TL;DR
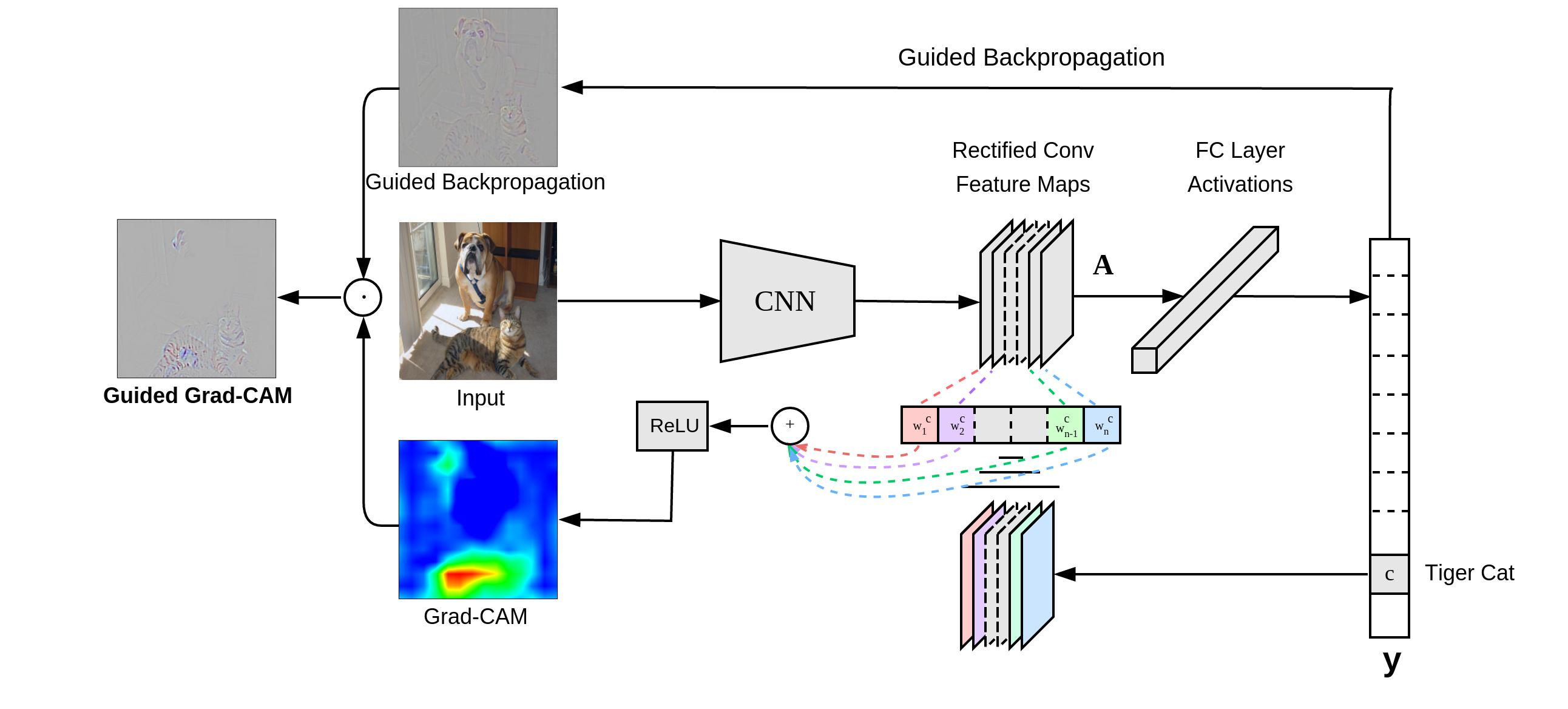
Grad-CAM(Gradient-weighted Class Activation Mapping)可为基于CNN的模型的决策生成”视觉解释“。使用任何目标概念的梯度(例如“狗”甚至是字幕的logits),流入最终的卷积层,以生成一个粗略的局部化图,突出显示了图像中用于预测此概念的区域。
解决的问题
在图像分类模型的背景下,Grad-CAM可视化可以做到:
a)深入了解这些模型的失败模式(表明看似不合理的预测具有合理的解释)
b)在ILSVRC-15弱监督定位任务上胜过先前的方法
c)更忠实于基础模型
d)通过识别数据集偏差来帮助实现模型概括。
对于图像字幕和VQA,Grad-CAM可视化结果显示,即使基于非注意力的模型也可以定位输入。