描述子的统计信息对于整个图像来说是有表现力的。(实数某种程度上具有全局的感受野)论文选择最简单的全局平均池化操作,从而使其具有全局的感受野,使得网络低层也能利用全局信息。
(2)Excitation(激励)
通过Excitation操作来全面捕获通道依赖性,论文提出需要满足两个标准:
(1) 它必须是灵活的(特别是它必须能够学习通道之间的非线性交互);
(2) 它必须学习一个非互斥的关系,与one-hot激活相反,这里强调保证有多个通道。
为此,作者采用了一个简单的gating mechanism with a sigmoid function。
公式:

![]()
![]()
(论文厉害之处)为了限制模型复杂度和辅助泛化,论文通过引入两个全连接(FC)层(都是1*1的conv层),即降维层参数为W1,降维比例为r(论文把它设置为16),然后经过一个ReLU,然后是一个参数为W2的升维层。 (优点:1具有更多的非线性,可以更好的拟合通道间复杂的相关性;2减少了参数量和计算量)
最后得到1*1*C的实数数列结合U(原始缝feature map)通过如下公式进行Scale操作得到最终的输出。
公式:
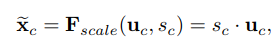
完整的一个SE Block结构:
3、混合域(Image Classification)
简单对比上面两种注意力,空间域是忽略了通道域中的信息,将每个通道中的图片特征同等处理,这种做法会将空间域变换方法局限在原始图片特征提取阶段,应用在神经网络其他层的可解释性不强。而通道域的注意力是对一个通道内的信息直接全局平均池化,而忽略每一个通道内的局部信息,这种做法其实也是比较暴力的行为。所以结合两种思路,就可以设计出混合域的注意力机制模型。
(1)CBAM

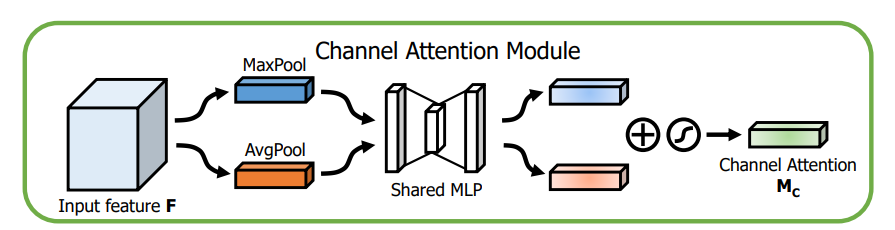
CBAM中的channel attention module和SE block几乎一样,唯一的区别在于多了一次max pooling,中间MLP的参数共享。
(2)Residual attention learning
这种注意力机制是与深度残差网络相关的方法,基本思路是能够将注意力应用到ResNet中,并且使网络能够训练的比较深。
论文中注意力的机制是软注意力基本的加掩码(mask)机制,但是不同的是,这种注意力机制的mask借鉴了残差网络的想法,不只根据当前网络层的信息加上mask,还把上一层的信息传递下来,这样就防止mask之后的信息量过少引起的网络层数不能堆叠很深的问题。
本文中提出的注意力mask,不仅仅只是对空间域或者通道域注意,这种mask可以看作是每一个特征元素(element)的权重。通过给每个特征元素都找到其对应的注意力权重,就可以同时形成了空间域和通道域的注意力机制。
但是值得注意的是:
* 如果你给每一个特征元素都赋予一个mask权重的话,mask之后的信息就会非常少,可能直接就破坏了网络深层的特征信息;
* 另外,如果你可以加上注意力机制之后,残差单元(Residual Unit)的恒等映射(identical mapping)特性会被破坏,从而很难训练。
因此,创新点在于:
残差注意力学习——不仅只把mask之后的特征张量作为下一层的输入,同时也将mask之前的特征张量作为下一层的输入,这时候可以得到的特征更为丰富,从而能够更好的注意关键特征。
模型结构
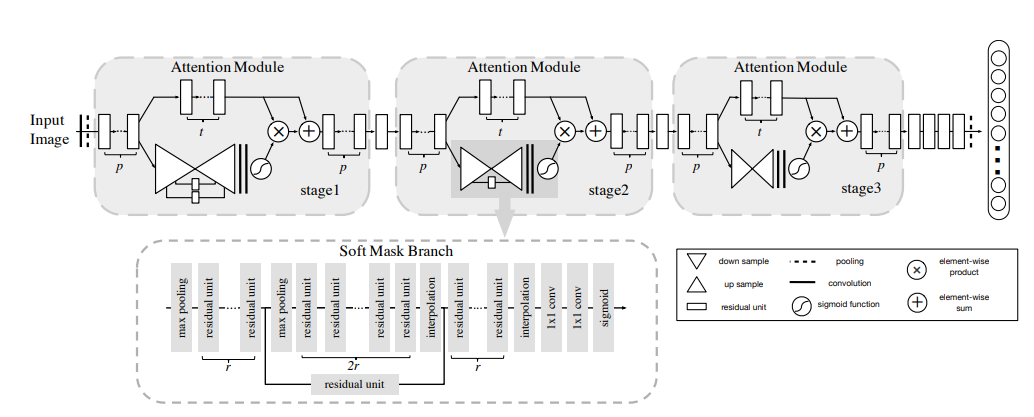
每一个注意力模块可以分成两个分支(看stage2),上面的分支叫主分支(trunk branch),是基本的残差网络(ResNet)的结构。而下面的分支是软掩码分支(soft mask branch),而软掩码分支中包含的主要部分就是残差注意力学习机制。通过下采样(down sampling)和上采样(up sampling),以及残差模块(residual unit),组成了注意力的机制:
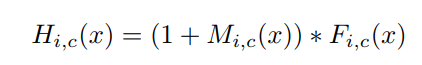
H是注意力模块的输出,F是上方主分支输出的图片张量特征,M是软掩码的注意力参数。这就构成了残差注意力模块,能将图片特征和加强注意力之后的特征一同输入到下一模块中。F函数可以选择不同的函数,就可以得到不同注意力域的结果:
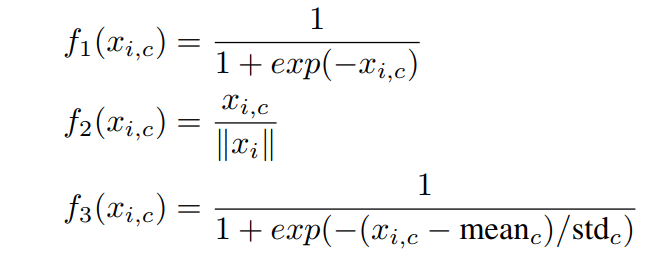
f1是对图片特征张量直接sigmoid激活函数,就是混合域的注意力;
f2是对图片特征张量直接做全局平均池化(global average pooling),所以得到的是通道域的注意力(类比SENet[5]);
f3是求图片特征张量在通道域上的平均值的激活函数,类似于忽略了通道域的信息,从而得到空间域的注意力。
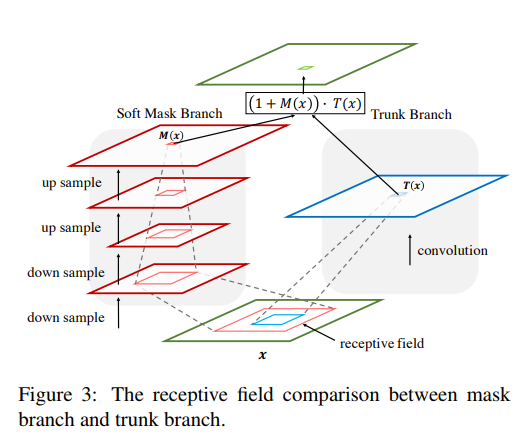
Bottom-up Top-down的结构首先通过一系列的卷积和pooling,逐渐提取高层特征并增大模型的感受野,之前说过高层特征中所激活的Pixel能够反映Attention所在的区域,于是再通过相同数量的up sample将feature map的尺寸放大到与原始输入一样大(这里的upsample通过deconvolution来实现,可以利用bilinear interpolation 也可以利用deconvolution自己来学习参数,可参考FCN中的deconvolution使用方式),这样就将Attention的区域对应到输入的每一个pixel上,我们称之为Attention map。Bottom-up Top-down这种encoder-decoder的结构在图像分割中用的比较多,如FCN,也正好是利用了这种结构相当于一个weakly-supervised的定位任务的学习。
五、待改进
1、CBAM所生成的注意力比较基础,整体结构简单,尽管对结果有提升,但是有限(这里SE Block有同样的问题)
2、多数注意力更加适合想ResNet这样的深层网络,因为其深层特征更能提供有效的语义信息,而注意力本身更多的依然是依靠语义
3、一个有效的注意力需要有效的训练手段,最重要的一个因素是训练attention时使用的loss
六、讨论